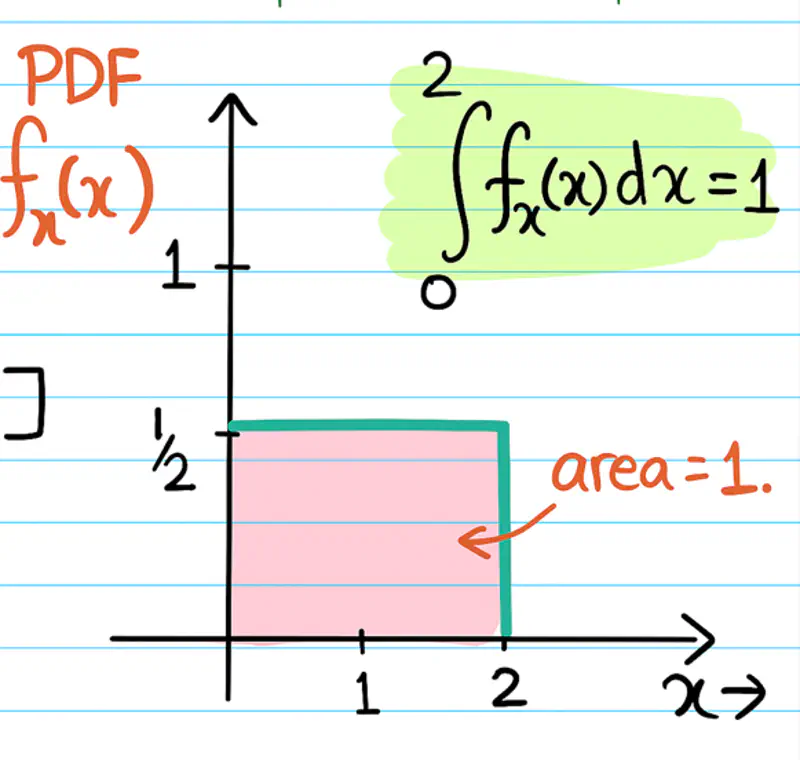
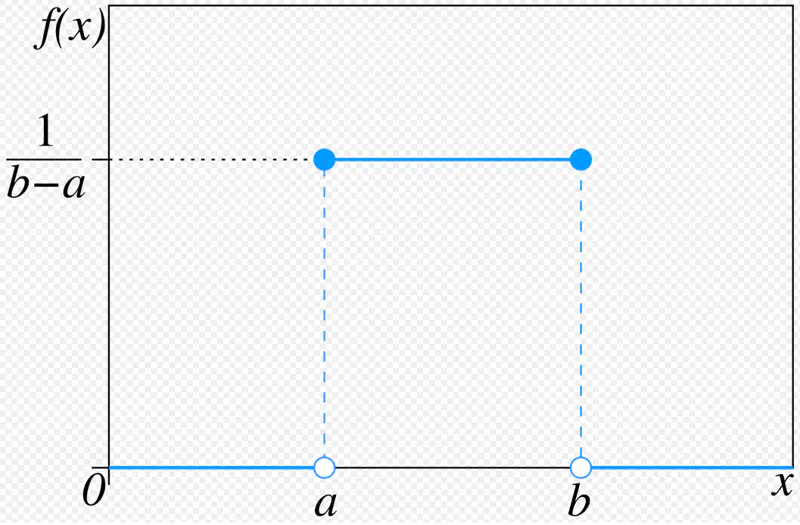
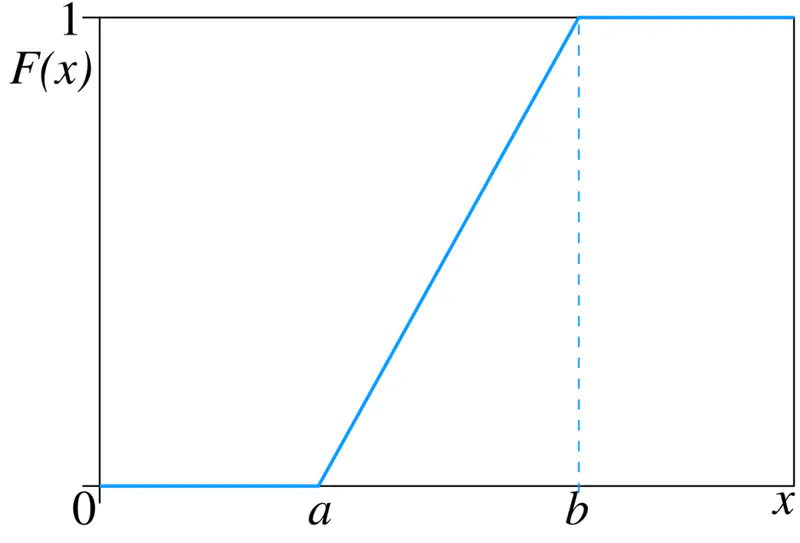
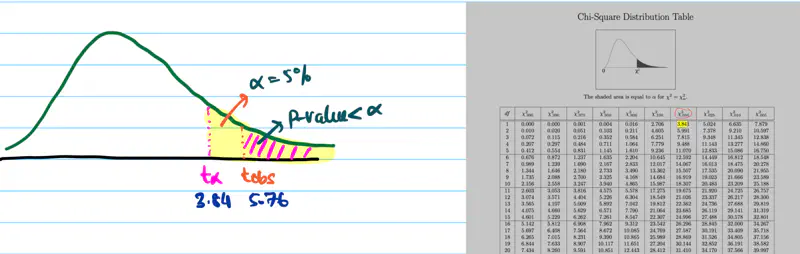To gain knowledge or understanding of a skill, by study, instruction, or experience.
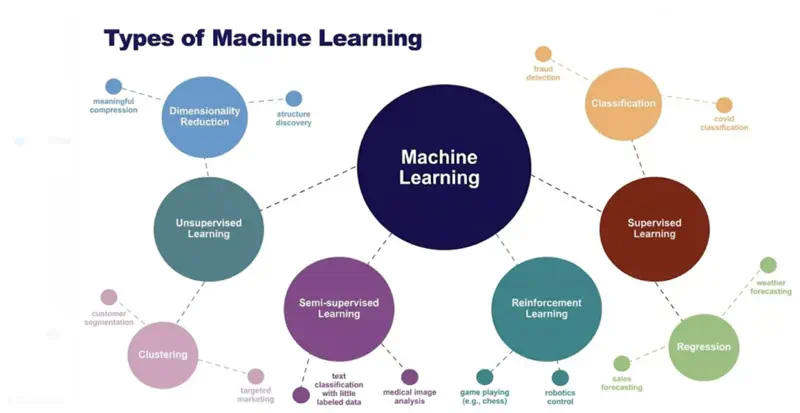
Machine Learning
To teach computers 💻 to learn from data, find patterns 🧮, and make decisions or predictions
without being explicitly programmed for every task, as humans🧍♀️🧍 learn from experience.
Phases of Machine Learning
The machine learning lifecycle ♼ is generally divided into two main stages:
Training Phase
Runtime (Inference) Phase
Training Phase: Where the machine learning model is developed and taught to understand a specific task using a large volume
of historical data.
Runtime (Inference) Phase: Where the fully trained and deployed model is put to practical use in a real-world 🌎 environment, i.e.,
to make predictions on new, unseen data.
Supervised Learning uses labelled data (input-output pairs) to predict outcomes, such as, spam filters.
Regression
Classification
Unsupervised Learning
Unsupervised Learning finds hidden patterns in unlabelled data (like customer segmentation).
Clustering (k-means, hierarchical)
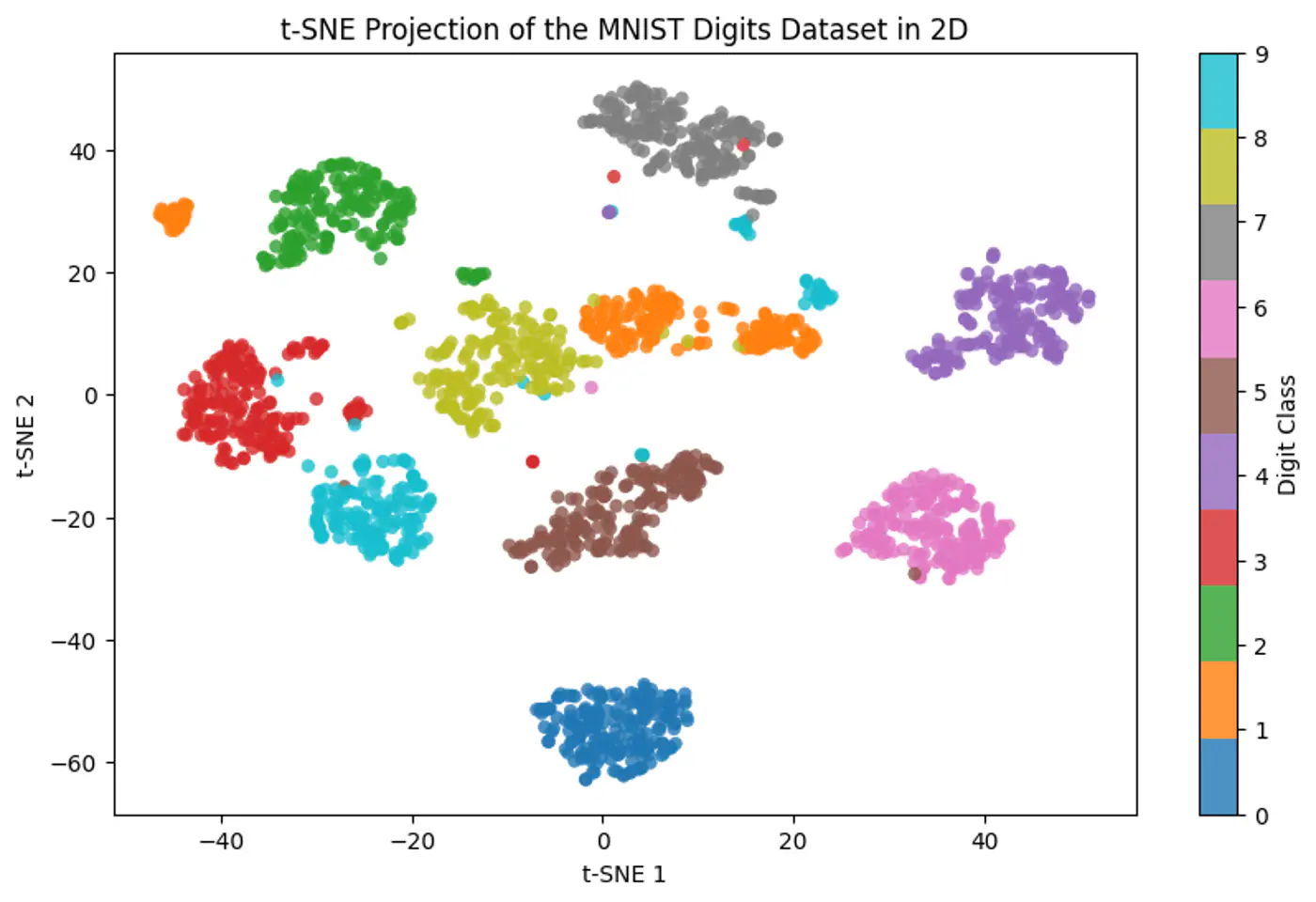
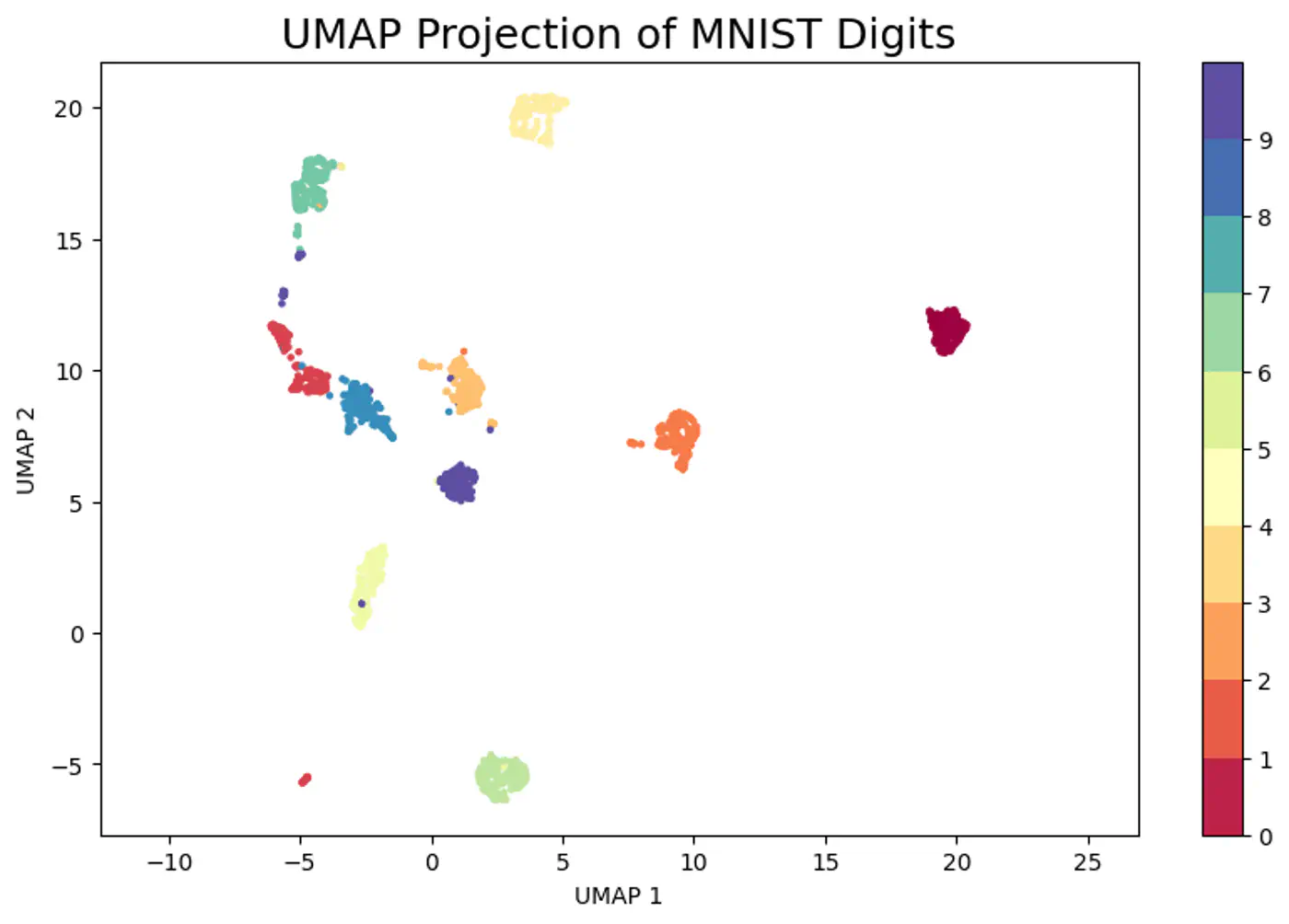
Dimensionality Reduction and Data Visualization (PCA, t-SNE, UMAP)
Semi-Supervised Learning
Semi-Supervised Learning uses a mix of both, leveraging a small amount of labelled data with a large amount of
unlabelled data to improve accuracy.
Pseudo-labeling
Graph-based methods
Types of Semi-Supervised Learning
1. Pseudo-labelling:
A model is initially trained on the available, limited labelled dataset.
This trained model is then used to predict labels for the unlabelled data.These predictions are called ‘pseudo-labels’.
The model is then retrained using both the original labelled data and the newly pseudo-labelled data.
Benefit: It effectively expands the training data by assigning labels to previously unlabelled examples,
allowing the model to learn from a larger dataset.
2. Graph-based methods:
Data points (both labelled and unlabelled) are represented as nodes in a graph.
Edges are established between nodes based on their similarity or proximity in the feature space.The weight of an edge often reflects the degree of similarity.
The core principle is that similar data points should have similar labels.This assumption is propagated through the graph, effectively ‘spreading’ the labels from the labelled nodes to the unlabelled nodes based on the graph structure.
Various algorithms, such as label propagation or graph neural networks (GNNs), can be employed to infer the labels of unlabelled nodes.
Benefit: These methods are particularly useful when the data naturally exhibits a graph-like structure or when local
neighborhood information is crucial for classification.
Reinforcement Learning
Agent learns to make optimal decisions by interacting with an environment, receiving rewards (positive feedback)
or penalties (negative feedback) for its actions.
Mimic human trial-and-error learning to achieve a goal 🎯.
Key Components of Reinforcement Learning
Agent: The learning entity that makes decisions and takes actions within the environment.
Environment: The external system with which the agent interacts.It defines the rules, states,
and the consequences of the agent’s actions.
State: A specific configuration or situation of the environment at a given point in time.
Action: A move or decision made by the agent in a particular state.
Reward: A numerical signal received by the agent from the environment, indicating the desirability of an action taken
in a specific state. Positive rewards encourage certain behaviors, while negative rewards (penalties) discourage them.
Policy: The strategy or mapping that defines which action the agent should take in each state to maximize long-term rewards 💰.
How Reinforcement Learning Works ?
Exploration: The agent tries out new actions to discover their effects and potentially find better strategies.
Exploitation: The agent utilizes its learned knowledge to choose actions that have yielded high rewards in the past.
Note: The agent continuously balances exploration and exploitation to refine its policy and achieve the optimal behavior.
Large Language Models
Large Language Models (LLMs) are deep learning models that often employ unsupervised learning
techniques during their pre-training phase.
LLMs are trained on massive amounts of raw, unlabelled text data (e.g., books, articles, web pages) to predict the next
word in a sequence or fill in masked words. This process, often called self-supervised learning, allows the model to learn grammar, syntax, semantics,
and general world knowledge by identifying statistical relationships within the text.
LLMs generally also undergo supervised fine-tuning (SFT) for specific tasks, where they are trained on
labeled datasets to improve performance on those tasks.
Reinforcement Learning from Human Feedback (RLHF) allows LLMs to learn from human judgment,
enabling them to generate more nuanced, context-aware, and ethically aligned outputs that better meet human expectations.
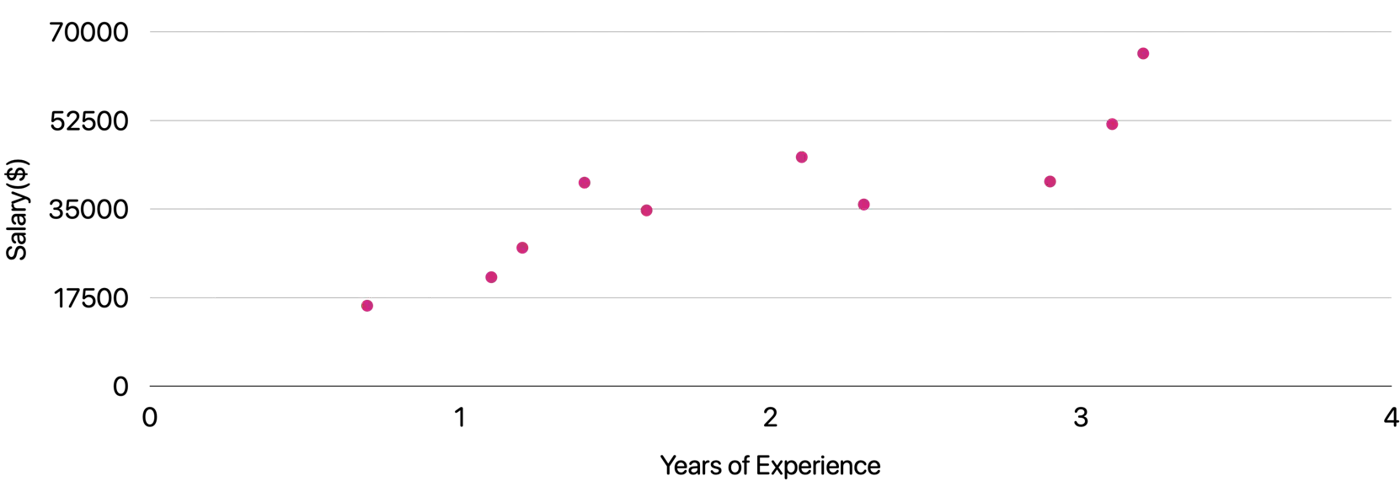
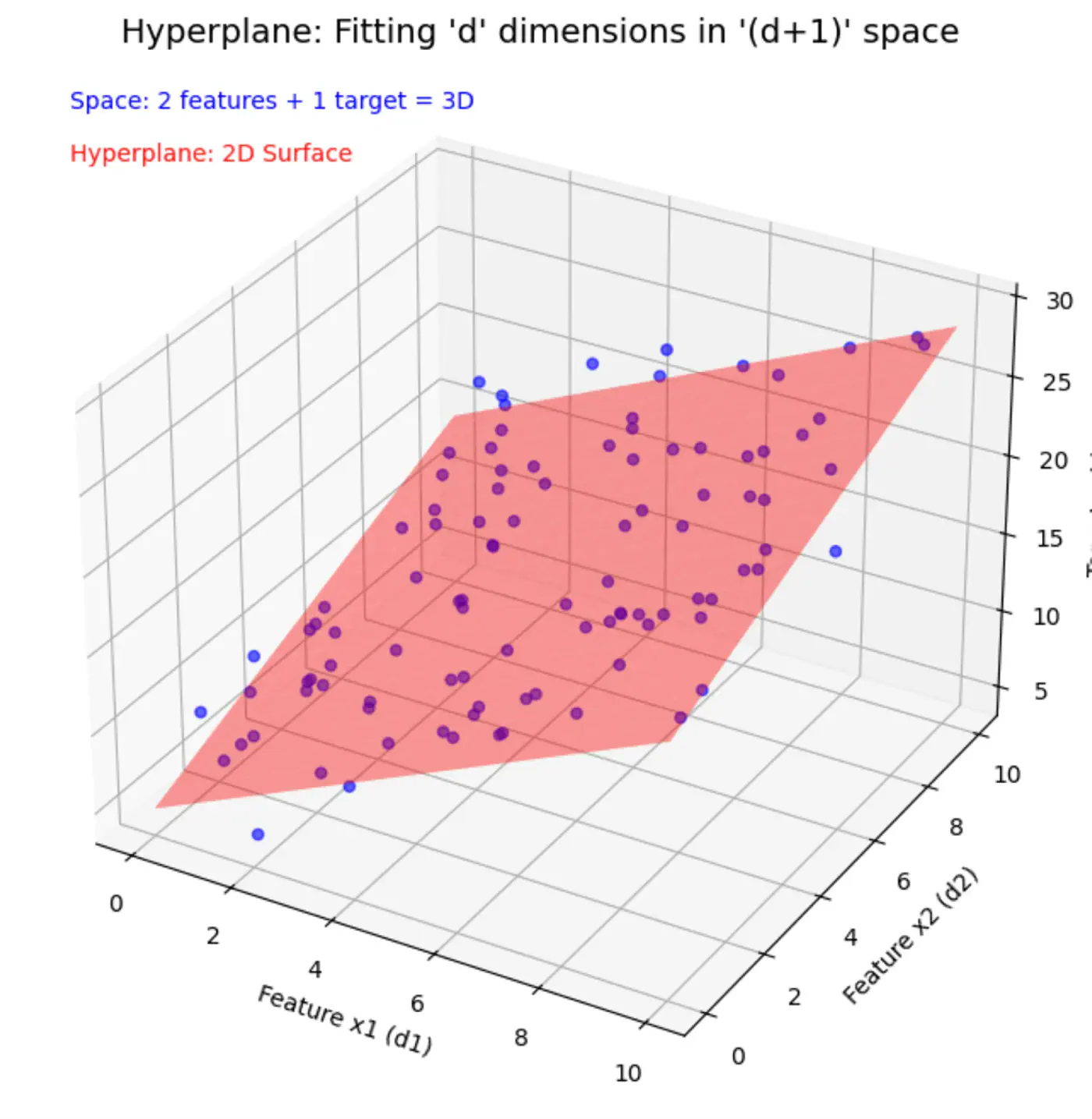
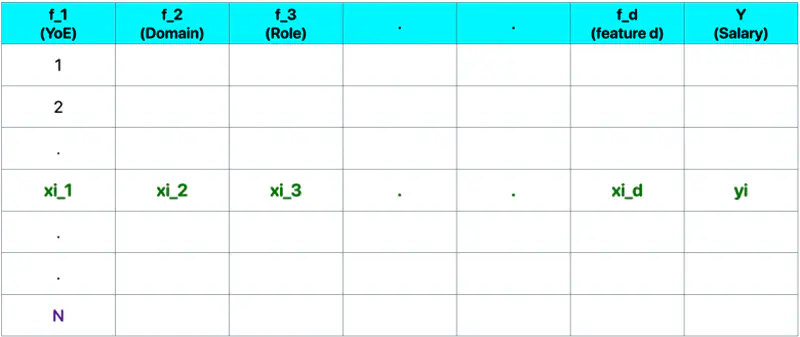
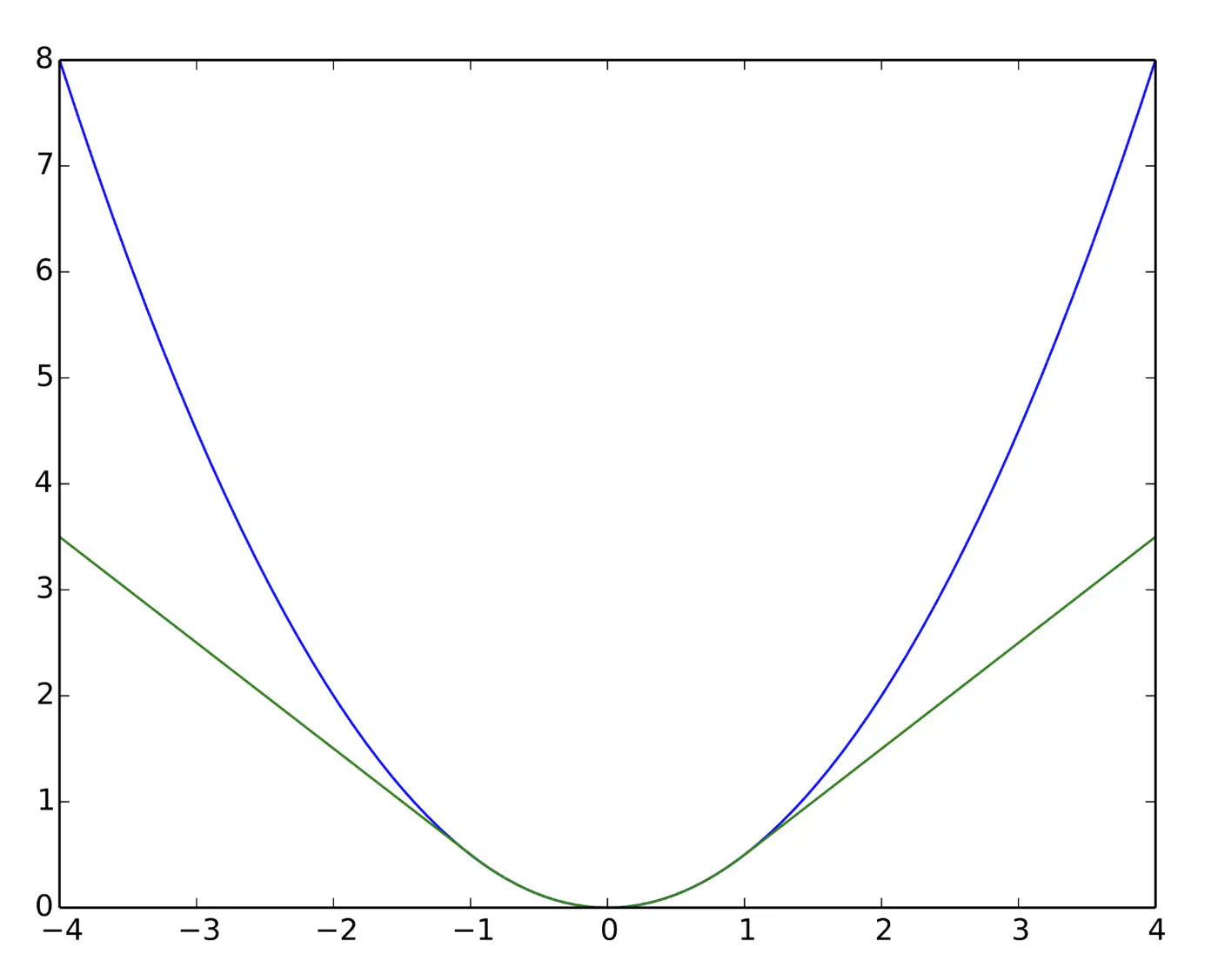
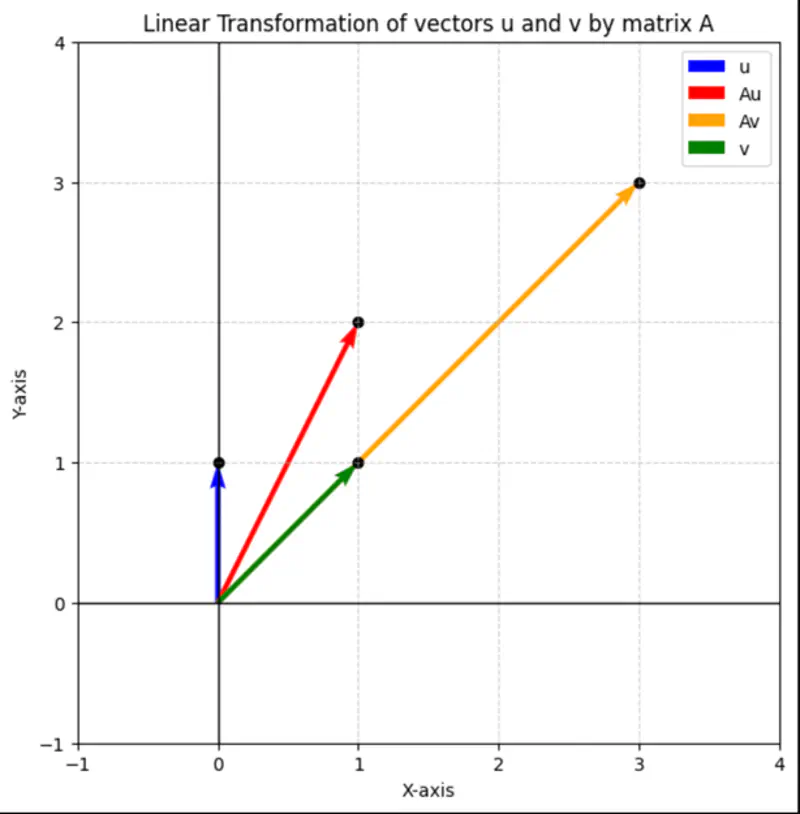
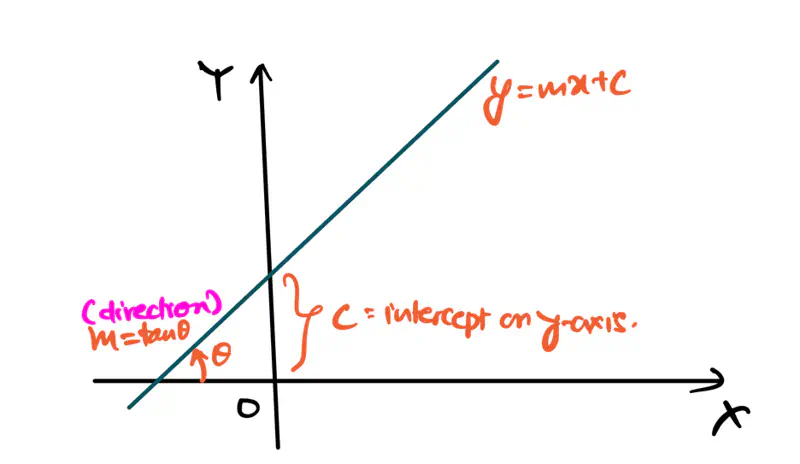
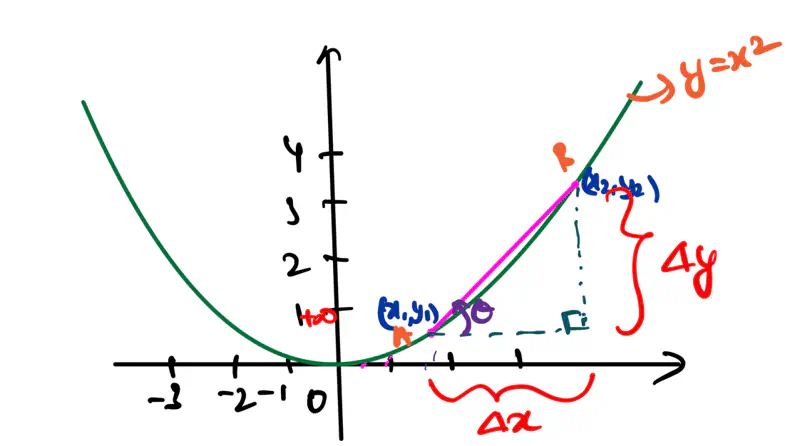
Here, ‘y’ is expressed as a linear combination of parameters - \( w_0, w_1, w_2, \dots, w_n \) Hence - Linear means the model is ‘linear’ with respect to its parameters NOT the variables. Read more about Hyperplane
where, \(x_3 = x_1^2 ~ and ~ x_4 = x_2^3 \) \(x_3 ~ and ~ x_4 \) are just 2 new (polynomial) variables. And, ‘y’ is still a linear combination of parameters: \(w_0, w_1, \dots w_4\)
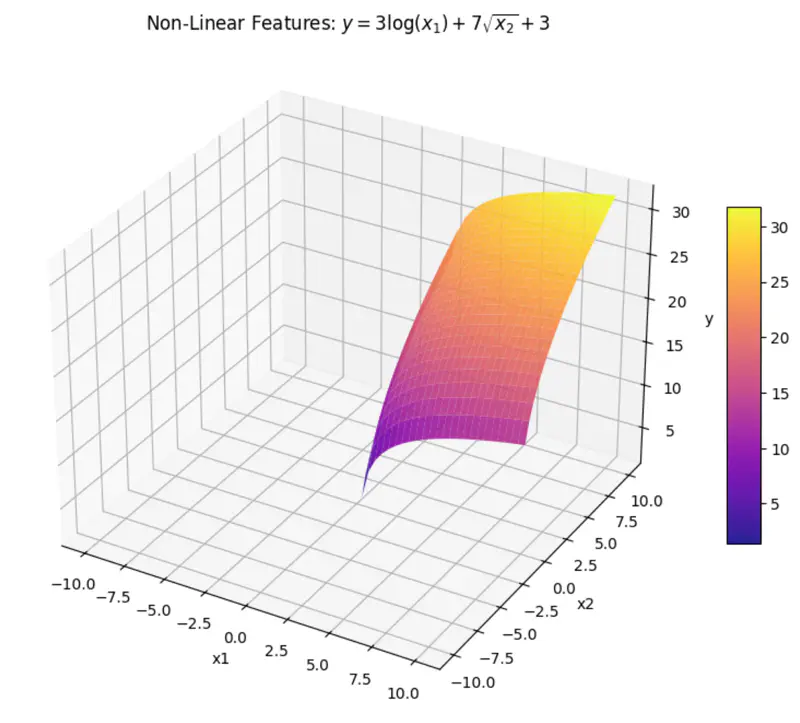
Non-Linear Features ✅
\[ y = w_1log(x) + w_2\sqrt{x}+ w_0 \]
can be rewritten as:
\[y = w_1x_1 + w_2x_2 + w_0\]
where, \(x_1 = log(x) ~ and ~ x_2 = \sqrt{x} \) \(x_1 ~ and ~ x_2 \) are are transformations of variable \(x\). And, ‘y’ is still a linear combination of parameters: \(w_0, w_1, ~and~ w_2\)
Non-Linear Parameters ❌
\[ y = x_1^{w_1} + x_2^{w_2} + w_0 \]
Even if we take log, we get:
\[log(y) = w_1log(x_1) + w_2log(x_2) + log(w_0)\]
here, \(log(w_0) \) parameter is NOT linear.
Importance of Linearity
Linearity in parameters allows to use Ordinary Least Squares (OLS) to find the best-fit coefficients by solving
a set of linear equations, making estimation straightforward.
What is the meaning of “Regression” in Linear Regression ?
Regression = Going Back
Regression has a very specific historical origin that is different from its current statistical meaning.
Sir Francis Galton (19th century), cousin of Charles Darwin, coined 🪙 this term.
Observation: Galton observed that - the children 👶 of unusually tall ⬆️ parents 🧑🧑🧒🧒,
tended to be shorter ⬇️ than their parents 🧑🧑🧒🧒, and children 👶 of unusually short ⬇️ parents 🧑🧑🧒🧒,
tended to be taller ⬆️ than their parents 🧑🧑🧒🧒.
Galton named this biological tendency - ‘regression towards mediocrity/mean’.
Galton used method of least squares to model this relationship, by fitting a line to the data 📊.
Regression = Fitting a Line Over time ⏳, the name ‘regression’ got permanently attached to the method of fitting line to the data 📊.
Today in statistics and machine learning, ‘regression’universally refers to the method of finding the ‘line of best fit’ for a set of data points, NOT the concept of ‘regressing towards the mean’.
Note: \(\frac{\partial{(a^T\mathbf{x})}}{\partial{\mathbf{x}}} = a\) and
\(\frac{\partial{(\mathbf{x}^TA\mathbf{x})}}{\partial{\mathbf{x}}} = (A + A^T)\mathbf{x}\)
This is the closed-form solution of normal equations.
Issues with Normal Equation
Inverse may NOT exist (non-invertible).
Time complexity of calculating the inverse is O(n^3).
Pseudo Inverse
If the inverse does NOT exist then we can use the approximation of the inverse, also called Pseudo Inverse
or Moore Penrose Inverse (\(A^+\)).
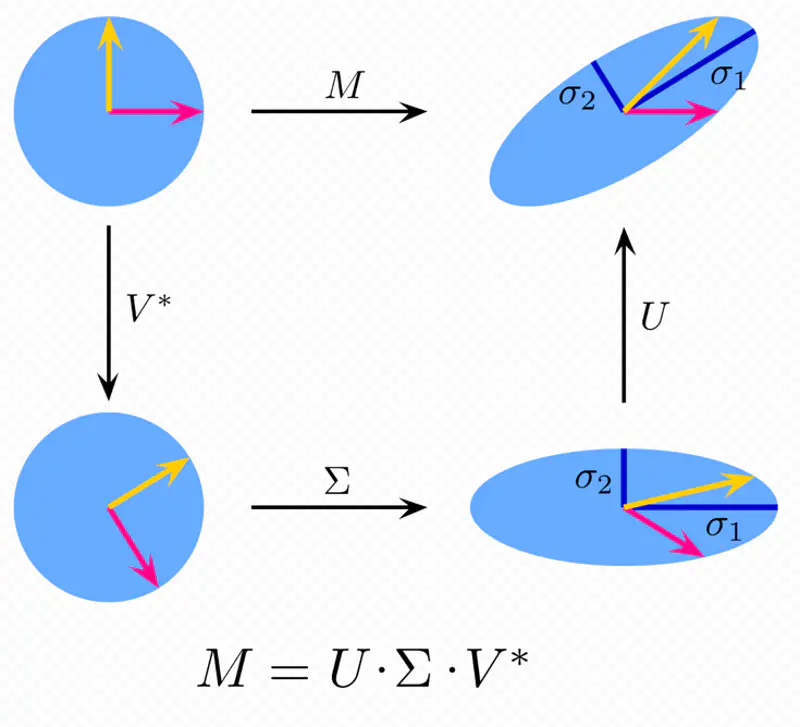
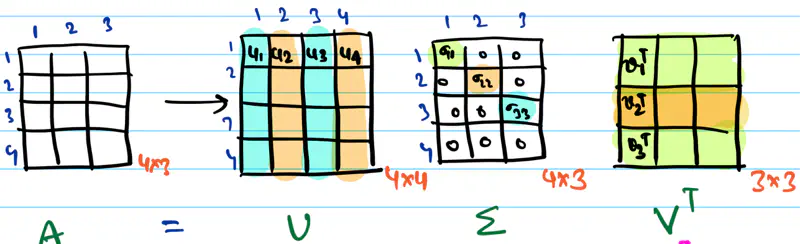
Moore Penrose Inverse ( \(A^+\)) is calculated using Singular Value Decomposition (SVD).
SVD of \(A = U \Sigma V^T\)
Pseudo Inverse \(A^+ = V \Sigma^+ U^T\)
Where, \(\Sigma^+\) is a transpose of \(\Sigma\) with reciprocals of non-zero singular values on its diagonals. e.g:
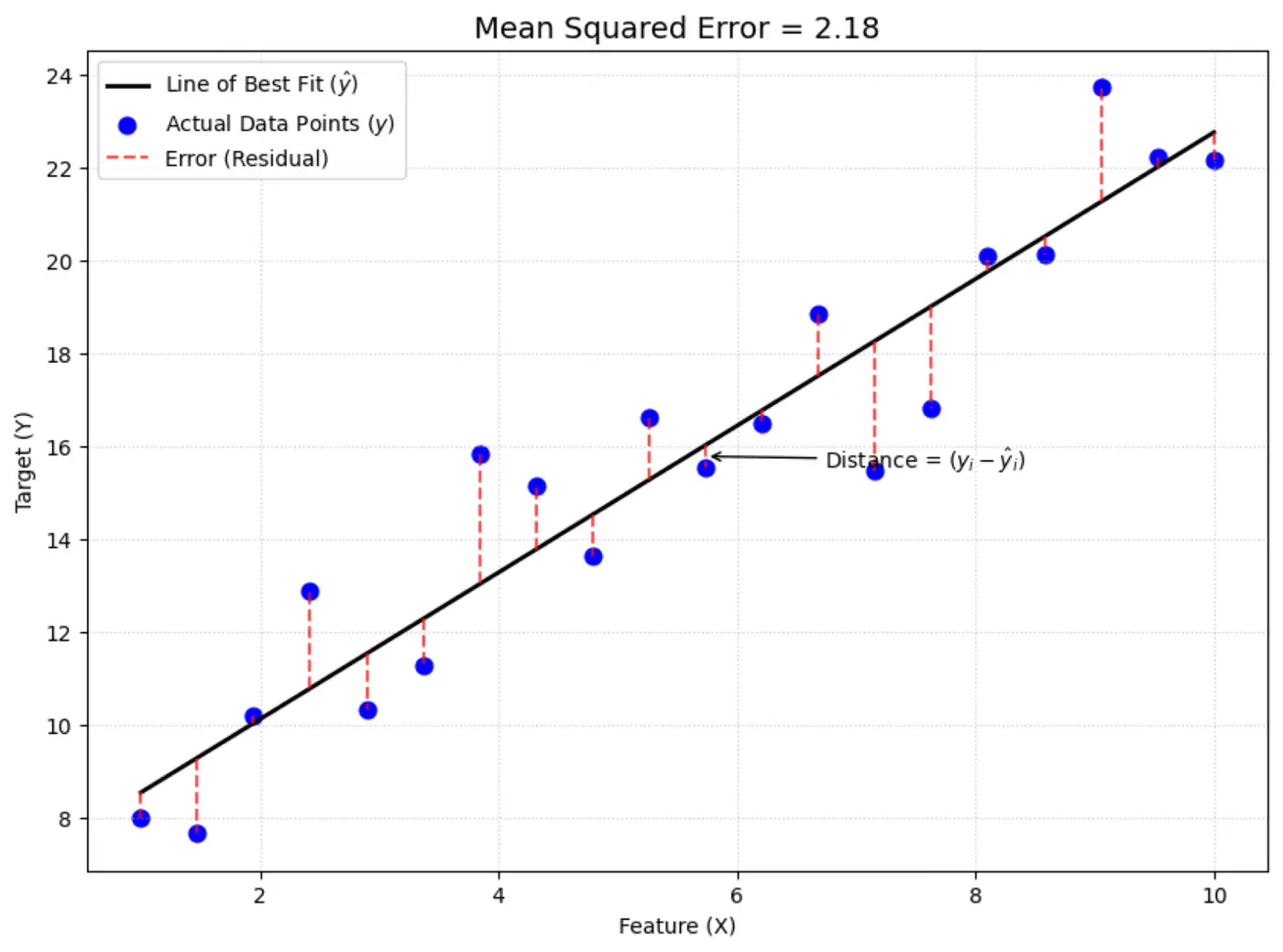
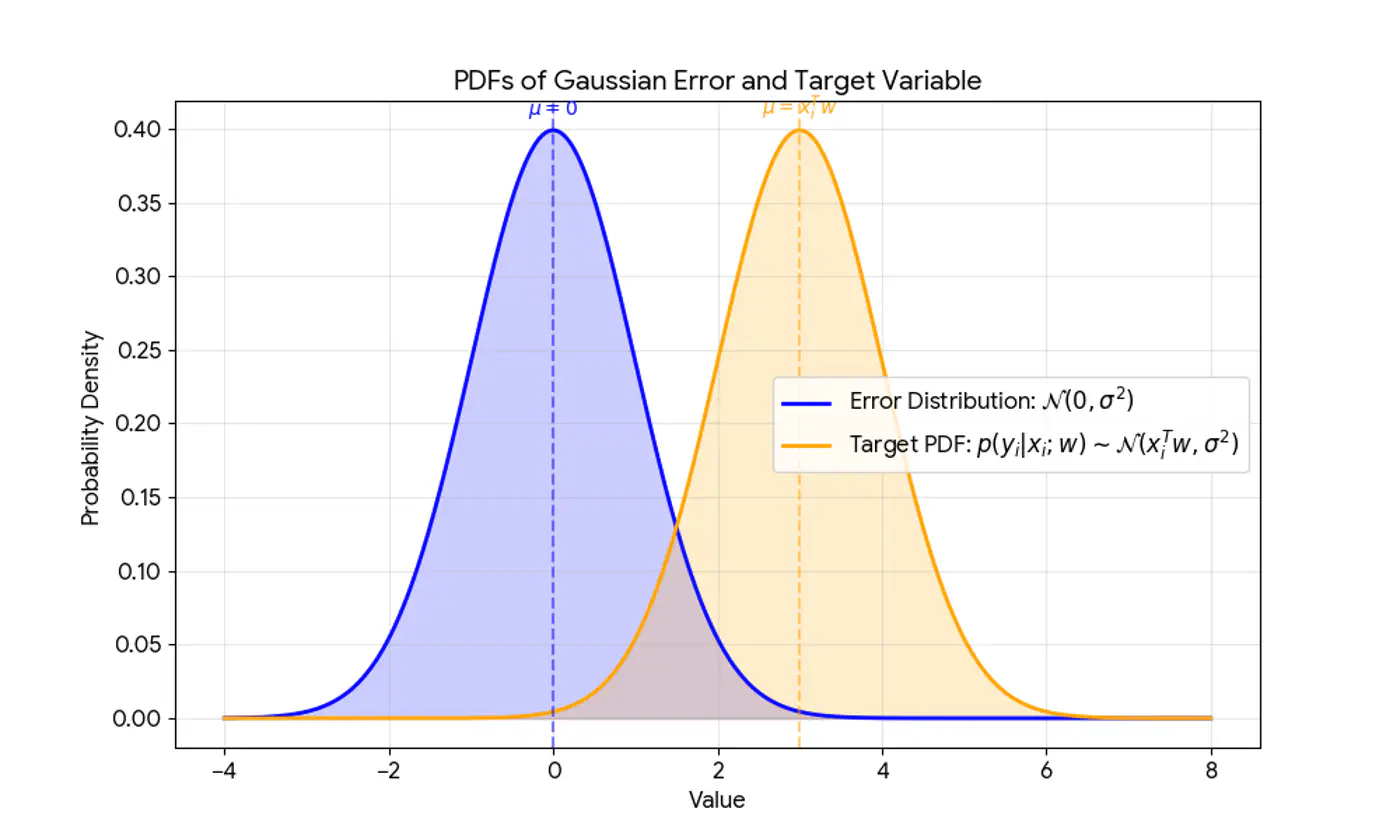
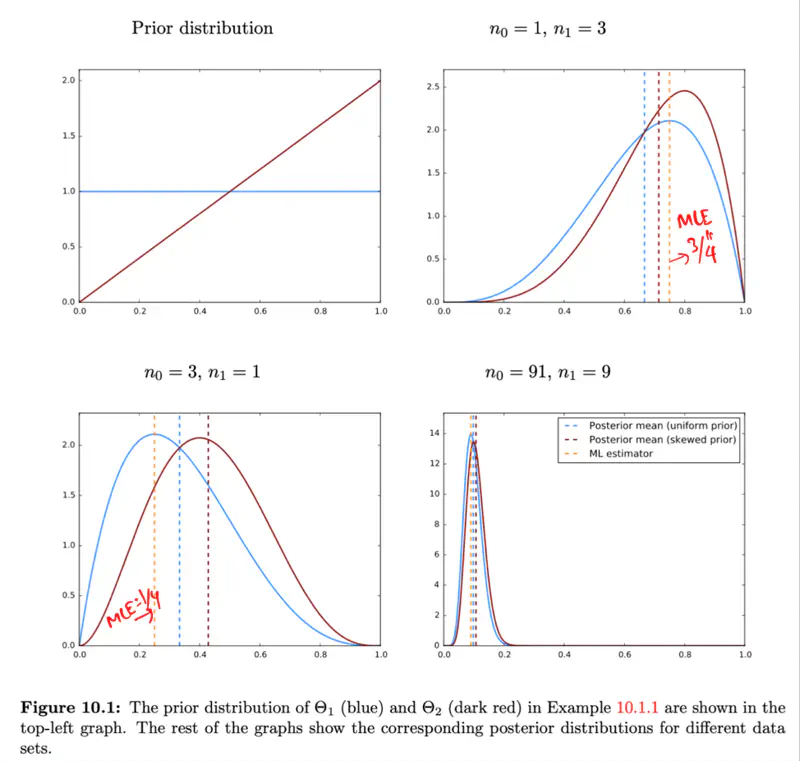
Actual value(\(y_i\)) = Deterministic linear predictor(\(x_i^Tw\)) + Error term(\(\epsilon_i\))
Error Assumptions
Independent and Identically Distributed (I.I.D): Each error term is independent of others.
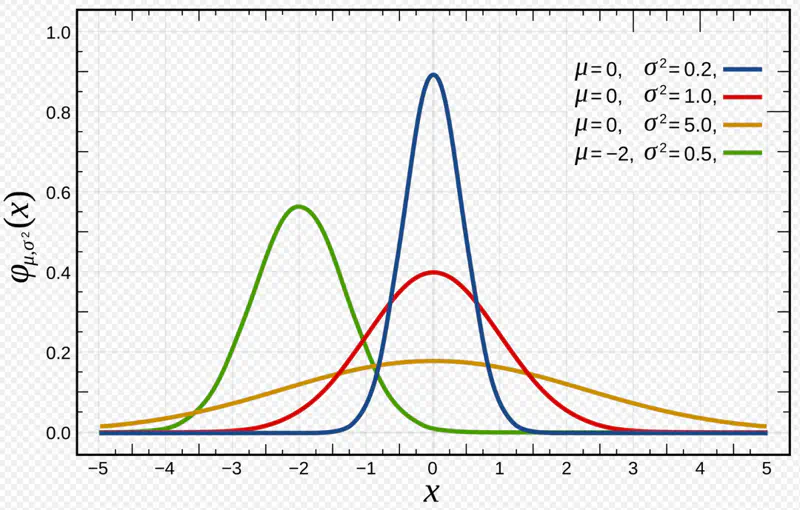
Normal (Gaussian) Distributed: Error follows a normal distribution with mean = 0 and a constant variance, .
This implies that the target variable itself is a random variable, normally distributed around the linear relationship.
\[(y_{i}|x_{i};w)∼N(x_{i}^{T}w,\sigma^{2})\]
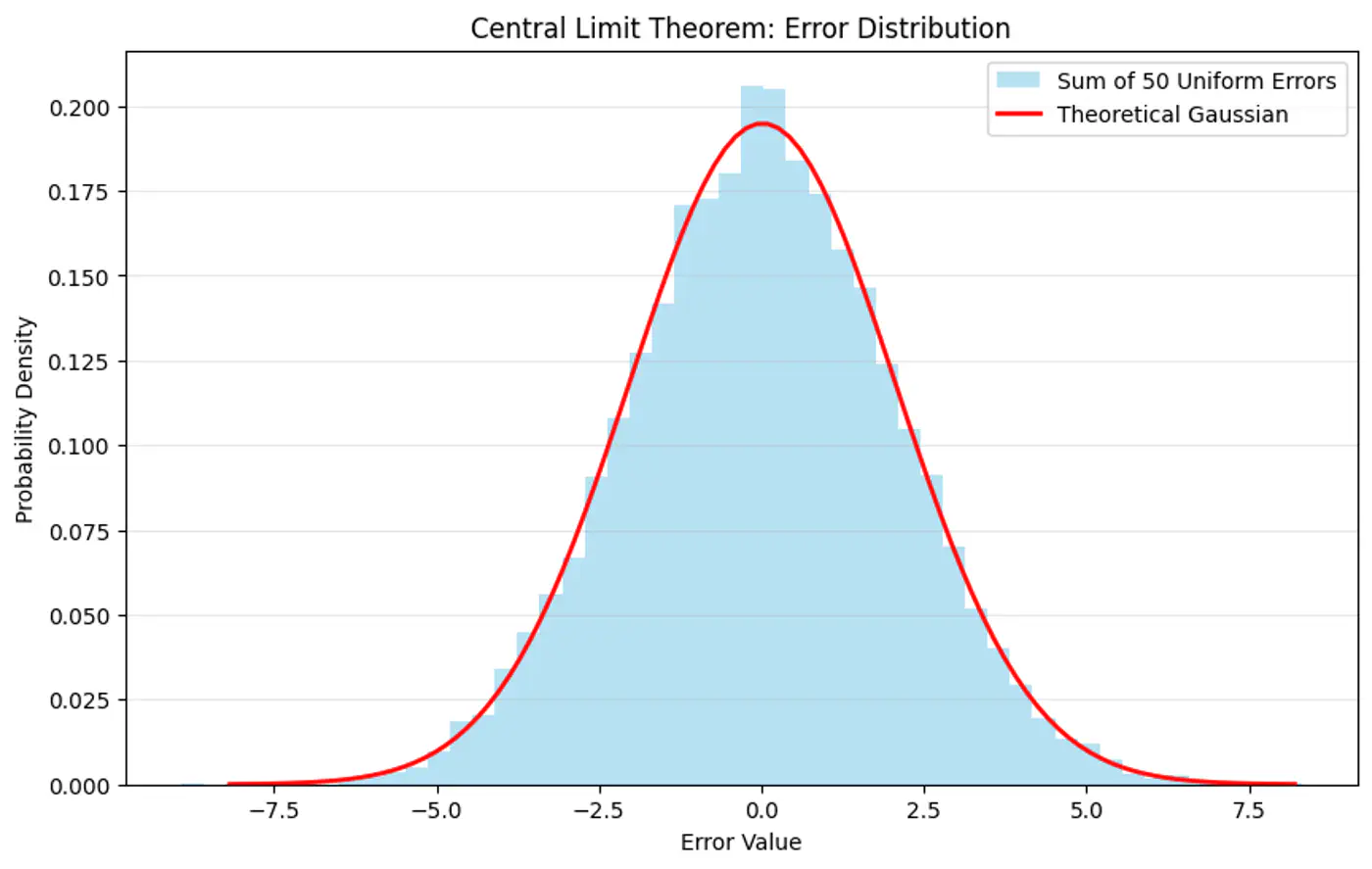
Why is Error terms distribution considered to be Gaussian ?
Central Limit Theorem (CLT) states that for a sequence of I.I.D random variables,
the distribution of the sample mean(sum) approximates to a normal distribution,
regardless of the original population distribution.
Probability Vs Likelihood
Probability (Forward View): Quantifies the chance of observing a specific outcome given a known, fixed model.
Likelihood (Backward/Inverse View): Inverse concept used for inference (working backward from results to causes). It is a function of the parameters and measures how ‘likely’ a specific set of parameters makes the observed data appear.
Maximum Likelihood Estimate (MLE)
‘Find the most plausible explanation for what I see.'
The goal of the probabilistic interpretation is to find the parameters ‘w’ that maximize the probability (likelihood) of observing the given dataset.
Maximizing the log-likelihood is equivalent to minimizing the sum of squared errors, which is the exact
objective of the ordinary least squares (OLS) method.
Note: The 1/2 term is included simply to make the derivative cleaner (it cancels out the 2 from the square).
Issues with Normal Equation
Normal Equation (Closed-form solution) jumps straight to the optimal point in one step.
\[w=(X^{T}X)^{-1}X^{T}y\]
But it is not always feasible and computationally expensive 💰(due to inverse calculation 🧮)
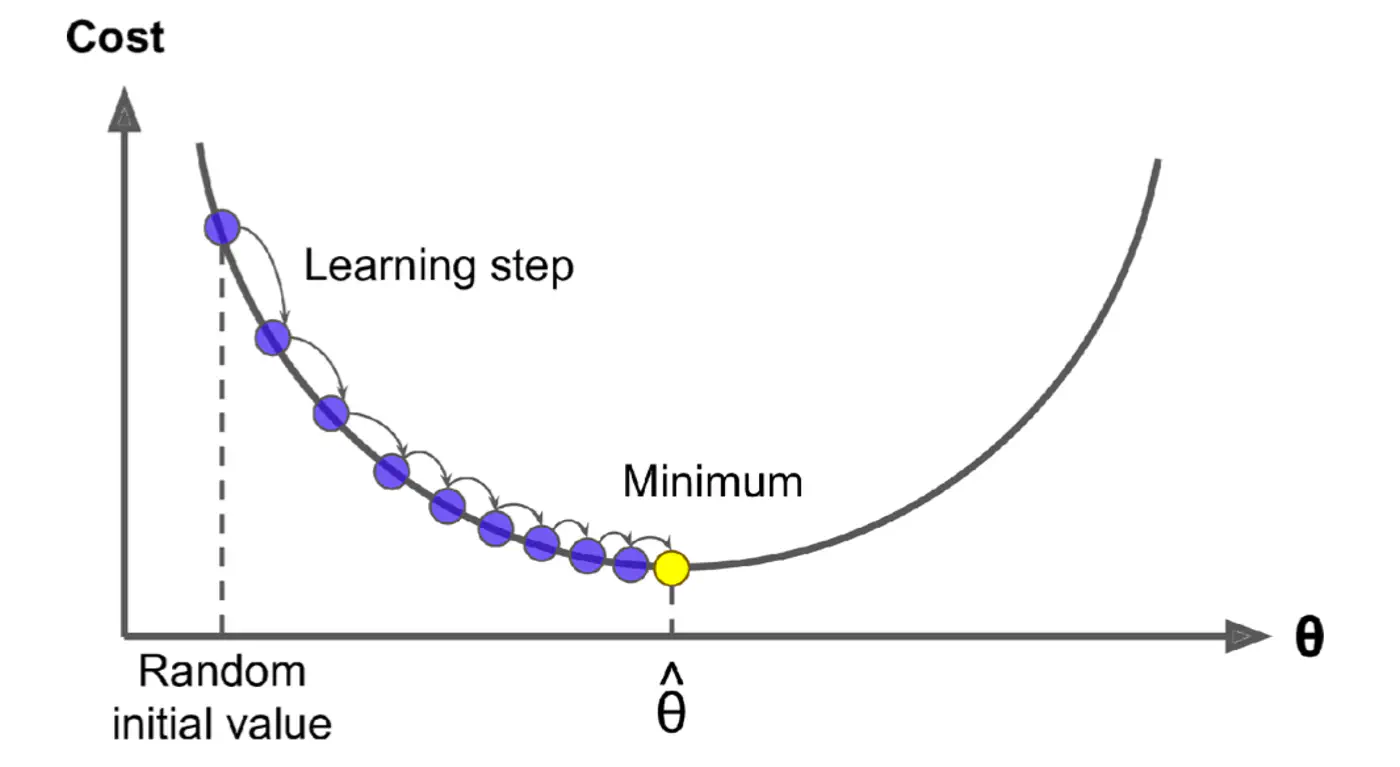
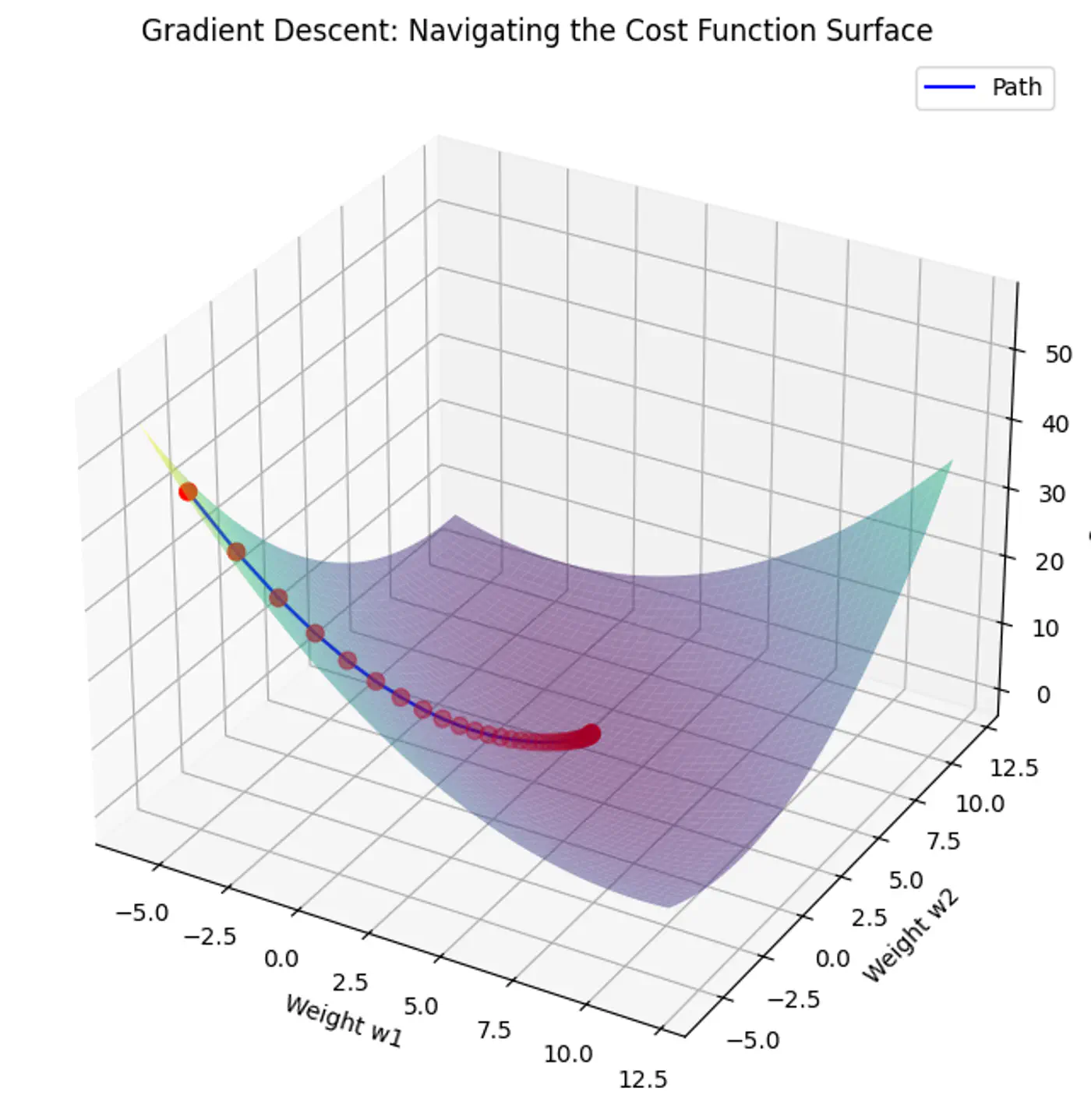
Gradient Descent 🎢
An iterative optimization algorithm slowly nudges parameters ‘w’ towards a value that minimize the cost💰 function.
Algorithm ⚙️
Initialize the weights/parameters with random values.
Calculate the gradient of the cost function at current parameter values.
Update the parameters using the gradient.
\[ w_{new} = w_{old} - \eta \frac{\partial{J(w)}}{\partial{w_{old}}} \]
\( \eta \) = learning rate or step size to take for each parameter update.
Repeat 🔁 steps 2 and 3 iteratively until convergence (to minima).
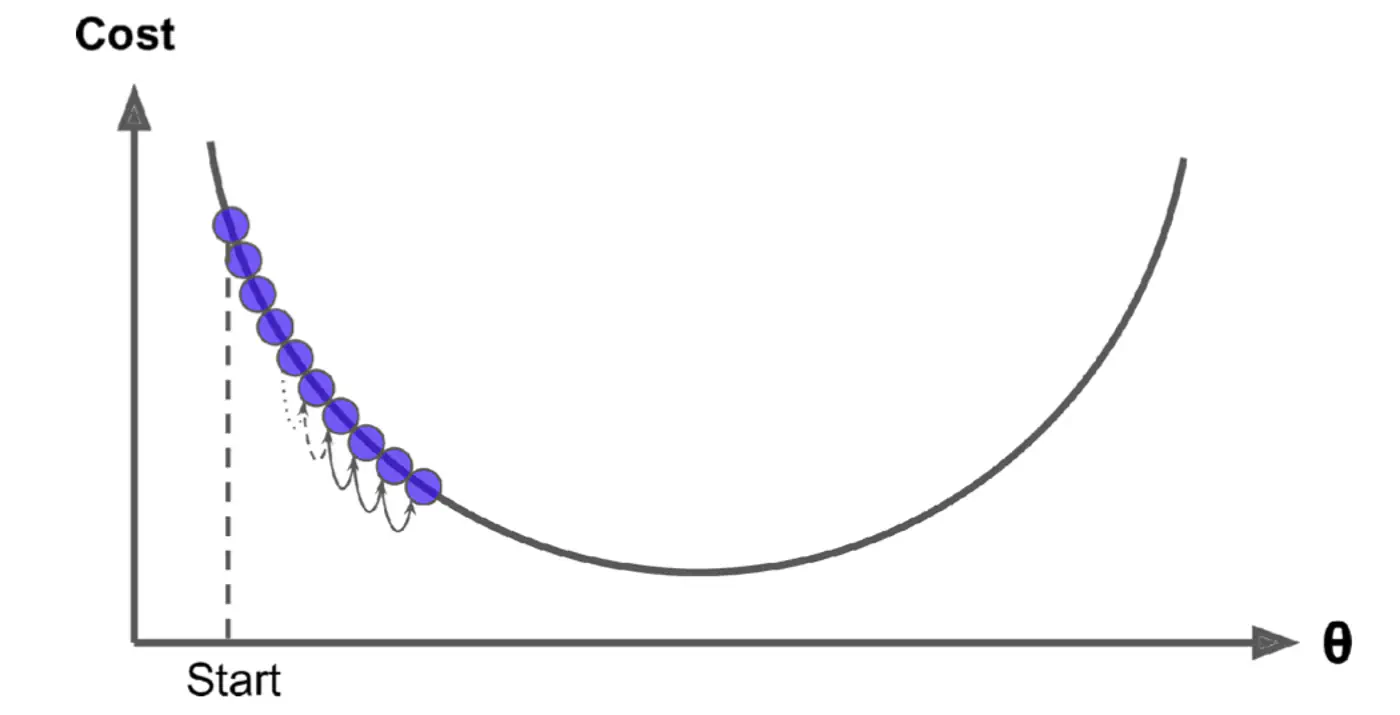
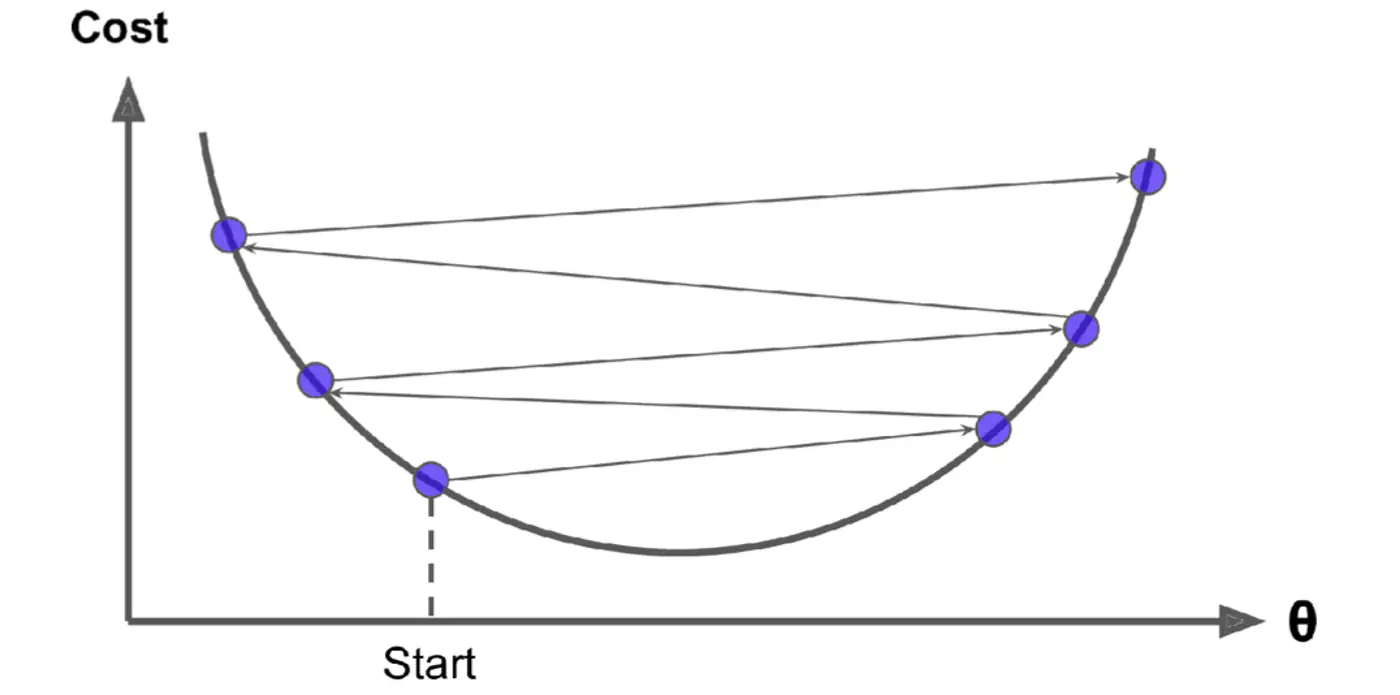
Most important hyper parameter of gradient descent.
Dictates the size of the steps taken down the cost function surface.
Small \(\eta\) ->
Large \(\eta\) ->
Learning Rate Techniques
Learning Rate Schedule: The learning rate is decayed (reduced) over time. Large steps initially and fine-tuning near the minimum, e.g., step decay or exponential decay.
Adaptive Learning Rate Methods: Automatically adjust the learning rate for each parameter ‘w’ based on the history of gradients. Preferred in modern deep learning as they require less manual tuning, e.g., Adagrad, RMSprop, and Adam.
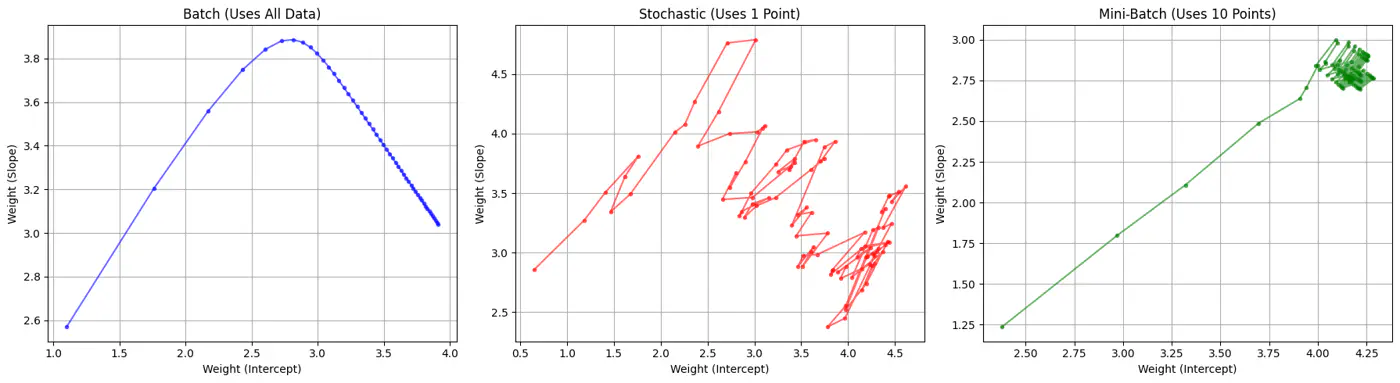
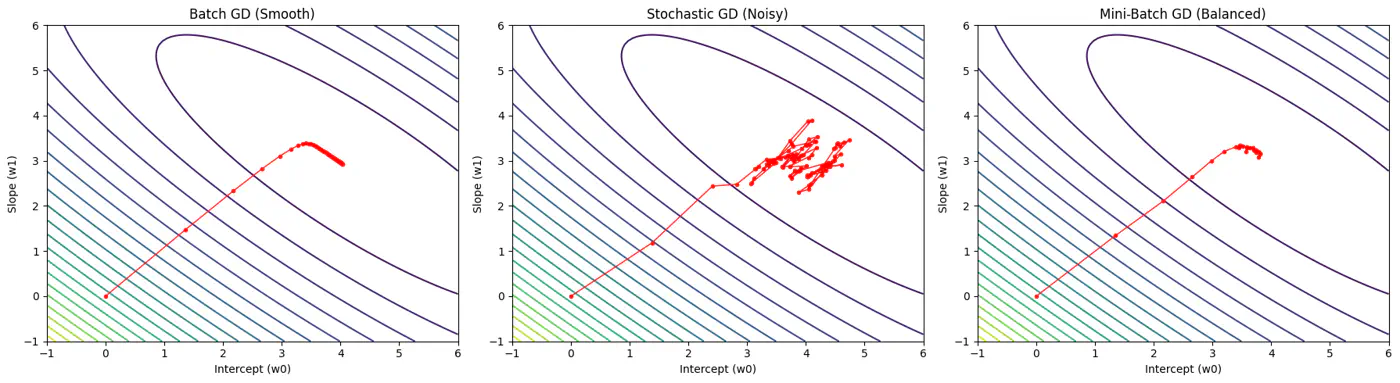
Batch, Stochastic, Mini-Batch are classified by data usage for gradient calculation in each iteration.
Batch Gradient Descent (BGD): Entire Dataset
Stochastic Gradient Descent (SGD): Random Point
Mini-Batch Gradient Descent (MBGD): Subset
Batch Gradient Descent 🎢 (BGD)
Computes the gradient using all the data points in the dataset for parameter update in each iteration.
\[w_{new} = w_{old} - \eta.\text{(average of all ’n’ gradients)}\]
🔑Key Points:
Slow 🐢 steps towards convergence, i.e, TC = O(n).
Smooth, direct path towards minima.
Minimum number of steps/iterations.
Not suitable for large datasets; impractical for Deep Learning, as n = millions/billions.
Stochastic Gradient Descent 🎢 (SGD)
Uses only 1 data point selected randomly from dataset to compute gradient for parameter update in each iteration.
\[w_{new} = w_{old} - \eta.\text{(gradient at any random data point)}\]
🔑Key Points:
Computationally fastest 🐇 per step; TC = O(1).
Highly noisy, zig-zag path to minima.
High variance in gradient estimation makes path to minima volatile, requiring a careful decay of learning rate to ensure convergence to minima.
Mini Batch Gradient Descent 🎢 (MBGD)
Uses small randomly selected subsets of dataset, called mini-batch, (1<k<n), to compute gradient for parameter update in each iteration.
\[w_{new} = w_{old} - \eta.\text{(average gradient of ‘k' data points)}\]
🔑Key Points:
Moderate time ⏰ consumption per step; TC = O(k<n).
Less noisy, and more reliable convergence than stochastic gradient descent.
More efficient and faster than batch gradient descent.
Standard optimization algorithm for Deep Learning.Note: Vectorization on GPUs allows for parallel processing of mini-batches; also GPUs are the reason for the mini-batch size to be a power of 2.
Test Data: Evaluate model performance (Real (final) exam)
Data Leakage
Data leakage occurs when information from the validation or test set is inadvertently used to
train 🏃♂️ the model.
The model ‘cheats’ by learning to exploit information it should not have access to, resulting in artificially
inflated performance metrics during testing 🧪.
Typical Split Ratios
Small datasets(1K-100K): 60/20/20, 70/15/15 or 80/10/10
Large datasets(>1M): 98/1/1 would suffice, as 1% of 1M is still 10K.
Note: There is no fixed rule, its trial and error.
Imbalanced Data
Imbalanced data refers to a dataset where the target classes are represented by an unequal or
highly skewed distribution of samples, such that the majority class significantly outnumbers the minority class.
Stratified Sampling
If there is class imbalance in the dataset, (e.g., 95% class A , 5% class B), a random split might result in the
validation set having 99% class A.
Solution: Use stratified sampling to ensure class proportions are maintained across all splits
(train️/validation/test).
Note: Non-negotiable for imbalanced data.
Time-Series ⏳ Data
In time-series ⏰ data, divide the data chronologically, not randomly, i.e, training data time ⏰ should precede validation data time ⏰.
We always train 🏃♂️ on past data to predict future data.
Do not trust one split of the data; validate across many splits, and average the result to reduce randomness and bias.
Note: Two different splits of the same dataset can give very different validation scores.
Cross-validation
Cross-validation is a statistical resampling technique used to evaluate how well a machine learning model generalizes
to an independent, unseen dataset.
It works by systematically partitioning the available data into multiple subsets, or ‘folds’,
and then training and testing the model on different combinations of these folds.
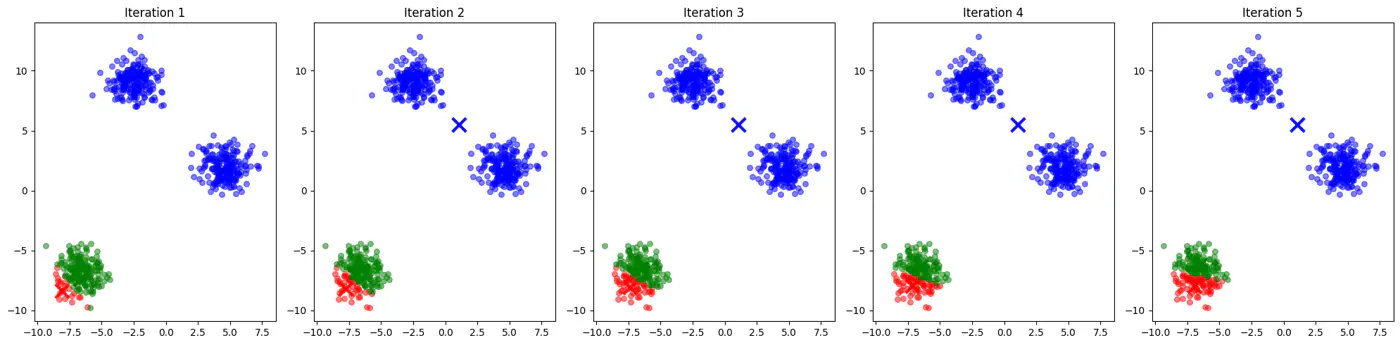
K-Fold Cross-Validation
Leave-One-Out Cross-Validation (LOOCV)
K-Fold Cross-Validation
Shuffle the dataset randomly (except time-series ⏳).
Split data into k equal subsets(folds).
Iterate through each unique fold, using it as the validation set.
Use remaining k-1 fold for training 🏃♂️.
Take an average of the results.Note: Common choice for k=5 or 10.
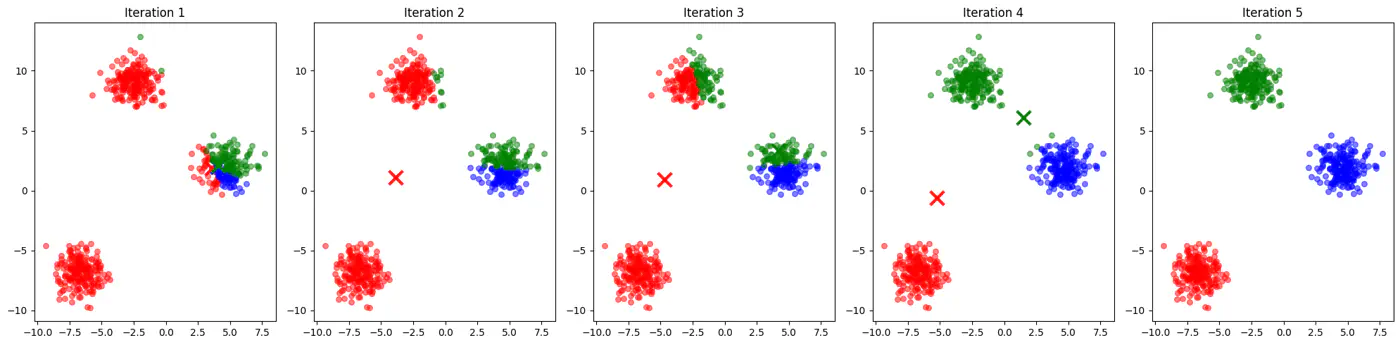
Iteration 1: [V][T][T][T][T]
Iteration 2: [T][V][T][T][T]
Iteration 3: [T][T][V][T][T]
Iteration 4: [T][T][T][V][T]
Iteration 5: [T][T][T][T][V]
Leave-One-Out Cross-Validation (LOOCV)
Model is trained 🏃♂️on all data points except one, and then tested 🧪on that remaining single observation.
LOOCV is an extreme case of k-fold cross-validation, where, k=n (number of data points).
Note: Co-adaptation refers to a phenomenon where neurons in a neural network become highly dependent on each other to detect features, rather than learning independently.
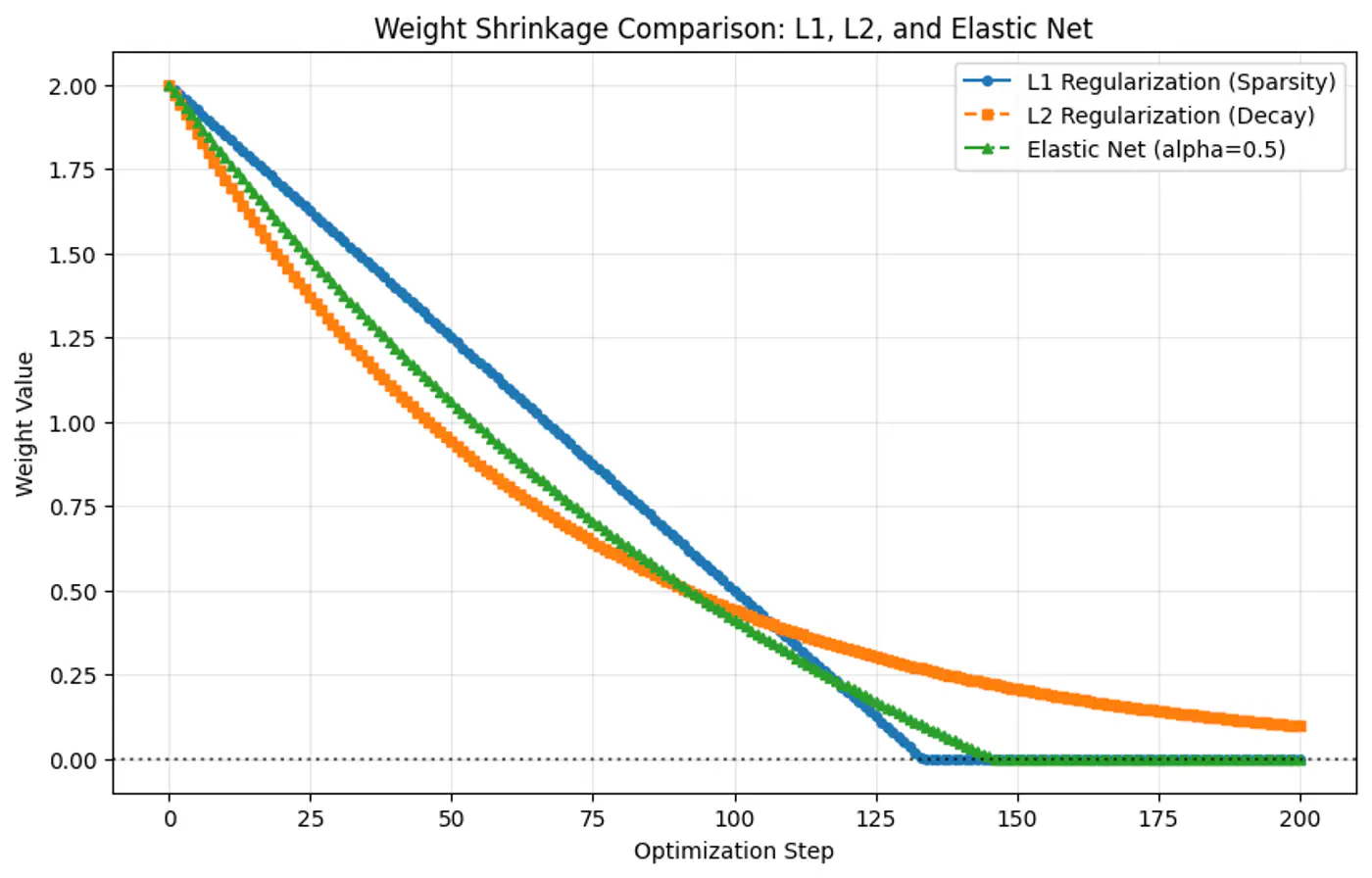
Shrinks some weights exactly to 0, effectively performing feature selection, giving sparse solutions.
For a group of highly co-related features, arbitrarily selects one feature and shrinks others to 0.
Use case: Best when using high-dimensional datasets (d»n) where we suspect many features are irrelevant or redundant, or when model interpretability matters.
Also known as Lasso (Least Absolute Shrinkage and Selection Operator) regression.
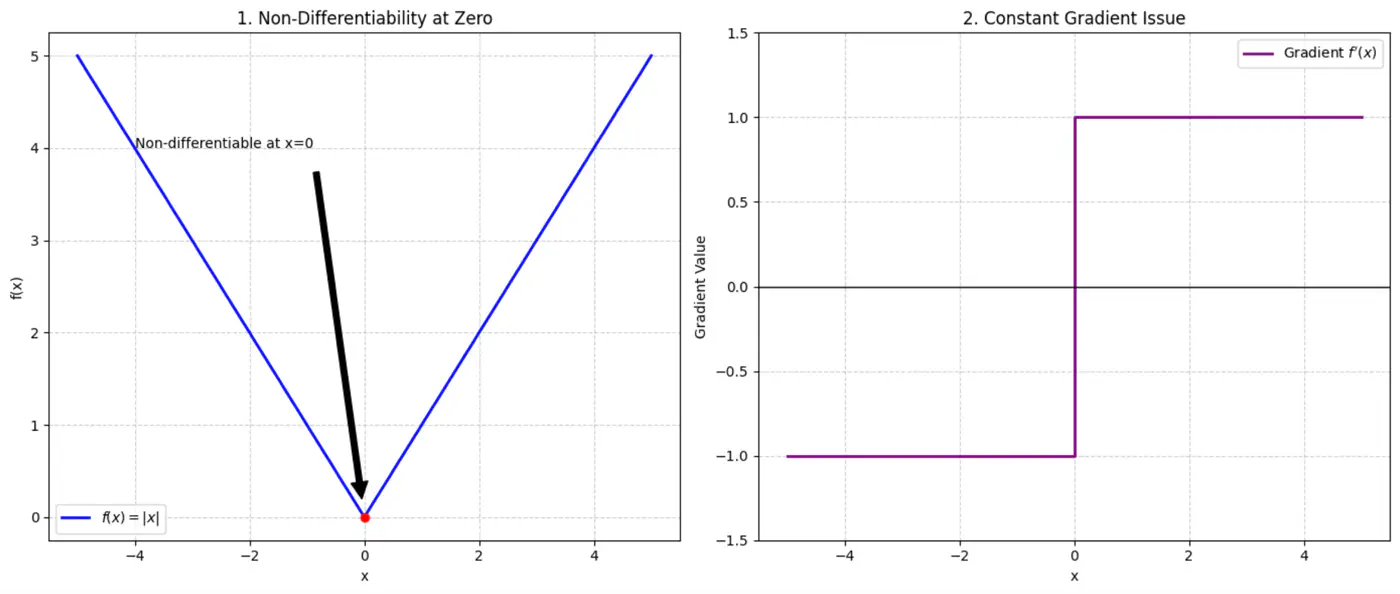
Computational hack: \(\frac{\partial{|w_j|}}{\partial{w_j}} = 0\), since absolute function is not differentiable at 0.
Sparsity(feature-selection) of L1 and stability/grouping effect of L2 regularization.
Use case: Best when we have high dimensional data with correlated features and we want sparse and stable solution.
L1/L2/Elastic Net Regularization Comparison
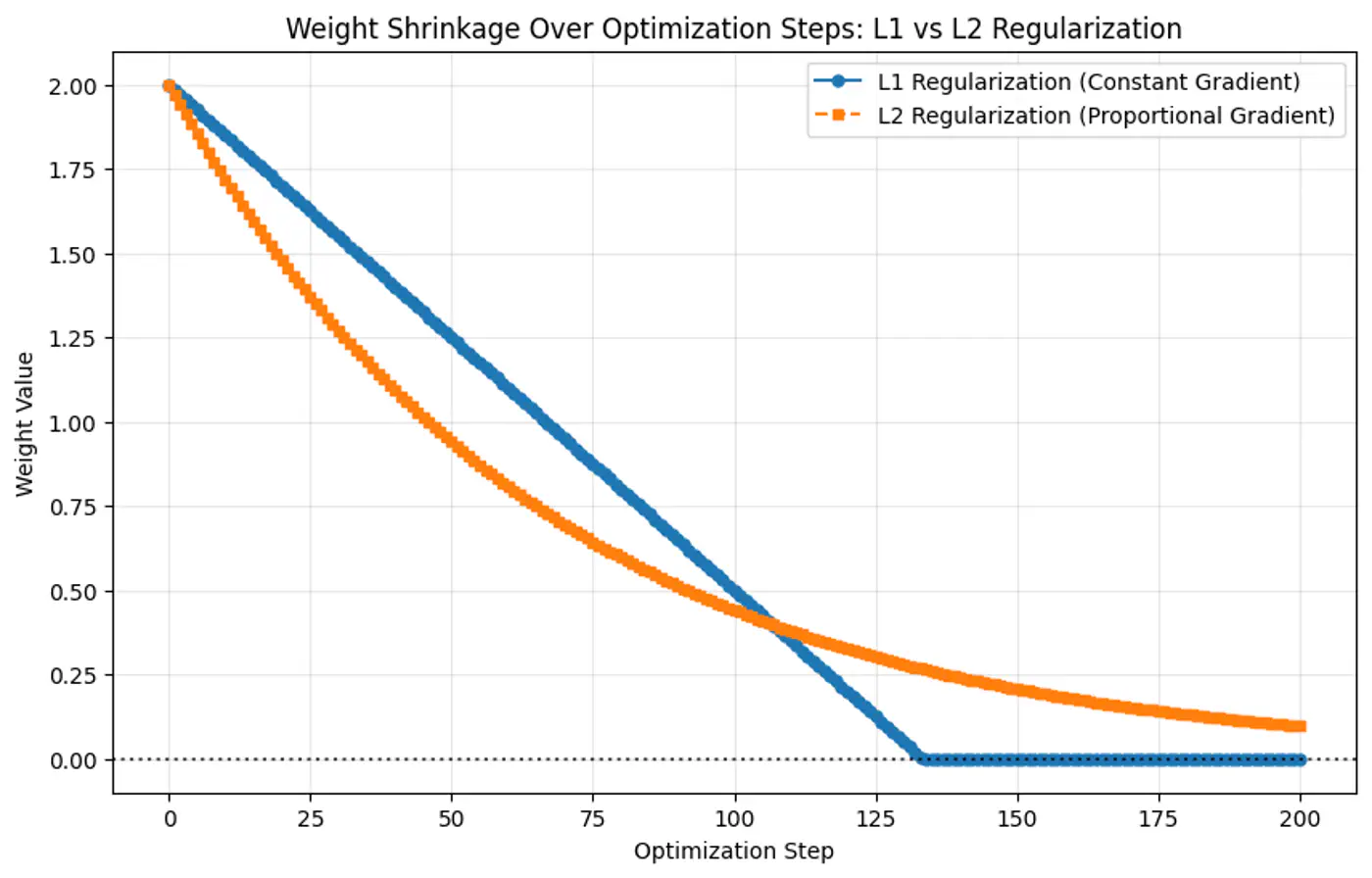
Why weights shrink exactly to 0 in L1 regularization but NOT in L2 regularization ?
Because the gradient of L1 penalty (absolute function) is a constant value, i.e, \(\pm 1\), this means a constant reduction in weight at each step, making it gradually reach to 0 in finite steps.
Whereas, the derivative of L2 penalty is proportional to the weight (\(2w_j\)) and as the weight reaches close to 0, the gradient also becomes very small, this means that the weight will become very close to 0, but not exactly equal to 0.
Differentiable at 0; smooth convergence to minima.
Delta (\(\delta\)) knob(hyper parameter) to control.
\(\delta\) high: MSE
\(\delta\) low: MAE
Note: Tune \(\delta\): MAE, for outliers > \(\delta\); MSE, for small errors < \(\delta\). e.g: = 95th percentile of errors or 1.35\(\sigma\) for standard Gaussian data.
Linear Regression works reliably only when certain key 🔑 assumptions about the data are met.
Linearity
Independence of Errors (No Auto-Correlation)
Homoscedasticity (Equal Variance)
Normality of Errors
No Multicollinearity
No Endogeneity (Target not correlated with the error term)
Linearity
Relationship between features and target 🎯 is linear in parameters.
Note: Polynomial regression is linear regression. \(y=w_0 +w_1x_1+w_2x_2^2 + w_3x_3^3\)
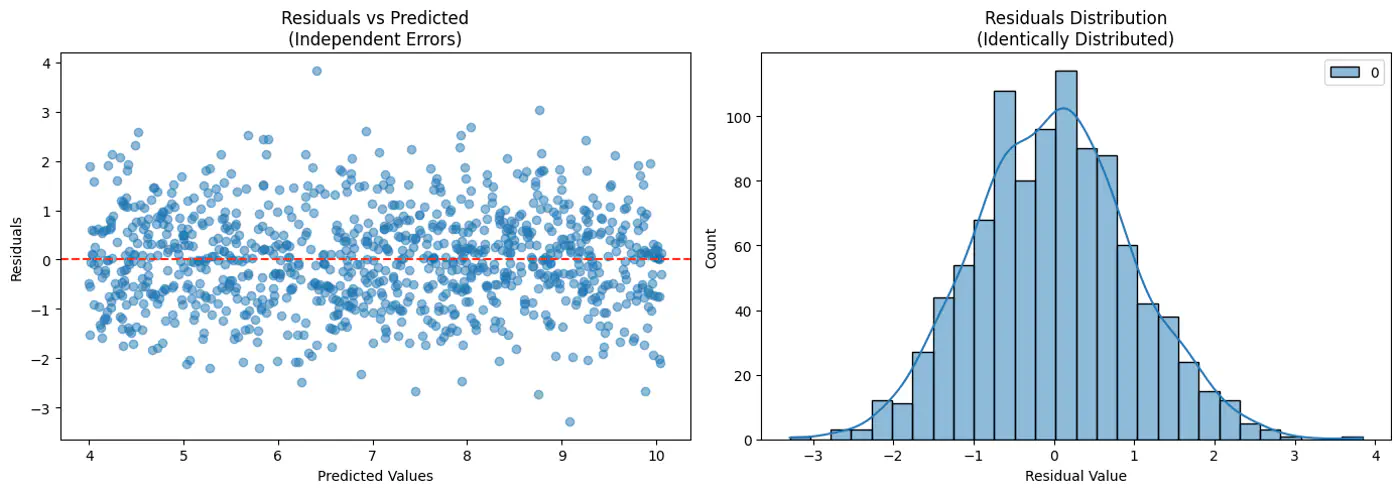
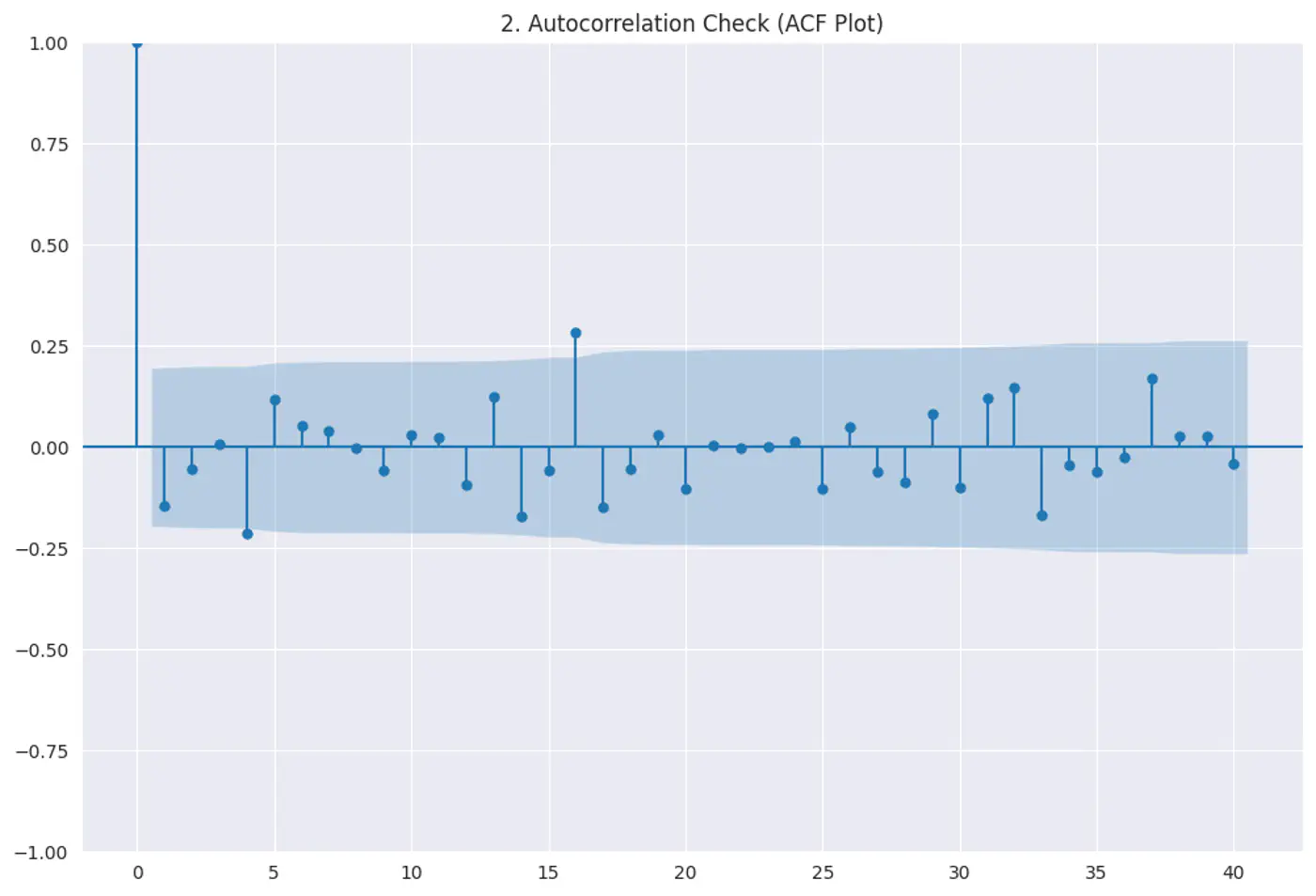
Independence of Errors (No Auto-Correlation)
Residuals (errors) should not have a visible pattern or correlation with one another (most common in time-series ⏰ data).
Risk: If errors are correlated, standard errors will be underestimated, making variables look ‘statistically significant’ when they are not.
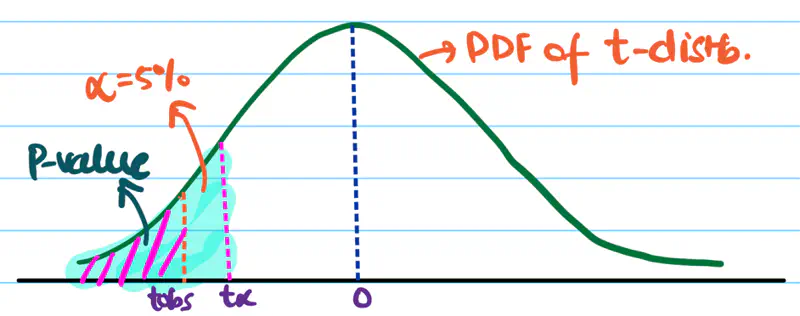
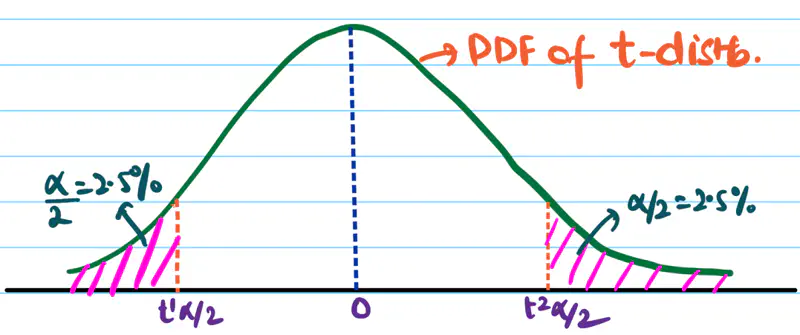
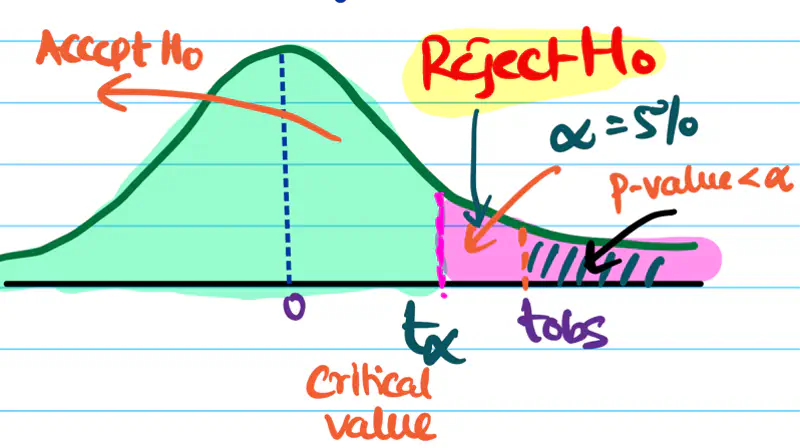
Test:
Durbin–Watson test
Autocorrelation plots (ACF)
Residuals vs time
Homoscedasticity
Constant variance of errors; Var(ϵ|X)=σ
Risk: Standard errors become biased, leading to unreliable hypothesis tests (t-tests, F-tests).
Test:
Breusch–Pagan test
White test
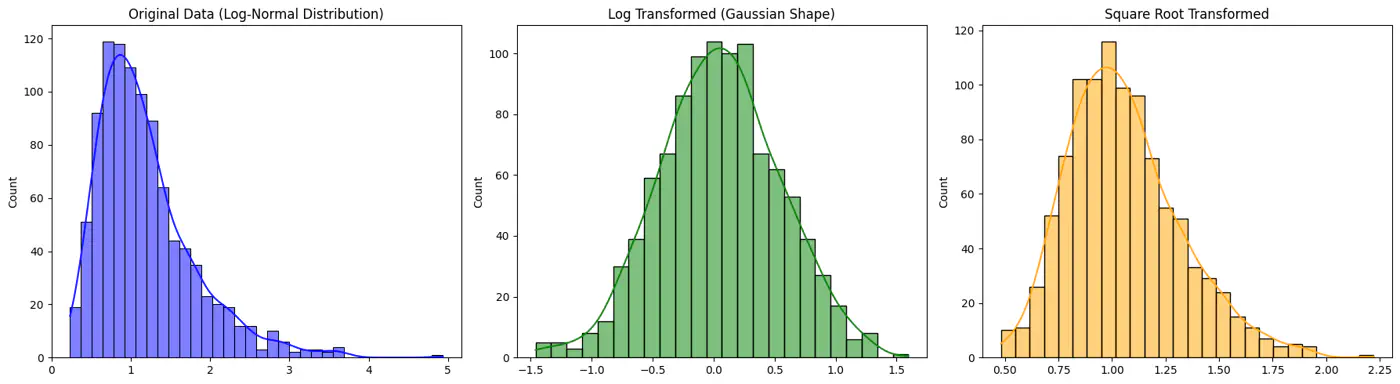
Fix:
Log transform
Weighted Least Squares(WLS)
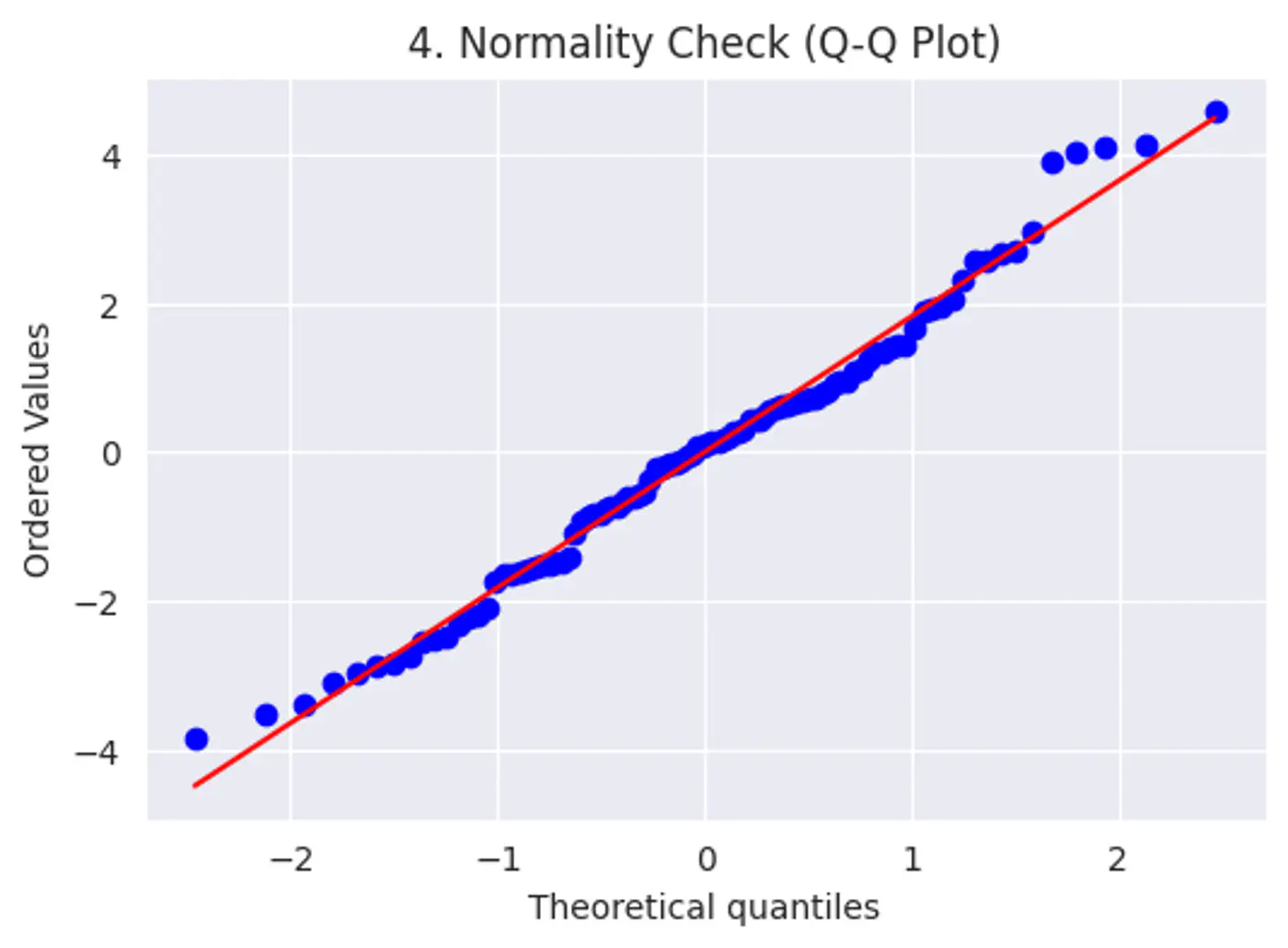
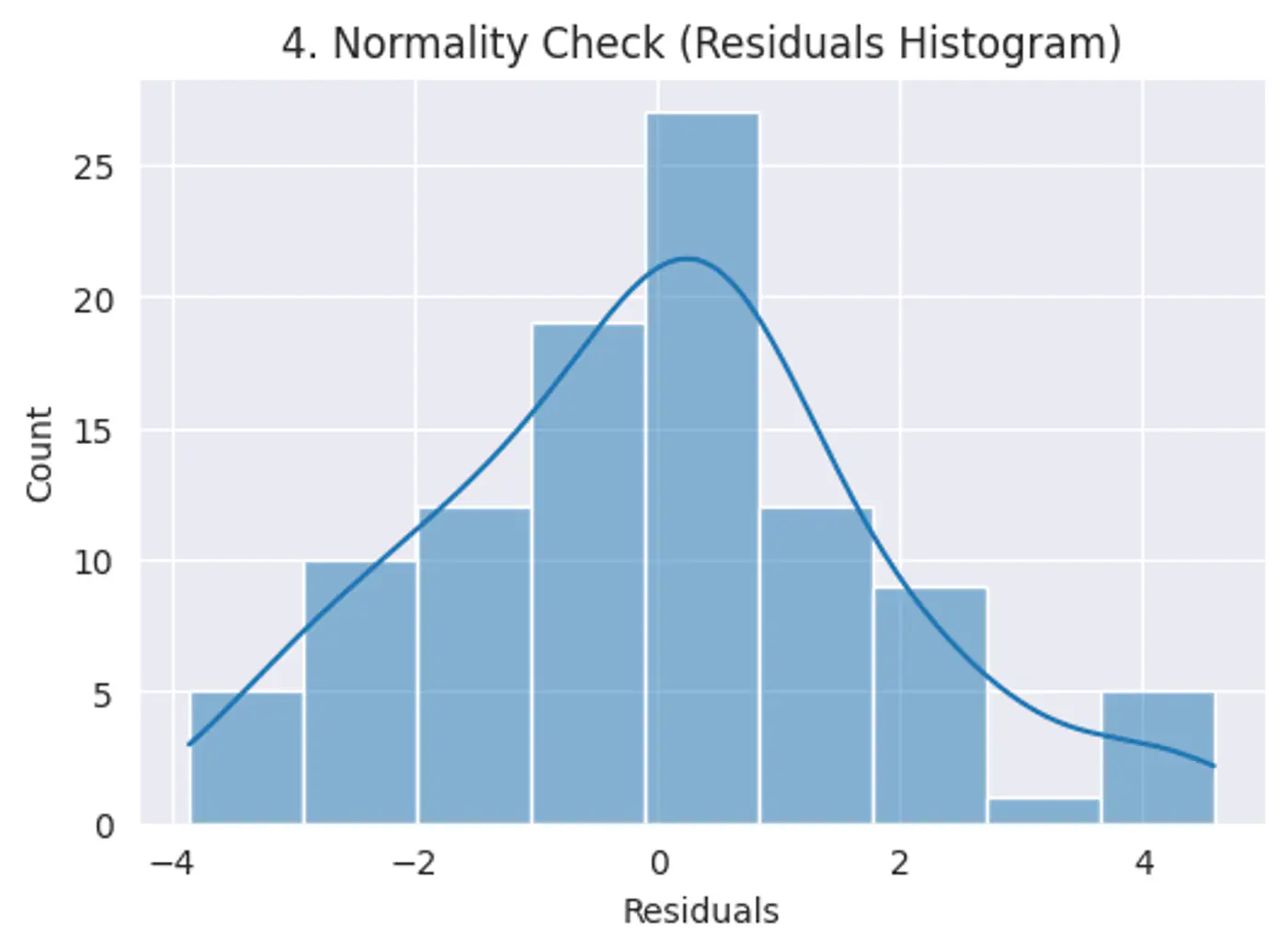
Normality of Errors
Error terms should follow a normal distribution; (Required for small datasets.)
Note: Because of Central Limit Theorem, with a large enough sample size, this becomes less critical for estimation.
Risk: Hypothesis testing (calculating p-values and confidence intervals), we assume the error terms follow a normal distribution.
Test:
Q-Q plot
Shapiro-Wilk Test
No Multicollinearity
Features should not be highly correlated with each other.
Risk:
High correlation makes it difficult to determine the unique, individual impact of each feature. This leads to high variance in model parameter estimates, small changes in data cause large swings in parameters.
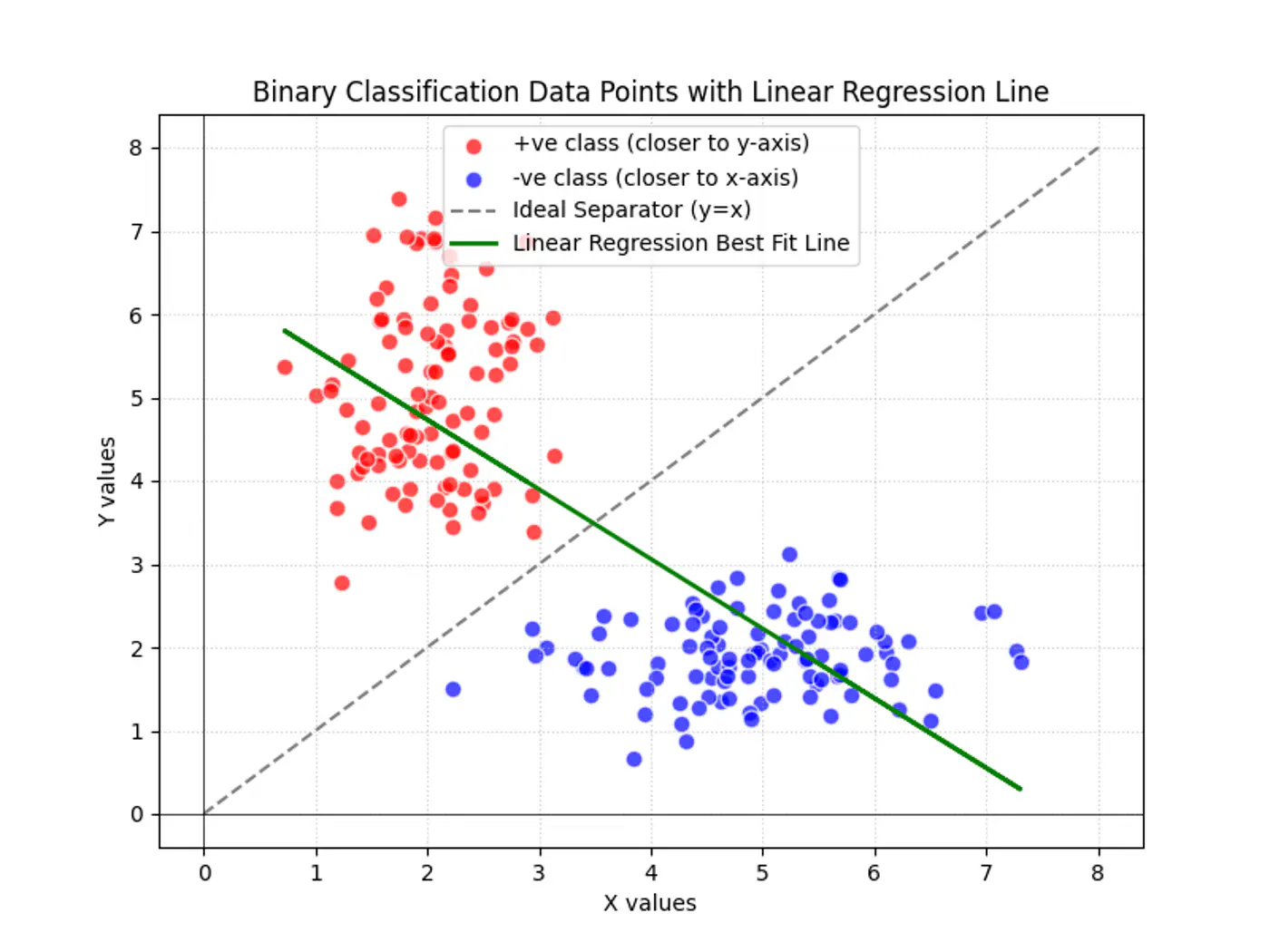
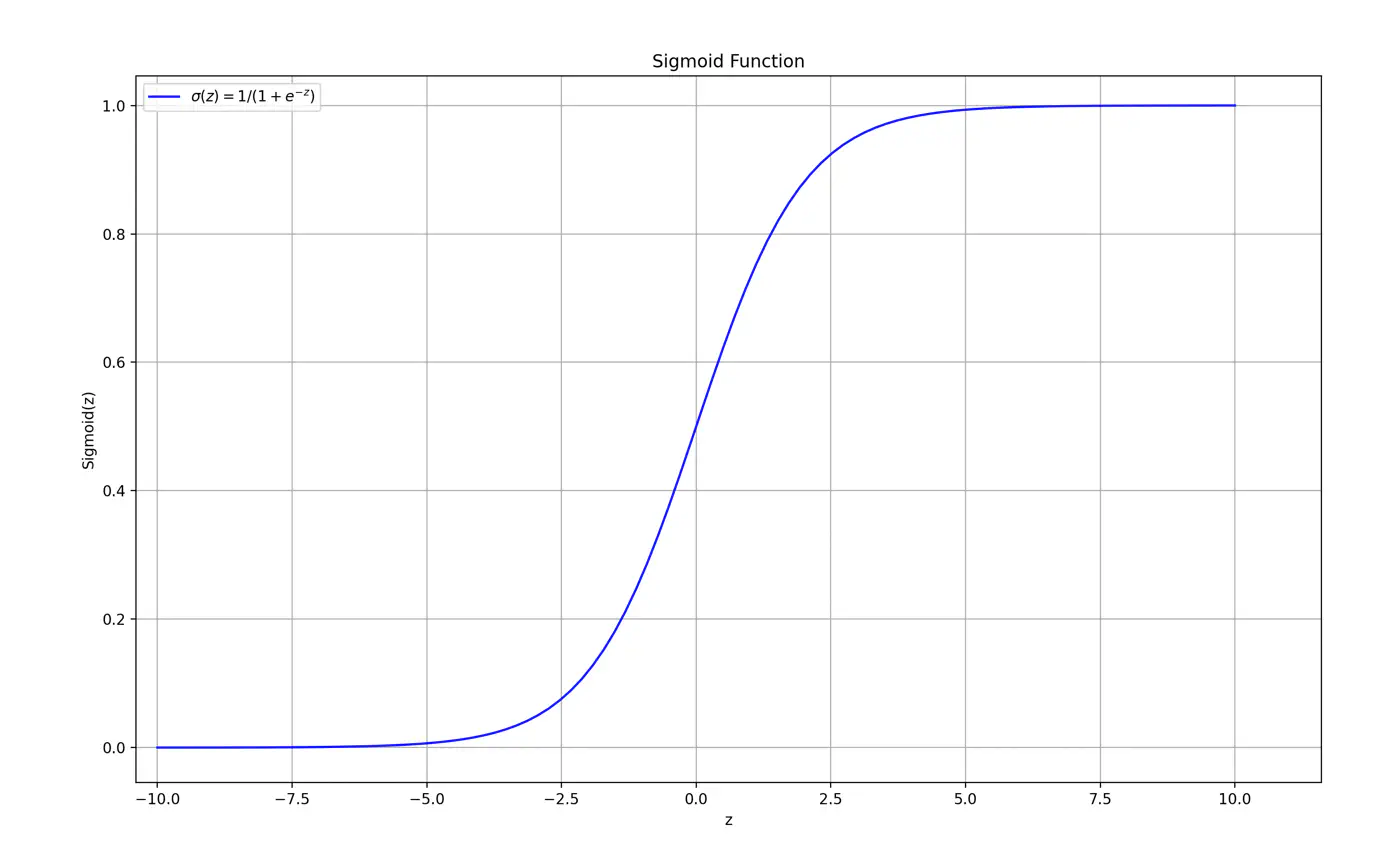
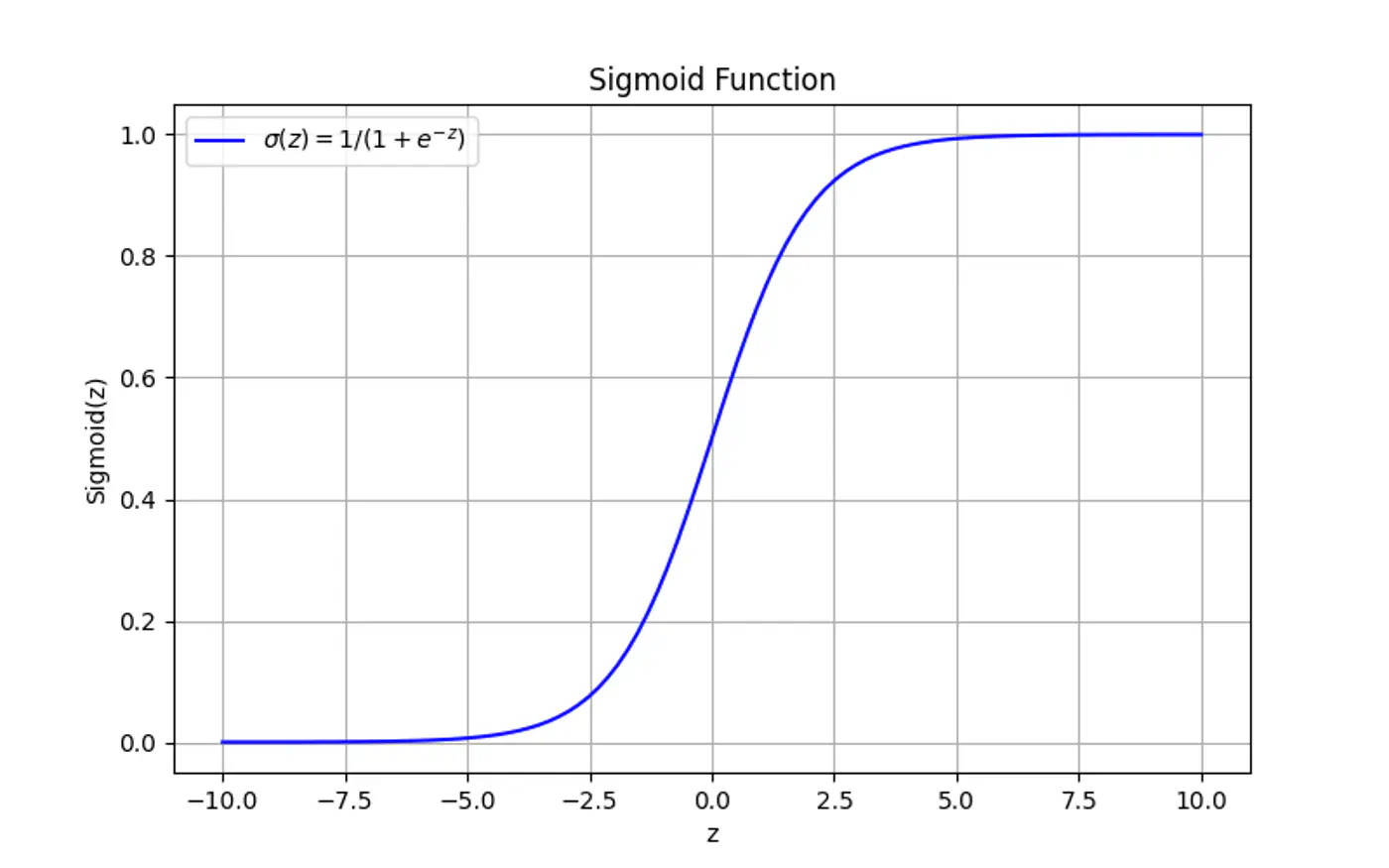
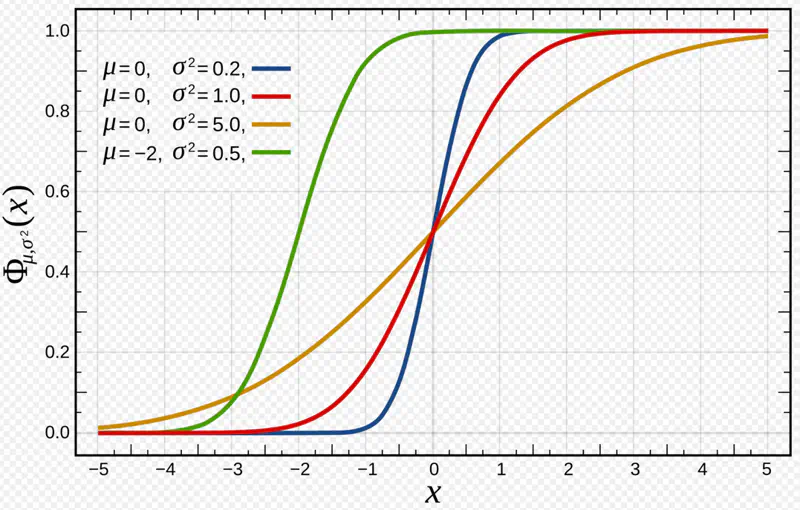
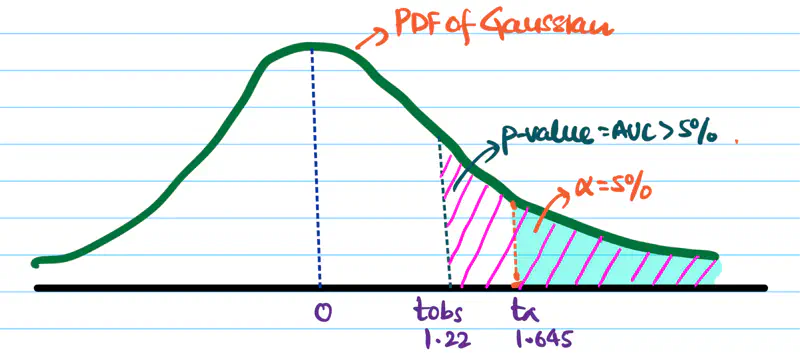
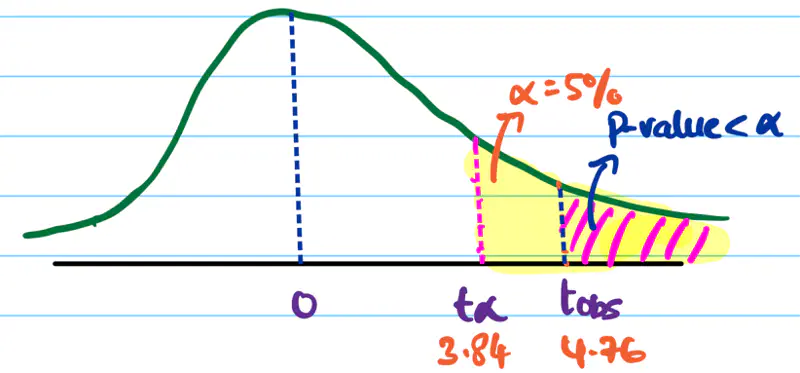
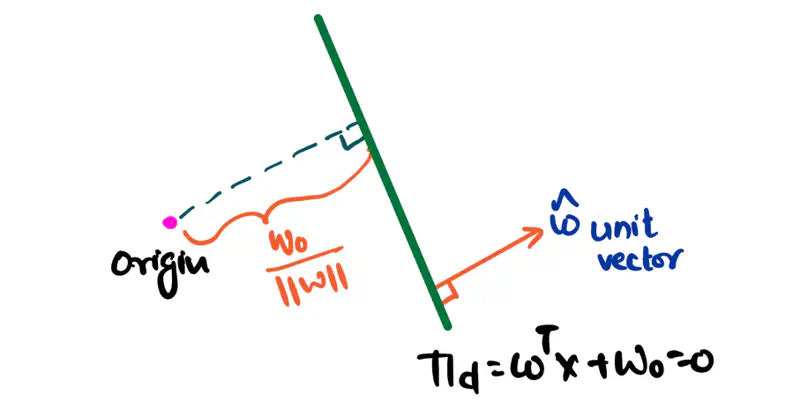
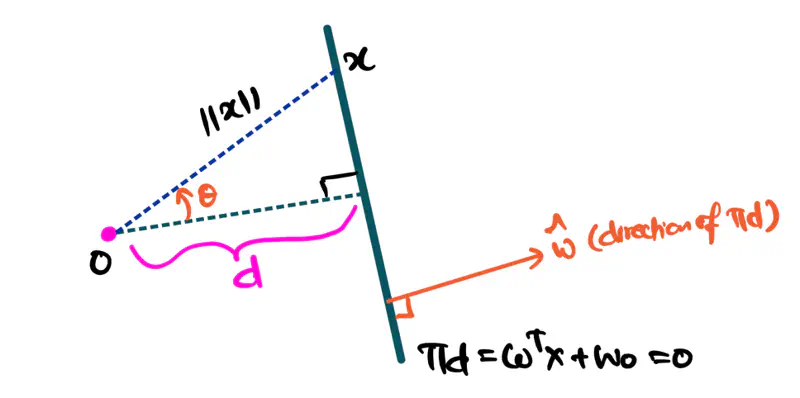
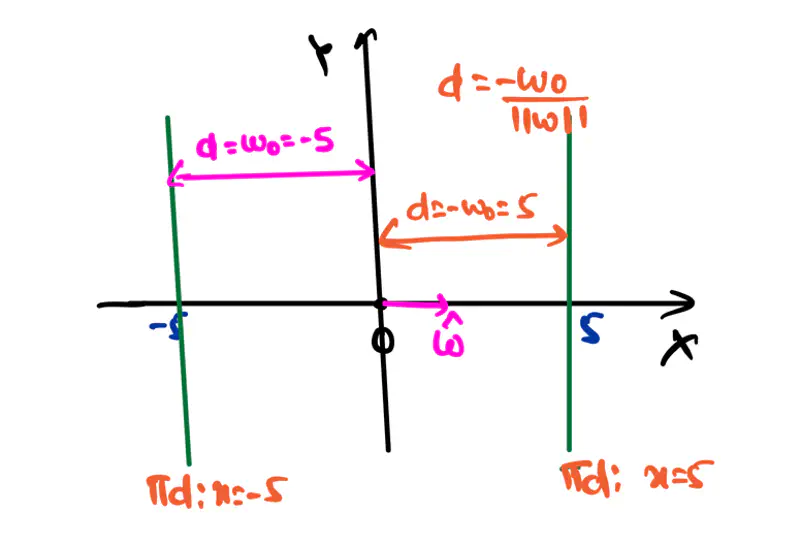
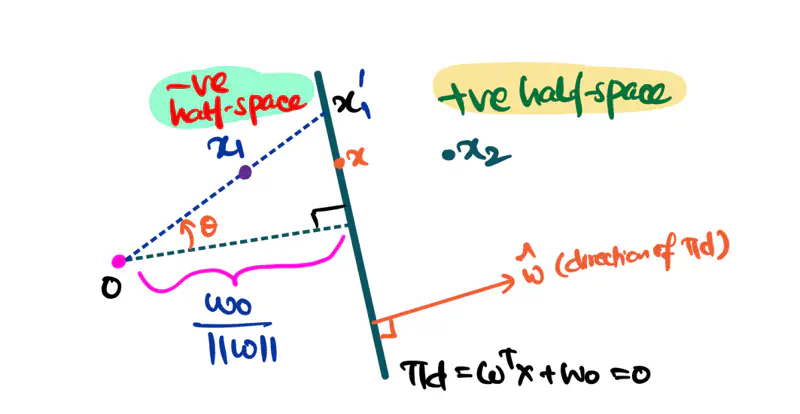
The distance of a point from the hyperplane can range from \(-\infty\) to \(+ \infty\). So we need a link 🔗 to transform the geometric distance to probability.
Sigmoid Function (a.k.a Logistic Function)
Maps the output of a linear equation to a value between 0 and 1, allowing the result to be interpreted as a probability.
\[\hat{y} = \sigma(z) = \frac{1}{1 + e^{-z}}\]
If the distance ‘z’ is large and positive, \(\hat{y} \approx 1\) (High confidence).
If the distance ‘z’ is 0, \(\hat{y} = 0.5\) (Maximum uncertainty).
Why is it called Logistic Regression ?
Because, we use the logistic (sigmoid) function as the ‘link function’🔗 to map 🗺️ the continuous output of the regression into a probability space.
What happens to the weights of Logistic Regression if the data is perfectly linearly separable?
The weights 🏋️♀️ will tend towards infinity, preventing a stable solution.
The model tries to make probabilities exactly 0 or 1, but the sigmoid function never reaches these limits,
leading to extreme weights 🏋️♀️ to push probabilities near the extremes.
Rely on assumption that relationships between data points are linear.
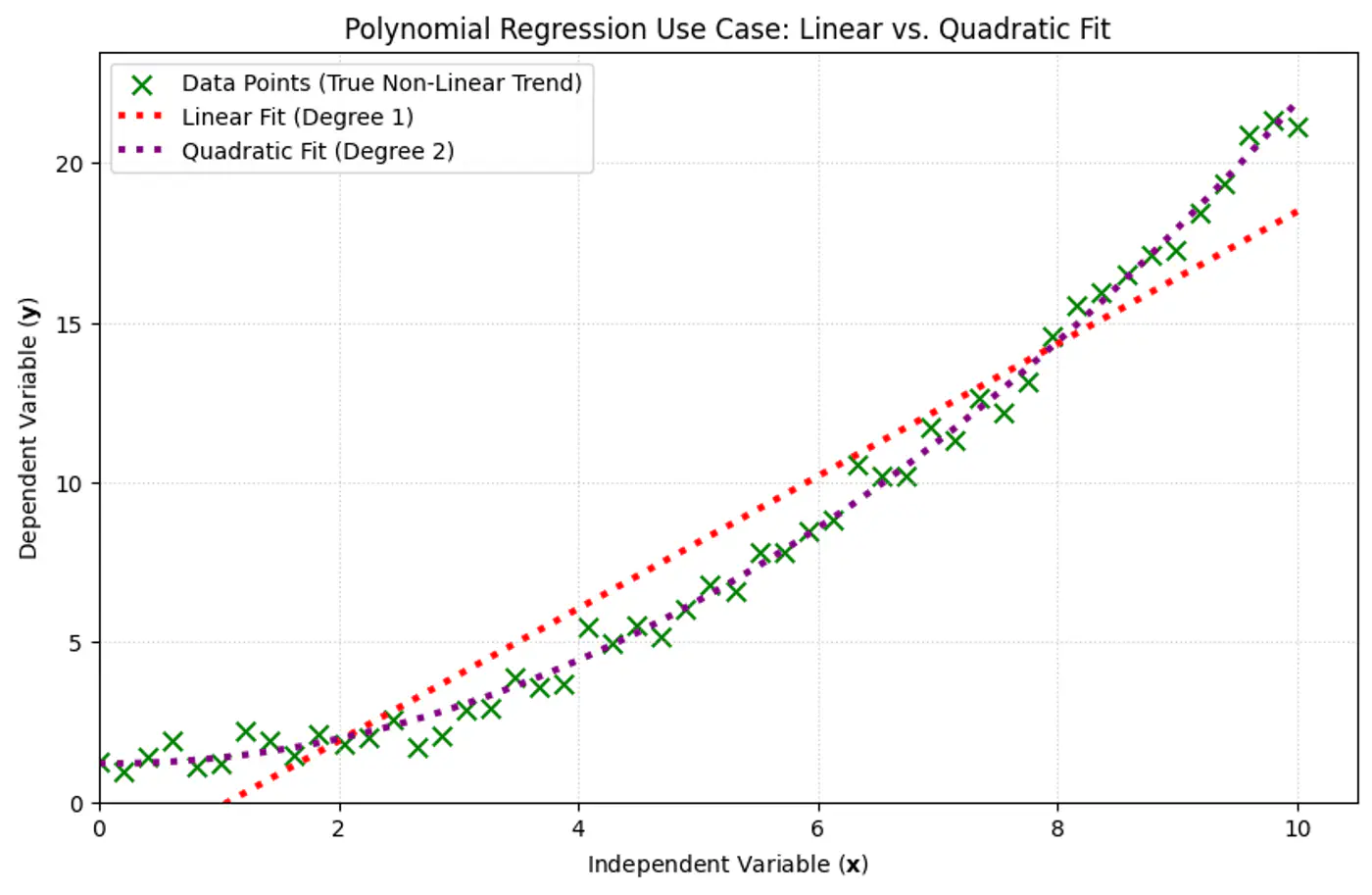
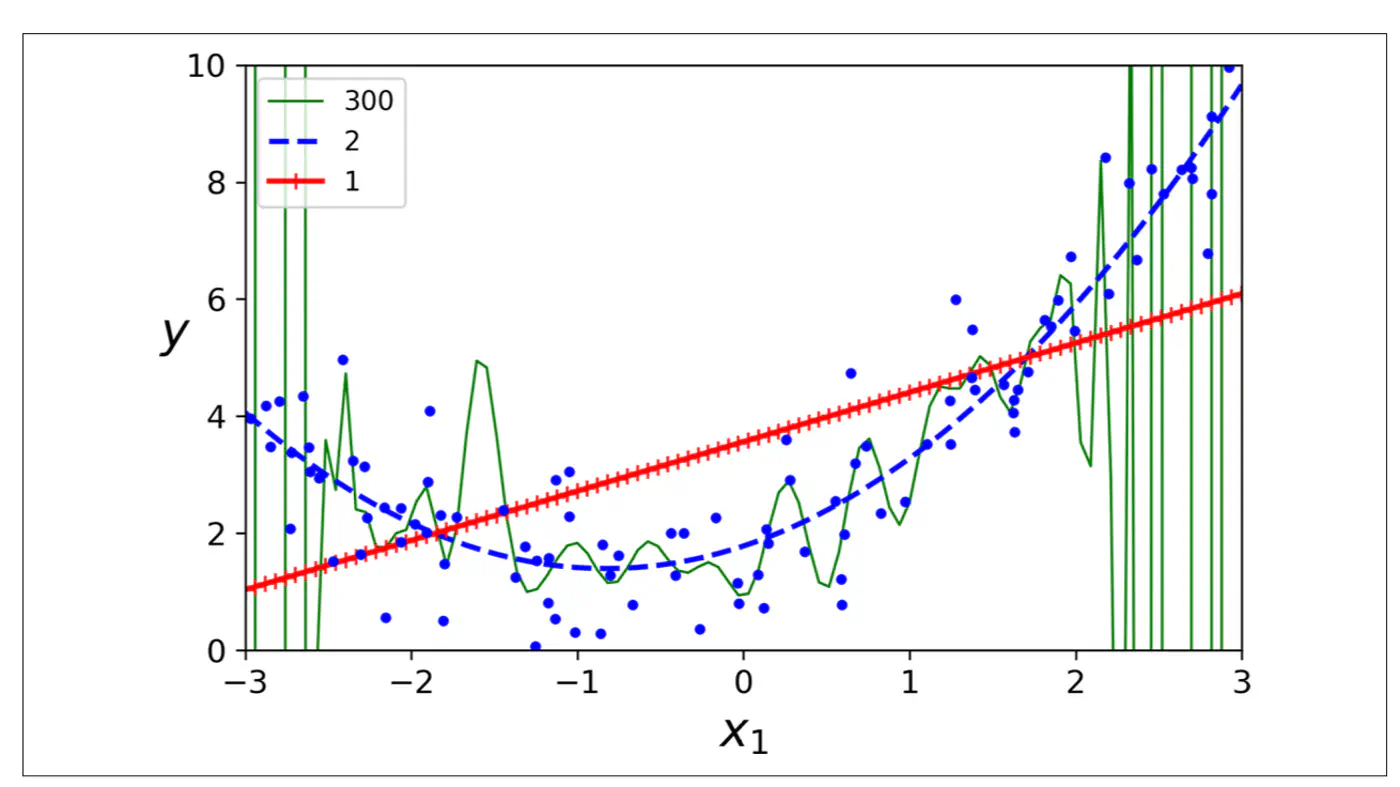
For polynomial regression we need to find the degree of polynomial.
Training:
We need to train 🏃♂️the model for prediction.
K Nearest Neighbors
Simple: Intuitive way to classify data or predict values by finding similar existing data points (neighbors).
Non-Parametric: Makes no assumptions about the underlying data distribution.
No Training Required: KNN is a ‘lazy learner’, it does not require a formal training 🏃♂️ phase.
KNN Algorithm
Given a query point \(x_q\) and a dataset, D = {\((x_i,y_i)_{i=1}^n, \quad x_i,y_i \in \mathbb{R}^d\)},
the algorithm finds a set of ‘k’ nearest neighbors \(\mathcal{N}_k(x_q) \subseteq D\).
Inference:
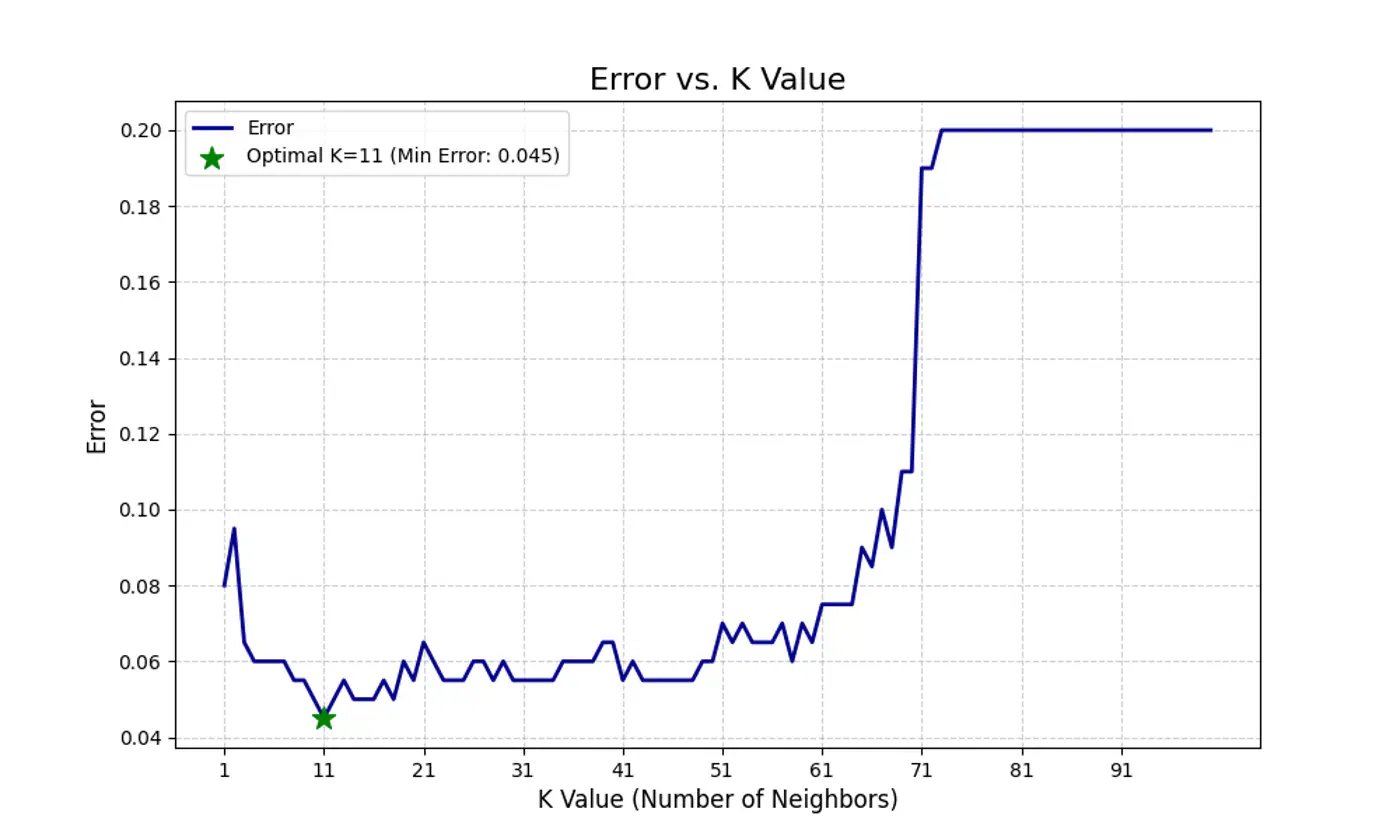
Choose a value of ‘k’ (hyper-parameter); odd number.
Calculate distance (Euclidean, Cosine etc.) between and every point in dataset and store in a distance list.
Sort the distance list in ascending order; choose top ‘k’ data points.
Make prediction:
Classification: Take majority vote of ‘k’ nearest neighbors and assign label.
Regression: Take the mean/median of ‘k’ nearest neighbors.
Note: Store entire dataset.
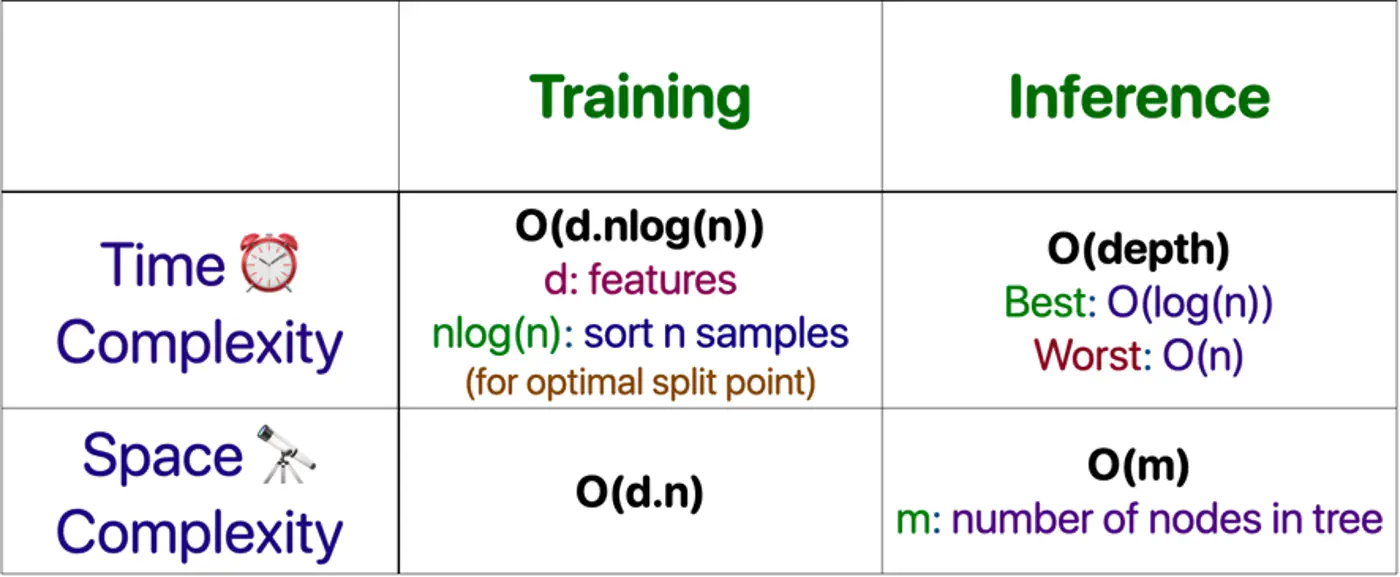
Time & Space Complexity
Storing Data: Space Complexity: O(nd)
Inference: Time Complexity ⏰: O(nd + nlogn)
Explanation:
Distance to all ’n’ points in ‘d’ dimensions: O(nd)
Sorting all ’n’ data points : O(nlogn)
Note: Brute force 🔨 KNN is unacceptable when ’n’ is very large, say billions.
Naive KNN needs some improvements to fix some of its drawbacks.
Standardization
Distance-Weighted KNN
Mahalanobis Distance
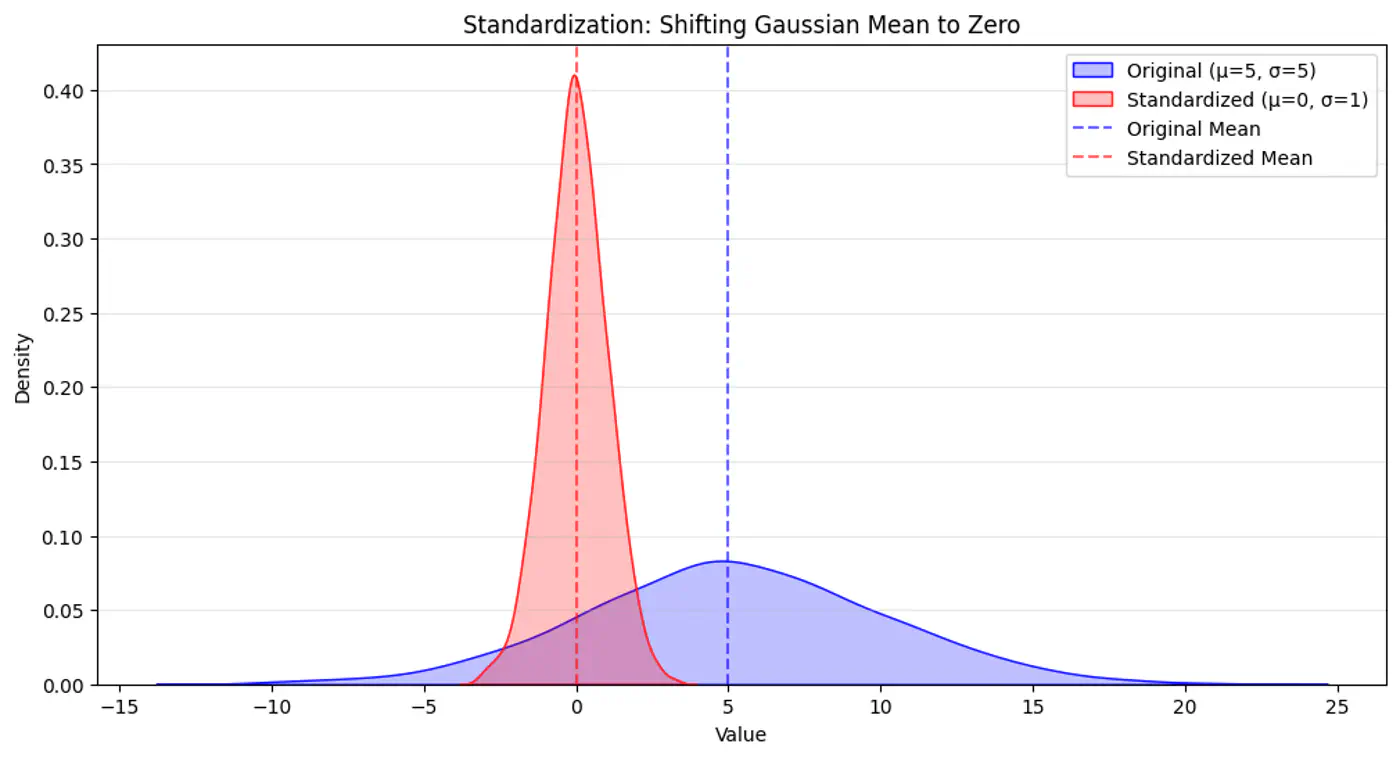
Standardization
⭐️Say one feature is ‘Annual Income’ (0-1M), and another feature is ‘Years of Experience’ (0-40).
👉The Euclidean distance will be almost entirely dominated by income 💵.
💡So, we do standardization of each feature, such that it has a mean, \(\mu\)=0 and variance,\(\sigma\)=1.
\[z=\frac{x-\mu}{\sigma}\]
Distance-Weighted KNN
⭐️Vanilla KNN treats the 1st nearest neighbor and the k-th nearest neighbor as equal.
💡A neighbor that is 0.1units away should have more influence than a neighbor that is 10 units away.
👉We assign weight 🏋️♀️ to each neighbor; most common strategy is inverse of squared distance.
\[w_i = \frac{1}{d(x_q, x_i)^2 + \epsilon}\]
Improvements:
Noise/Outlier: Reduces the impact of ‘noise’ or ‘outlier’ (distant neighbors).
Imbalanced Data: Closer points dominate, mitigating impact of imbalanced data.
e.g: If you have a query point surrounded by 2 very close ‘Class A’ points and 3 distant ‘Class B’ points, weighted 🏋️♀️ KNN will correctly pick ‘Class A'.
Mahalanobis Distance
⭐️Euclidean distance makes assumption that all the features are independent and provide unique information.
💡‘Height’ and ‘Weight’ are highly correlated.
👉If we use Euclidean distance, we are effectively ‘double-counting’ the size of the person.
🏇Mahalanobis distance measures distance in terms of standard deviations from the mean, accounting for the covariance between features.
While Euclidean distance(L norm) is the most frequently discussed, ‘Curse of Dimensionality’ impacts all Minkowski norms (\(L_p\))
\[L_p = (\sum |x_i|^p)^{\frac{1}{p}} \]
Note: ‘Curse of Dimensionality’ is largely a function of the exponent (p) in the distance calculation.
Issues with High Dimensional Data
Coined 🪙 by mathematician John Bellman in the 1960s while studying dynamic programming.
High dimensional data created following challenges:
Distance Concentration
Data Sparsity
Exponential Sample Requirement
Distance Concentration
💡Consider a hypercube in d-dimensions of side length = 1; Volume = \(1^d\) = 1 🧊 A smaller inner cube with side length = 1 - \(\epsilon\) ; Volume = \((1 -\epsilon)^d\)
🧐 This implies that almost all the volume of the high-dimensional cube lies near the ‘crust’. 👉e.g: if \(\epsilon\)= 0.01, d = 500; Volume of inner cube = \((1 -0.01)^{500}\) = \(0.99^{500}\) = 0.006 = 0.6% 🤔Consequently, all points become nearly equidistant, and the concept of ‘nearest’ or ‘neighborhood’ loses
its meaning.
Data Sparsity
⭐️The volume of the feature space increases exponentially with each added dimension.
👉To maintain the same data density found in a 1D space with 10 points, we would need \(10^{10}\)(10 billion) points in 10D space.
💡Because real-world datasets are rarely this large, the data becomes “sparse,” making it difficult to find truly similar neighbors.
Exponential Sample Requirement
⭐️To maintain a reliable result, the amount of training data needed must grow exponentially with the number of dimensions.
👉Without this growth, the model is highly prone to overfitting, where it learns from noise in the ‘sparse’ data
rather than actual underlying patterns.
Note: For modern embeddings (often 768 or 1536 dimensions), it is mathematically impossible to collect enough data
to ‘fill’ the space.
Solution
Cosine Similarity
Normalization
Cosine Similarity
Cosine similarity measures the cosine of the angle between 2 vectors.
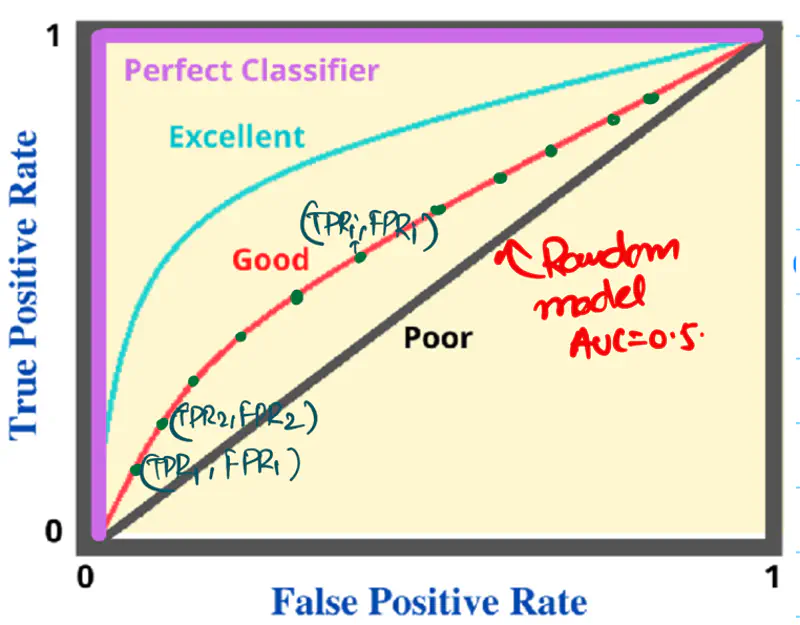
Note: The goal of a decision tree algorithm is to find the split that maximizes information gain, meaning it removes the most uncertainty from the data.
Gini 🧞♂️Impurity
⭐️ Measures the probability of an element being incorrectly classified if it were randomly labeled according to the distribution of labels in a node.
\[Gini(S)=1-\sum_{i=1}^{n}(p_{i})^{2}\]
Range: 0 (Pure) - 0.5 (Maximum impurity)
Note: Gini is used in libraries like Scikit-Learn (as the default), because it avoids the computationally expensive 💰 log function.
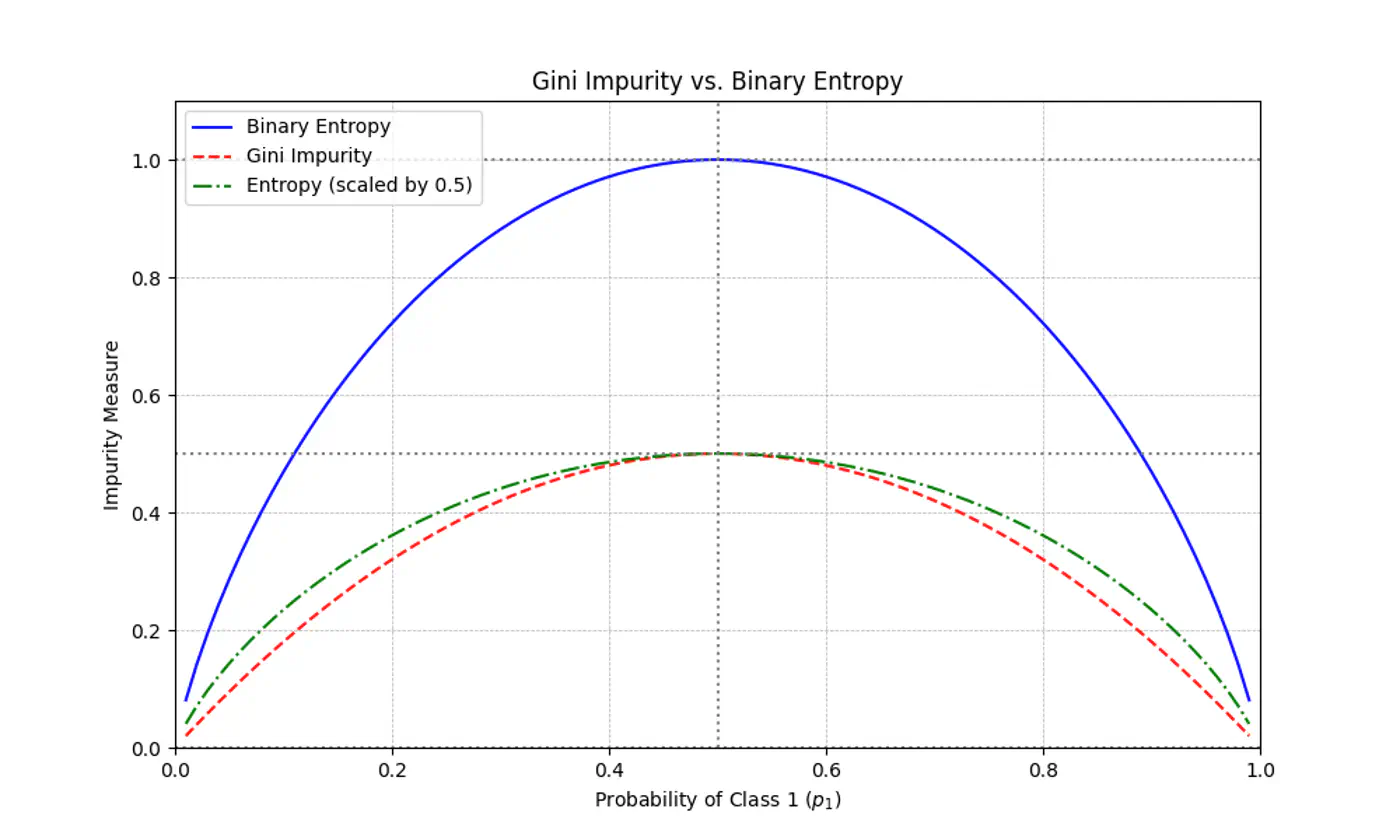
Gini Impurity Vs Entropy
Gini Impurity is a first-order approximation of Entropy.
For most of the real-world cases, choosing one over the other results in the exact same tree structure or negligible differences in accuracy.
When we plot the two functions, they follow nearly identical shapes.
Decision Trees can also be used for Regression tasks but using a different metrics.
⭐️Metric:
Mean Squared Error (MSE)
Mean Absolute Error (MAE)
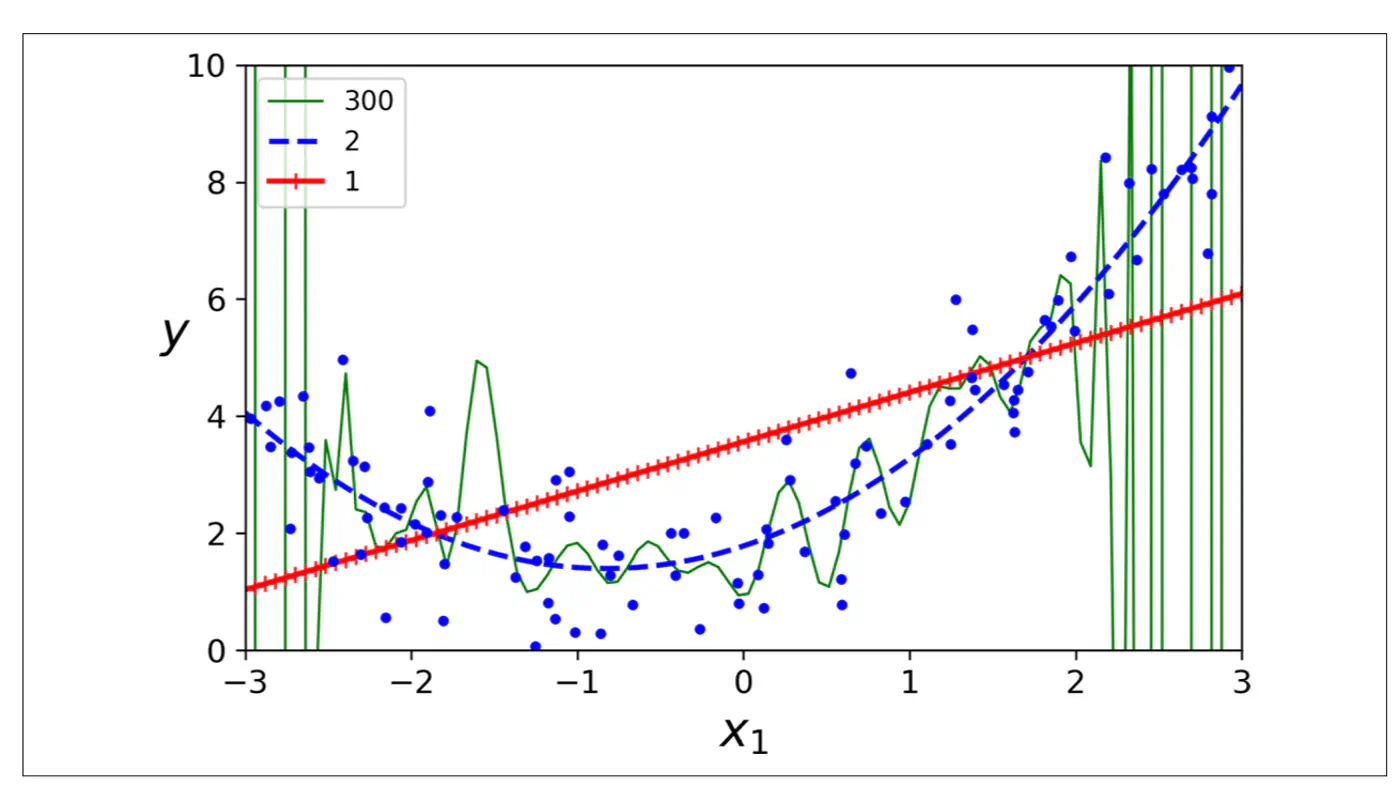
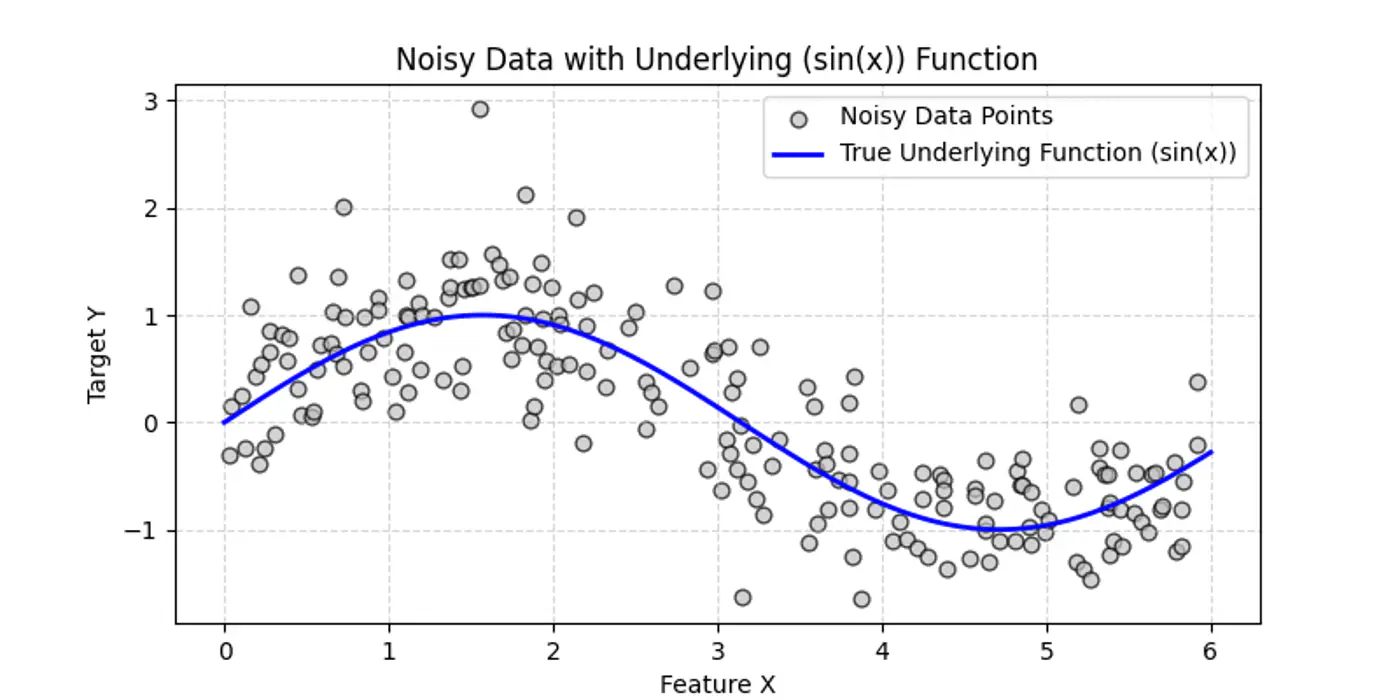
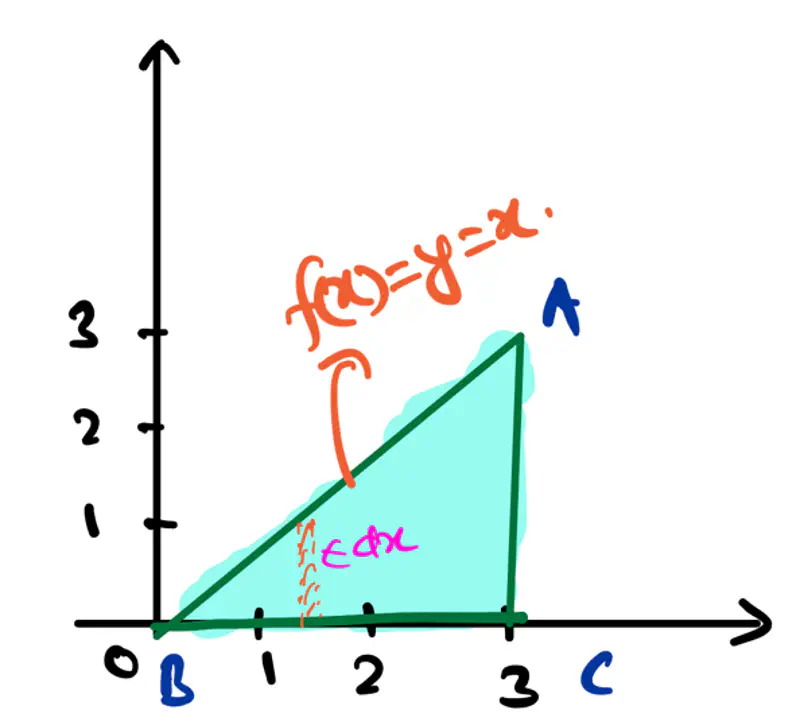
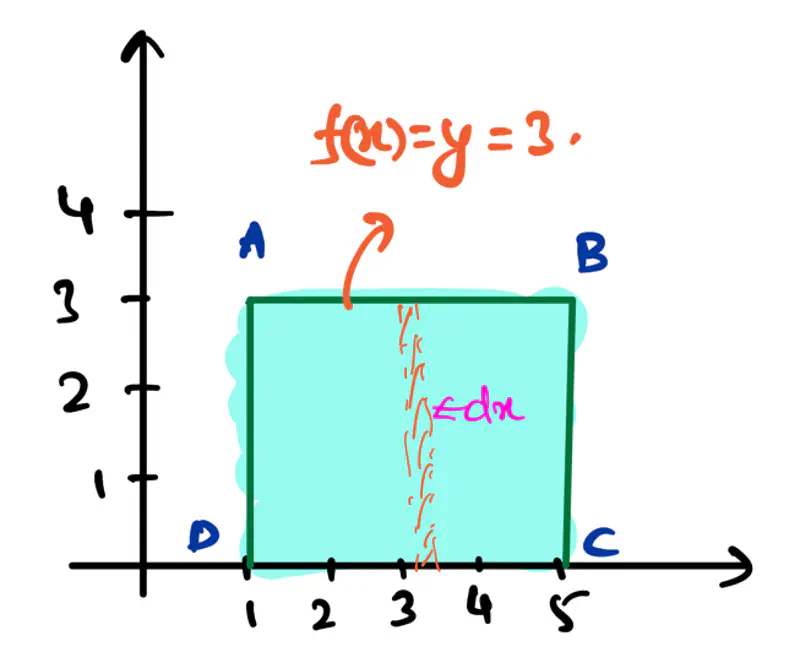
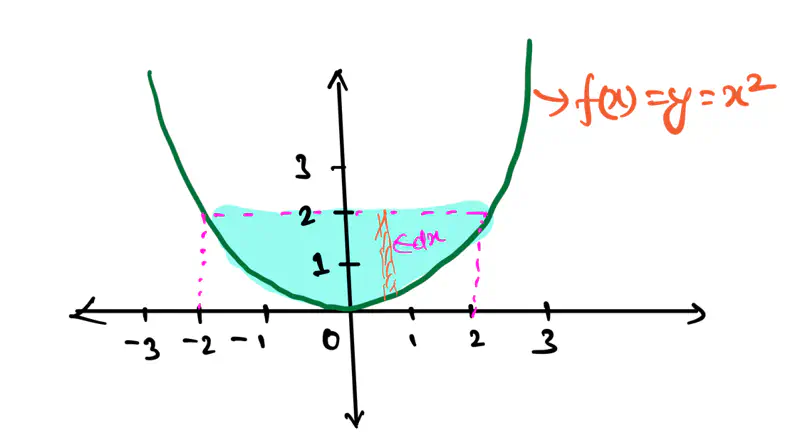
👉Say we have a following dataset, that we need to fit using decision trees:
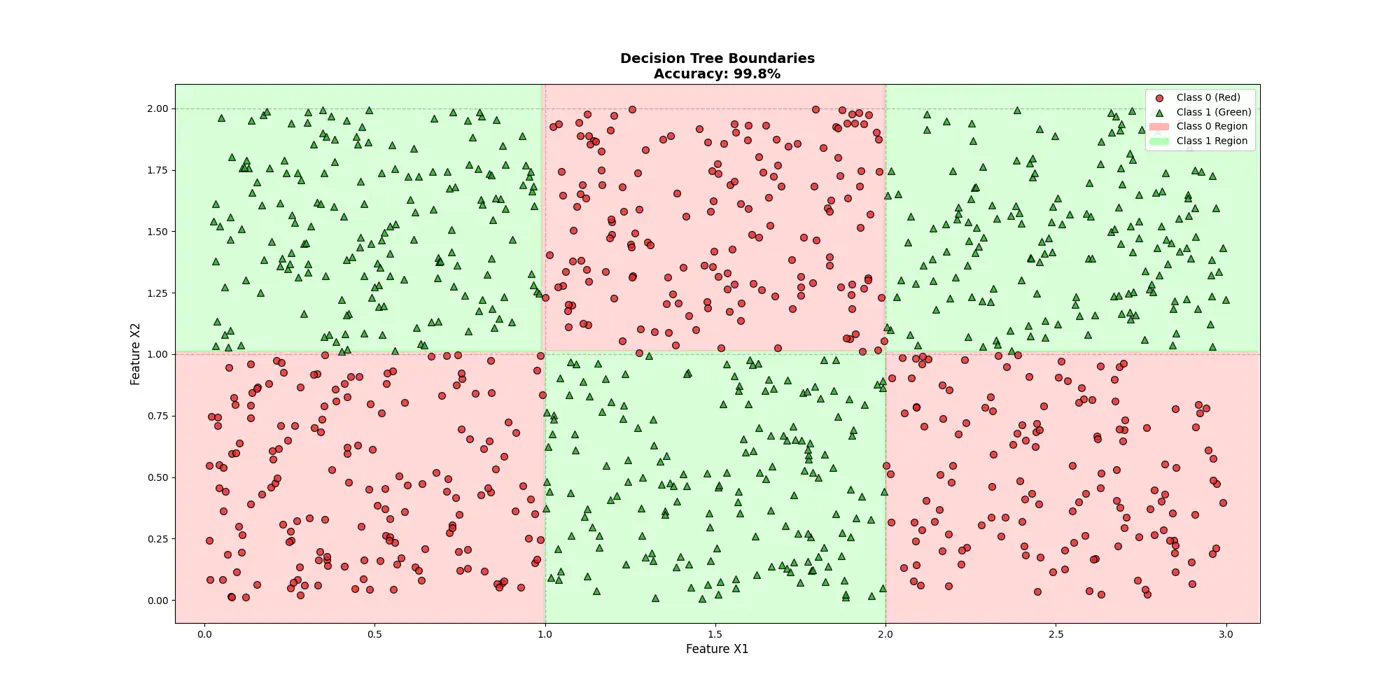
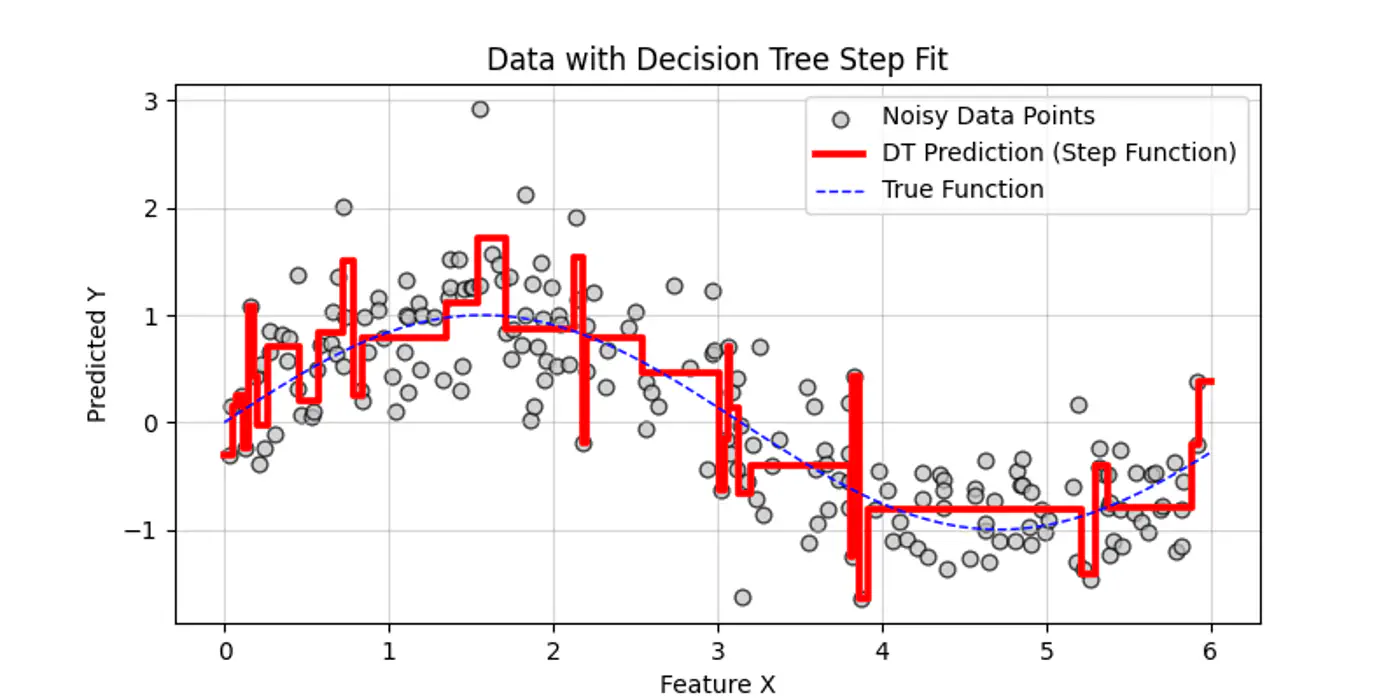
👉Decision trees try to find the decision splits, building step functions that approximate the actual curve,
as shown below:
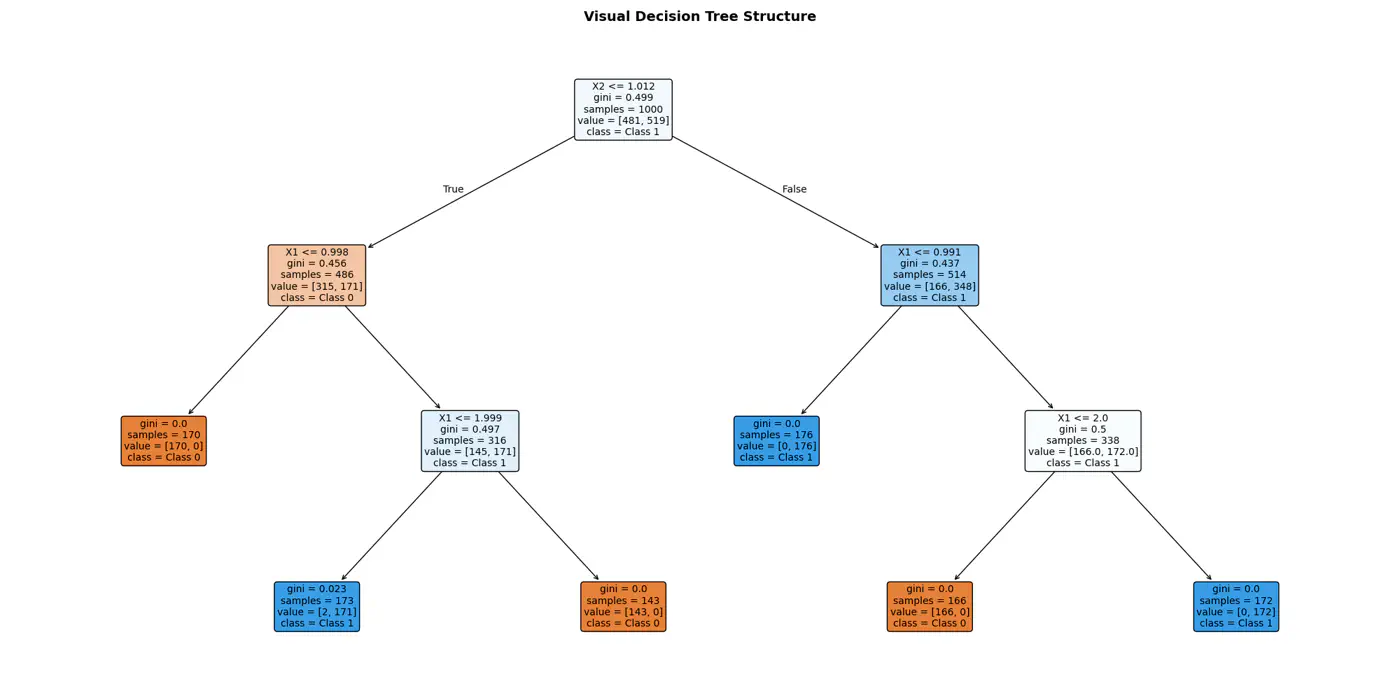
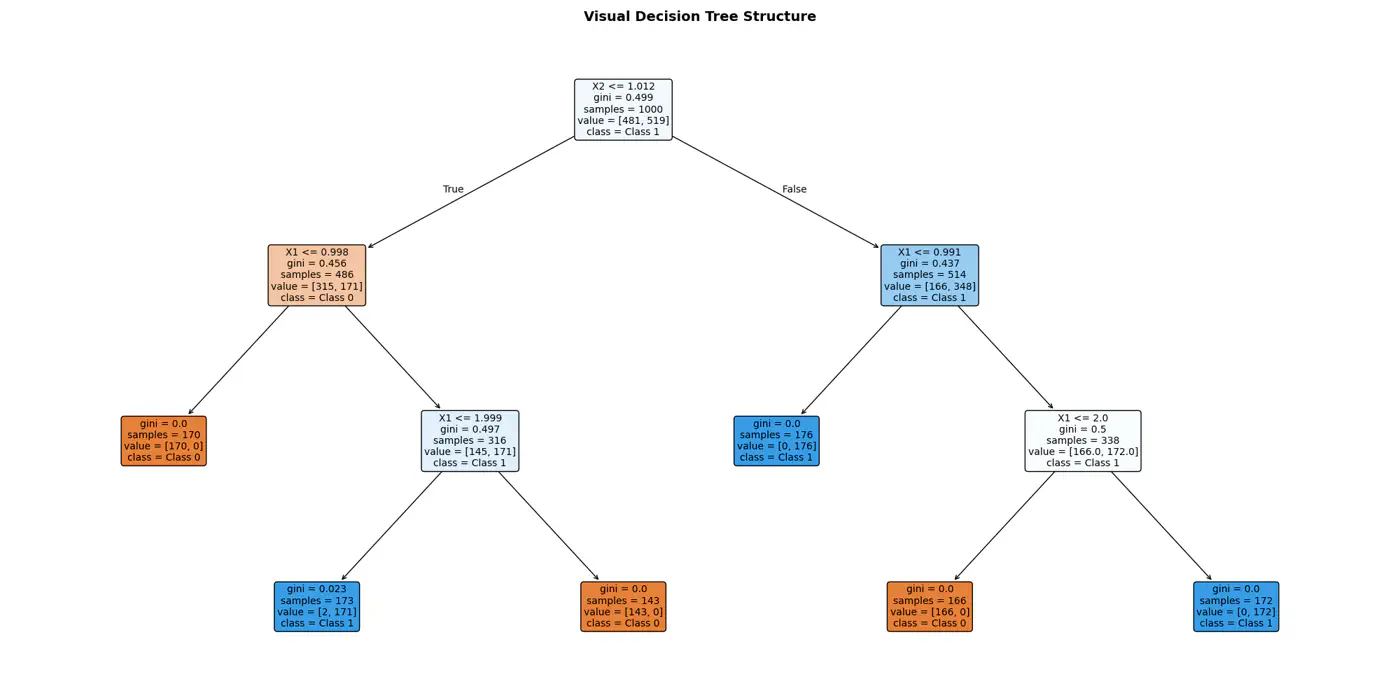
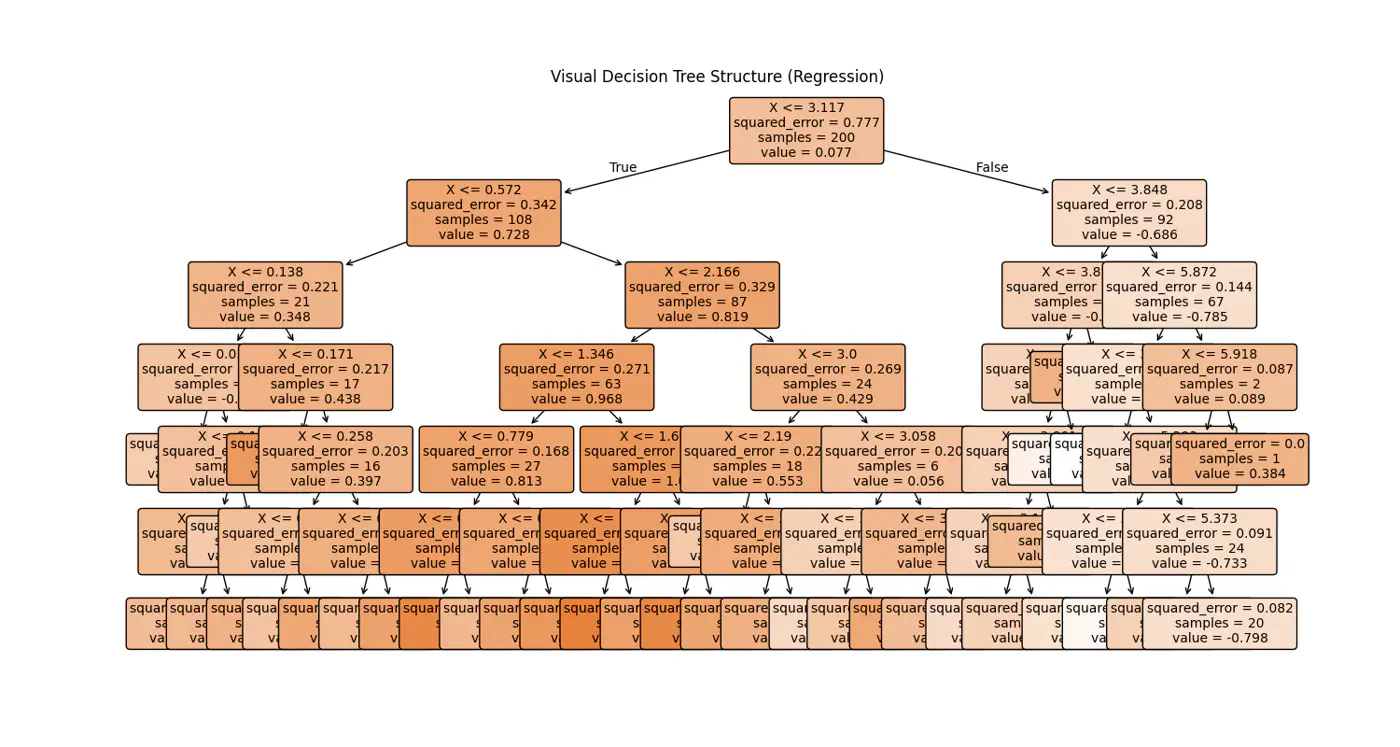
👉Internally the decision tree (if else ladder) looks like below:
Can we use decision trees for all kinds of regression?
Or is there any limitation ?
Decision trees cannot predict values outside the range of the training data, i.e, extrapolation.
Let’s understand the interpolation and extrapolation cases one by one.
Interpolation ✅
⭐️Predicting values within the range of features and targets observed during training 🏃♂️.
Trees capture discontinuities perfectly, because they are piece-wise constant.
They do not try to force a smooth line where a ‘jump’ exists in reality.
e.g: Predicting a house 🏡 price 💰 for a 3-BHK home when you have seen 2-BHK and 4-BHK homes in that same neighborhood.
Extrapolation ❌
⭐️Predicting values outside the range of training 🏃♂️data.
Problem: Because a tree outputs the mean of training 🏃♂️ samples in a leaf, it cannot predict a value higher than the
highest ‘y’ it saw during training 🏃♂️.
Flat-Line: Once a feature ‘X’ goes beyond the training boundaries, the tree falls into the same ‘last’ leaf forever.
e.g: Predicting the price 💰 of a house 🏡 in 2026 based on data from 2010 to 2025.
⭐️Because trees🌲 are non-parametric and ‘greedy’💰, they will naturally try to grow 📈 until every leaf 🍃 is pure,
effectively memorizing noise and outliers rather than learning generalizable patterns.
Tree 🌲 Size
👉As the tree 🌲 grows, the amount of data in each subtree decreases 📉, leading to splits based on statistically insignificant samples.
max_depth: Limits how many levels of ‘if else’ the tree can have; most common.
min_samples_split: A node will only split, if it has at least ‘N’ samples; smooths the model (especially in regression), by ensuring predictions are based on an average of multiple points.
max_leaf_nodes: Limiting the number of leaves reduces the overall complexity of the tree, making it simpler and less likely to memorize the training data’s noise.
min_impurity_decrease: A split is only made if it reduces the impurity (Gini/MSE) by at least a certain threshold.
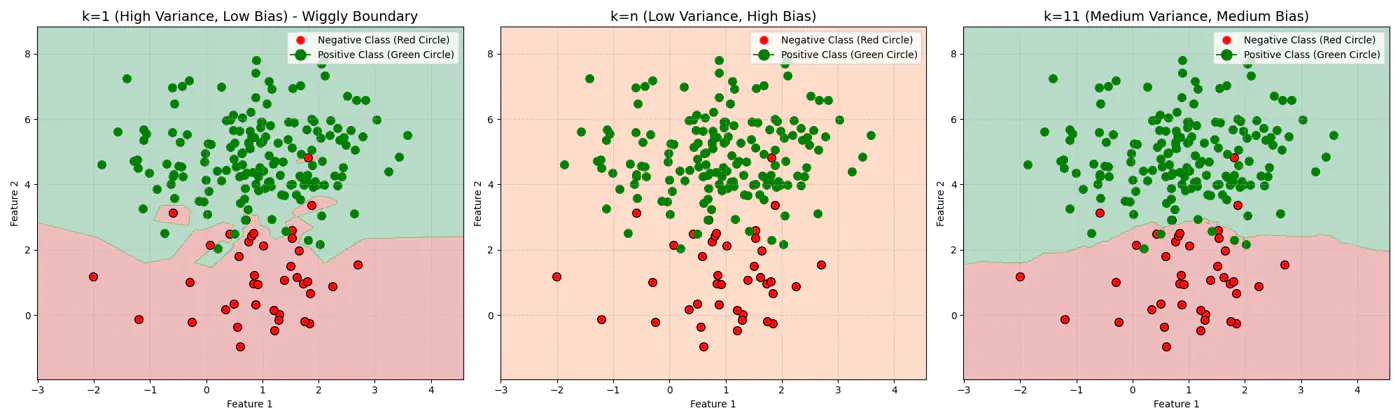
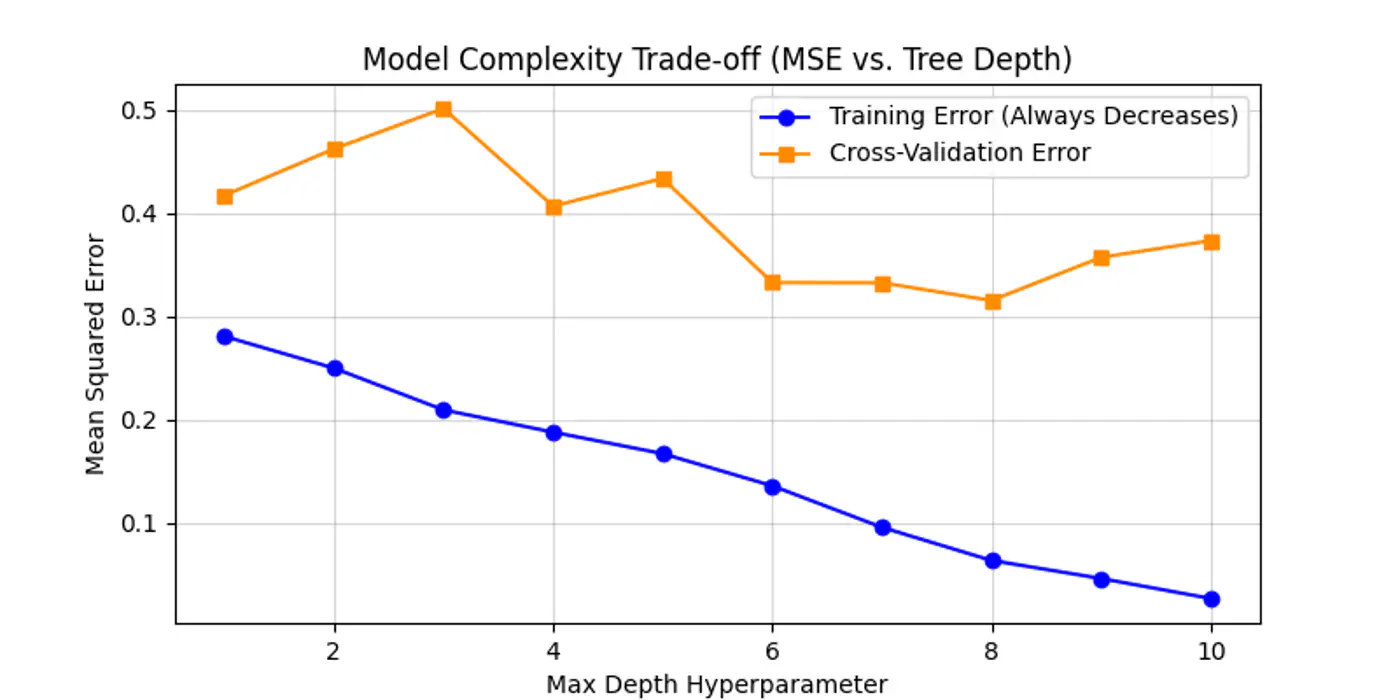
Max Depth Hyper Parameter Tuning
Below is an example for one of the hyper-parameter’s max_depth tuning.
As we can see below the cross-validation error decreases till depth=6 and after that
reduction in error is not so significant.
Post-Pruning ✂️
Let the tree🌲 grow to its full depth (overfit) and then ‘collapse’ nodes that provide little predictive value.
Most common algorithm:
Minimal Cost Complexity Pruning
Minimal Cost Complexity Pruning ✂️
💡Define a cost-complexity 💰 measure that penalizes the tree 🌲 for having too many leaves 🍃.
\[R_\alpha(T) = R(T) + \alpha |T|\]
R(T): total misclassification rate (or MSE) of the tree
|T|: number of terminal nodes (leaves)
\(\alpha\): complexity parameter (the ‘tax’ 💰 on complexity)
Logic:
If \(\alpha\)=0, the tree is the original overfit tree.
As \(\alpha\) increases 📈, the penalty for having many leaves grows 📈.
To minimize the total cost 💰, the model is forced to prune branches that do not significantly reduce R(T).
Use cross-validation to find the ‘sweet spot’ \(\alpha\) that minimizes validation error.
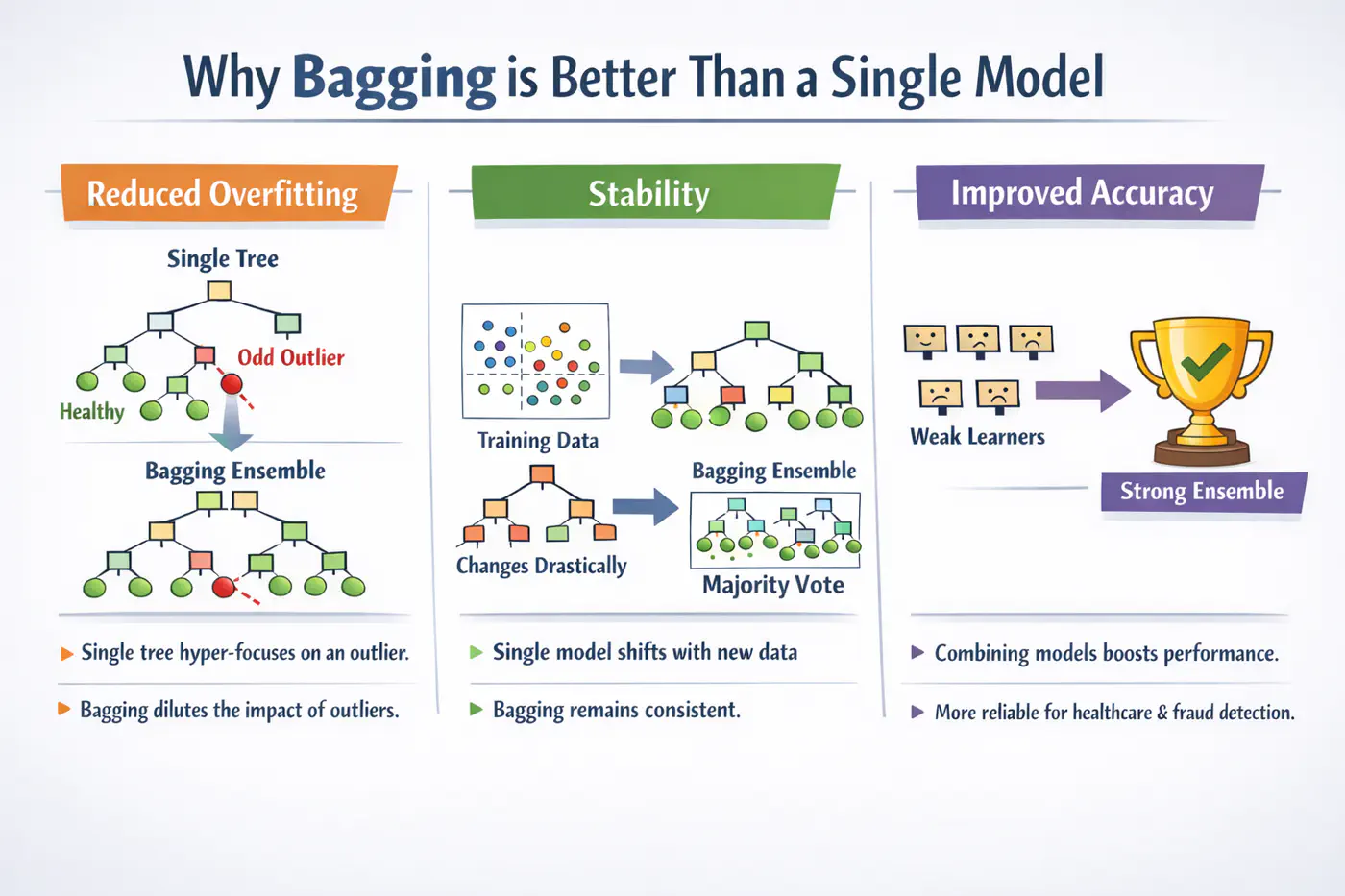
A single decision tree is highly sensitive to the specific training dataset. Small changes, such as, a few different rows or the presence of an outlier, can lead to a completely different tree structure.
Unpruned decision trees often grow until they perfectly classify the training set, essentially ‘memorizing’
noise and outliers, i.e, high variance, rather than finding general patterns.
What does Bagging mean 🤔?
Bagging = ‘Bootstrapped Aggregation’
Bagging 🎒is a parallel ensemble technique that reduces variance (without significantly increasing the bias)
by training multiple versions of the same model on different random subsets of data and then combining their results.
Note: Bagging uses deep trees (overfit) and combines them to reduce variance.
Bootstrapping
Bootstrapping = ‘Without external help’
Given a training 🏃♂️set D of size ’n’, we create B new training sets D by sampling ’n’ observations from D ‘with replacement'.
Bootstrapped Samples
💡Since, we are sampling ‘with replacement’, so, some data points may be picked multiple times,
while others may not be picked at all.
The probability that a specific observation is not selected in a bootstrap sample of size ’n’ is:
\[\lim_{n \to \infty} \left(1 - \frac{1}{n}\right)^n = \frac{1}{e} \approx 0.368\]
🧐This means each tree is trained on roughly 63.2% of the unique data, while the
remaining 36.8% (the Out-of-Bag or OOB set) can be used for cross validation.
Aggregation
⭐️Say we train ‘B’ models (base-learners), each with variance \(\sigma^2\) .
👉Average variance of ‘B’ models (trees) if all are independent:
\[Var(X)=\frac{\sigma^{2}}{B}\]
👉Since, bootstrap samples are derived from the same dataset, the trees are correlated with some
correlation coefficient ‘\(\rho\)'.
💡Choose a randomsubset of ‘m’ features from the total ‘d’ features, reducing the correlation ‘\(\rho\)’ between trees.
👉By forcing trees to split on ‘sub-optimal’ features, we intentionally increase the variance of individual trees;
also the bias is slightly increased (simpler trees).
Standard heuristics:
Classification: \(m = \sqrt{d}\)
Regression: \(m = \frac{d}{3}\)
Math of De-Correlation
💡Because ‘\(\rho\)’ is the dominant factor in the variance of the ensemble when B is large,
the overall ensemble variance Var(\(f_{rf}\)) drops significantly lower than standard Bagging.
💡In a standard Decision Tree or Random Forest, the algorithm searches for the optimal split point (the threshold ’s’)
that maximizes Information Gain or minimizes MSE.
👉This search is:
computationally expensive (sort + mid-point) and
tends to follow the noise in the training 🏃♂️data.
Adding Randomness
Adding randomness (right kind) in ensemble averaging reduces correlation/variance.
Random Thresholds: Instead of searching for the best split point (computationally expensive 💰) for a feature,
it picks a threshold at random from a uniform distribution between the feature’s local minimum and maximum.
Entire Dataset: Uses entire training dataset (default) for every tree; no bootstrapping.
Random Feature Subsets: Random subset of m<n features is used in each decision tree.
Structural correlation between trees becomes extremely low.
Individual trees are ‘weaker’ and have higher bias than a standard optimized tree.
👉The massive drop in ‘\(\rho\)’ often outweighs the slight increase in bias, leading to an overall ensemble that is
smoother and more robust to noise than a standard Random Forest.
Note: Extra Trees are almost always grown to full depth, as they may need extra splits to find the same decision boundary.
When to use Extra Trees ?
Performance: Significantly faster to train, as it does not sort data to find optimal split. Note: If we are working with billions of rows or thousands of features, ET can be 3x to 5x faster than a Random Forest(RF).
Robustness to Noise: By picking thresholds randomly, tends to ‘handle’ the noise more effectively than RF.
Feature Importance: Because ET is so randomized, it often provides more ‘stable’ feature importance scores.
Note: It is less likely to favor a high-cardinality feature (e.g. zip-code) just because it has more potential split points.
⭐️In Bagging 🎒we trained multiple strong(over-fit, high variance) models (in parallel) and then averaged them out to reduce variance.
💡Similarly, we can train many weak(under-fit, high bias) models sequentially, such that, each new model corrects the errors of the previous ones to reduce bias.
Boosting
⚔️ An ensemble learning approach where multiple ‘weak learners’ (typically simple models like shallow decision trees 🌲 or ‘stumps’)
are sequentially combined to create a single strong predictive model.
⭐️The core principle is that each subsequent model focuses 🎧 on correcting the errors made by its predecessors.
Why is Boosting Better ?
👉Boosting generally achieves better predictive performance because it actively reduces bias by learning 📖from ‘past mistakes’, making it ideal for achieving state-of-the-art 🖼️ results.
💡Works by increasing 📈 the weight 🏋️♀️ of misclassified data points after each iteration, forcing the next weak learner to
‘pay more attention’🚨 to the difficult cases.
⭐️ Commonly used for classification.
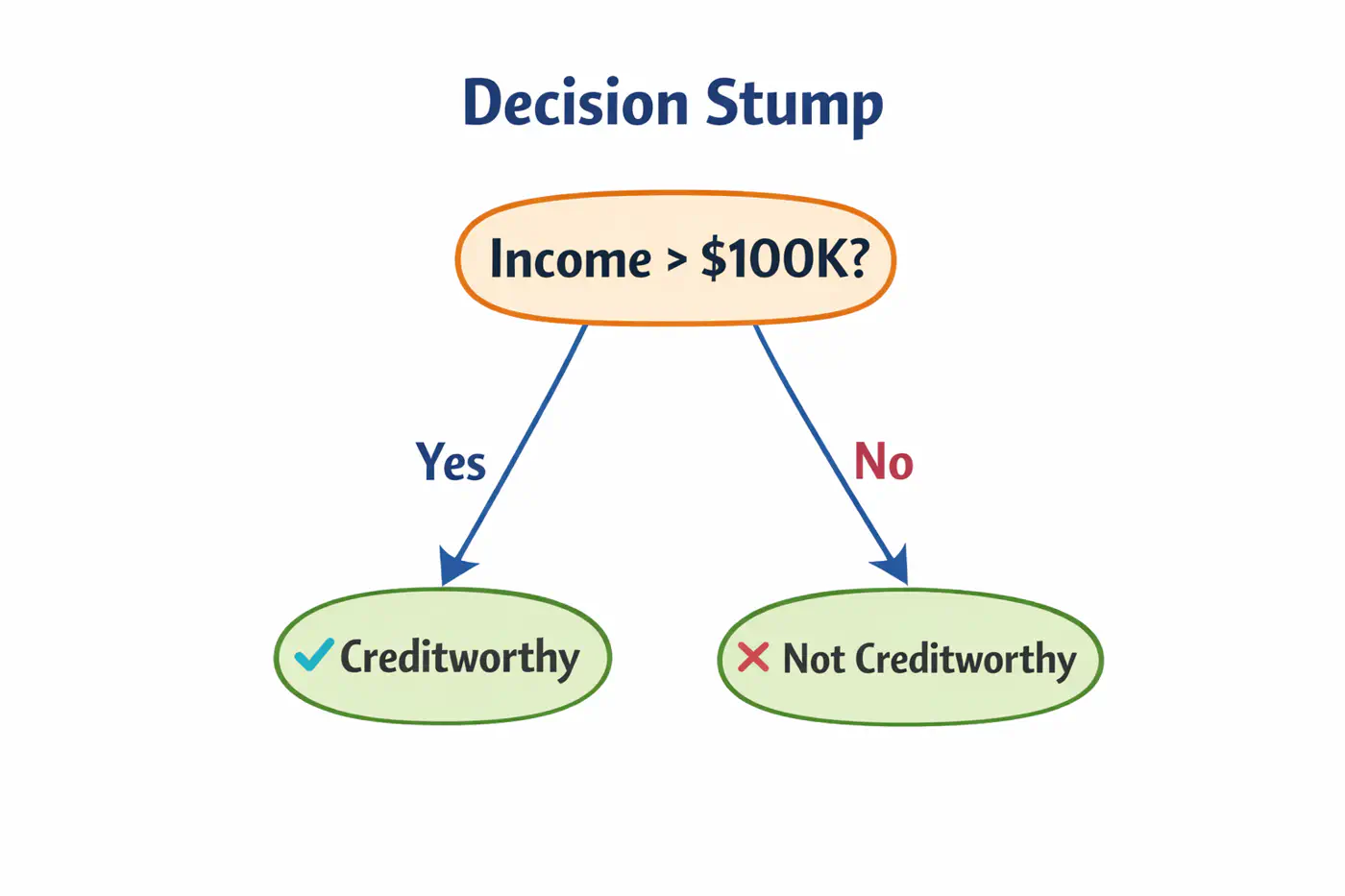
Decision Stumps
👉Weak learners are typically ‘Decision Stumps’, i.e, decision trees🌲with a depth of only one (1 split, 2 leaves 🍃).
Algorithm
Assign an equal weight 🏋️♀️to every data point; \(w_i = 1/n\), where ’n’=number of samples.
Build a decision stump that minimizes the weighted classification error.
Calculate total error; \(E_m = \Sigma w_i\).
Determine ‘amount of say’, i.e, the weight 🏋️♀️ of each stump in final decision.
\[\alpha_m = \frac{1}{2}ln\left( \frac{1-E_m}{E_m} \right)\]
Low error results in a high positive \(\alpha\) (high influence).
50% error (random guessing) results in an \(\alpha = 0\) (no influence).
Update sample weights 🏋️♀️.
Misclassified samples: Weight 🏋️♀️ increases by \(e^{\alpha_m}\).
Correctly classified samples: Weight 🏋️♀️ decreases by \(e^{-\alpha_m}\).
Normalization: All new weights 🏋️♀️ are divided by their total sum so they add up back to 1.
Iterate for a specified number of estimators (n_estimators).
Final Prediction 🎯
👉 To classify a new data point, every stump makes a prediction (+1 or -1).
These are multiplied by their respective ‘amount of say’ \(\alpha_m\) and summed.
\[H(x)=sign\sum_{m=1}^{M}\alpha_{m}⋅h_{m}(x)\]
👉 If the total weighted 🏋️♀️ sum is positive, the final class is +1; otherwise -1.
Note: Sensitive to outliers; Because AdaBoost aggressively increases weights 🏋️♀️ on misclassified points, it may ‘over-focus’ on noisy outliers, hurting performance.
Note: We can keep adding more trees with every iteration; ideally, learning rate \(\nu\) is small, say 0.1, so that we do not overshoot and converge slowly.
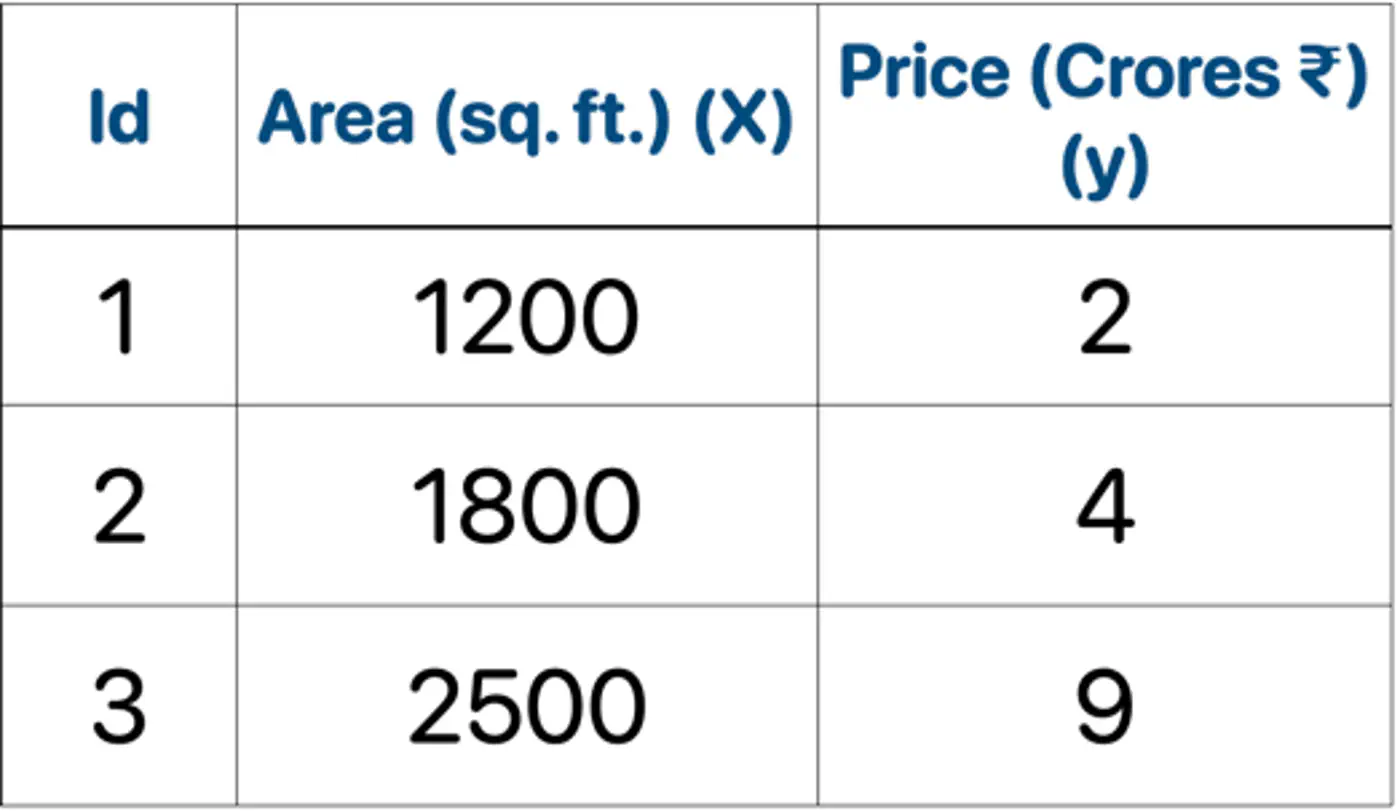
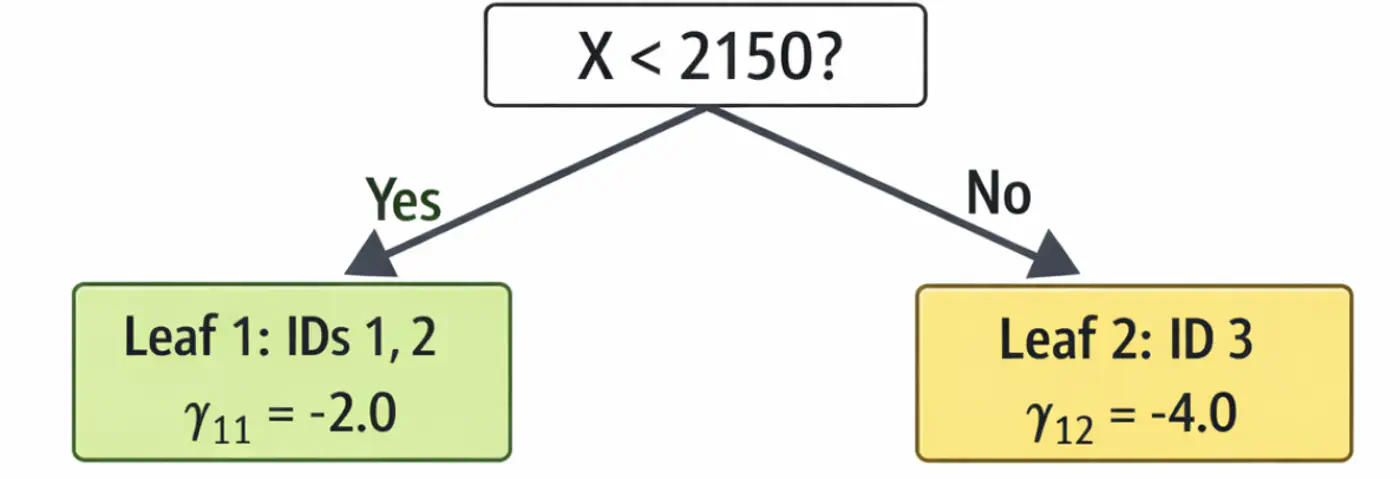
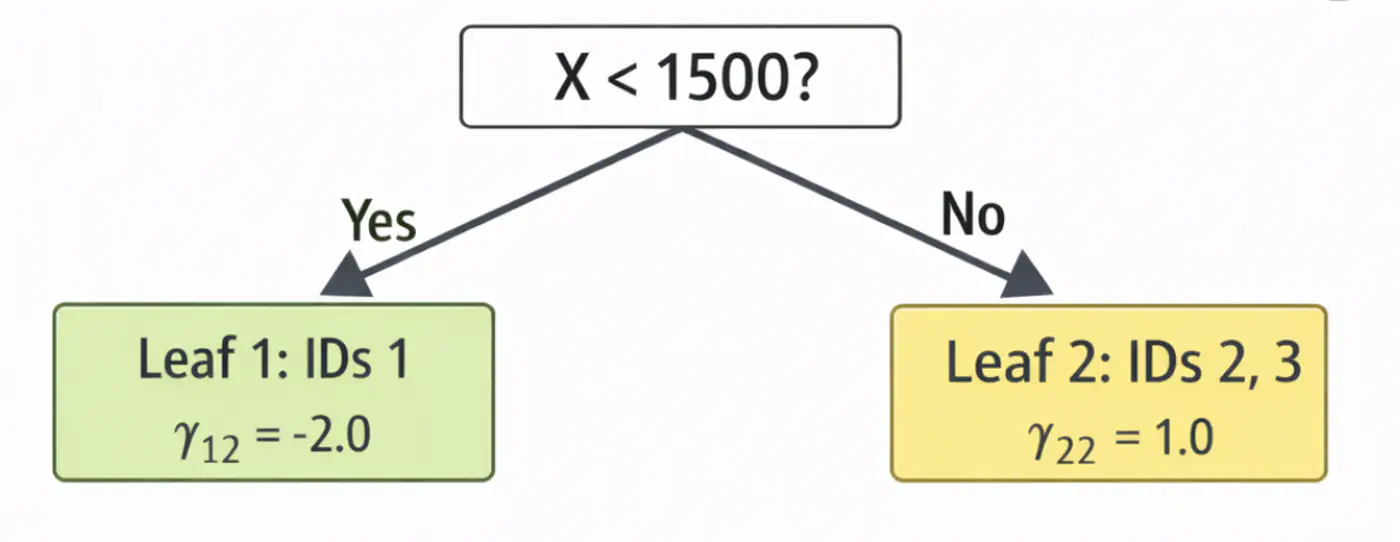
Let’s predict the price of a house with area = 2000 sq. ft.
\(F_{0}=5.0\)
Pass though tree 1 (\(h_1\)): is 2000 < 2150 ? Yes, \(\gamma_{11}\)= -2.0
Contribution (\(h_1\)) = 0.5 x (-2.0) = -1.0
Pass though tree 2 (\(h_2\)): is 2000 < 1500 ? No, \(\gamma_{22}\) = 1.0
Contribution(\(h_2\)) = 0.5 x (1.0) = 0.5
Final prediction = 5.0 - 1.0 + 0.5 = 4.5
Therefore, the price of a house with area = 2000 sq. ft is Rs 4.5 crores, which is very close. In just 2 iterations, although with higher learning rate (\(\nu=0.5\)), we were able to get a fairly good estimate.
⭐️An optimized and highly efficient implementation of gradient boosting.
👉 Widely used in competitive data science (like Kaggle) due to its speed and performance.
Note: Research project developed by Tianqi Chen during his doctoral studies at the University of Washington.
LightGBM (Light Gradient Boosting Machine)
⭐️Developed by Microsoft, this framework is designed for high speed and efficiency with large datasets.
👉It grows trees leaf-wise rather than level-wise and uses Gradient-based One-Side Sampling (GOSS) to speed 🐇 up the finding of optimal split points.
CatBoost (Categorical Boosting)
⭐️Developed by Yandex, this algorithm is specifically optimized for handling ‘categorical’ features without requiring extensive preprocessing (such as, one-hot encoding).
⭐️An optimized and highly efficient implementation of gradient boosting.
👉 Widely used in competitive data science (like Kaggle) due to its speed and performance.
Note: Research project developed by Tianqi Chen during his doctoral studies at the University of Washington.
Algorithmic Optimizations
🔵 Second order Derivative 🔵 Regularization 🔵 Sparsity-Aware Split Finding
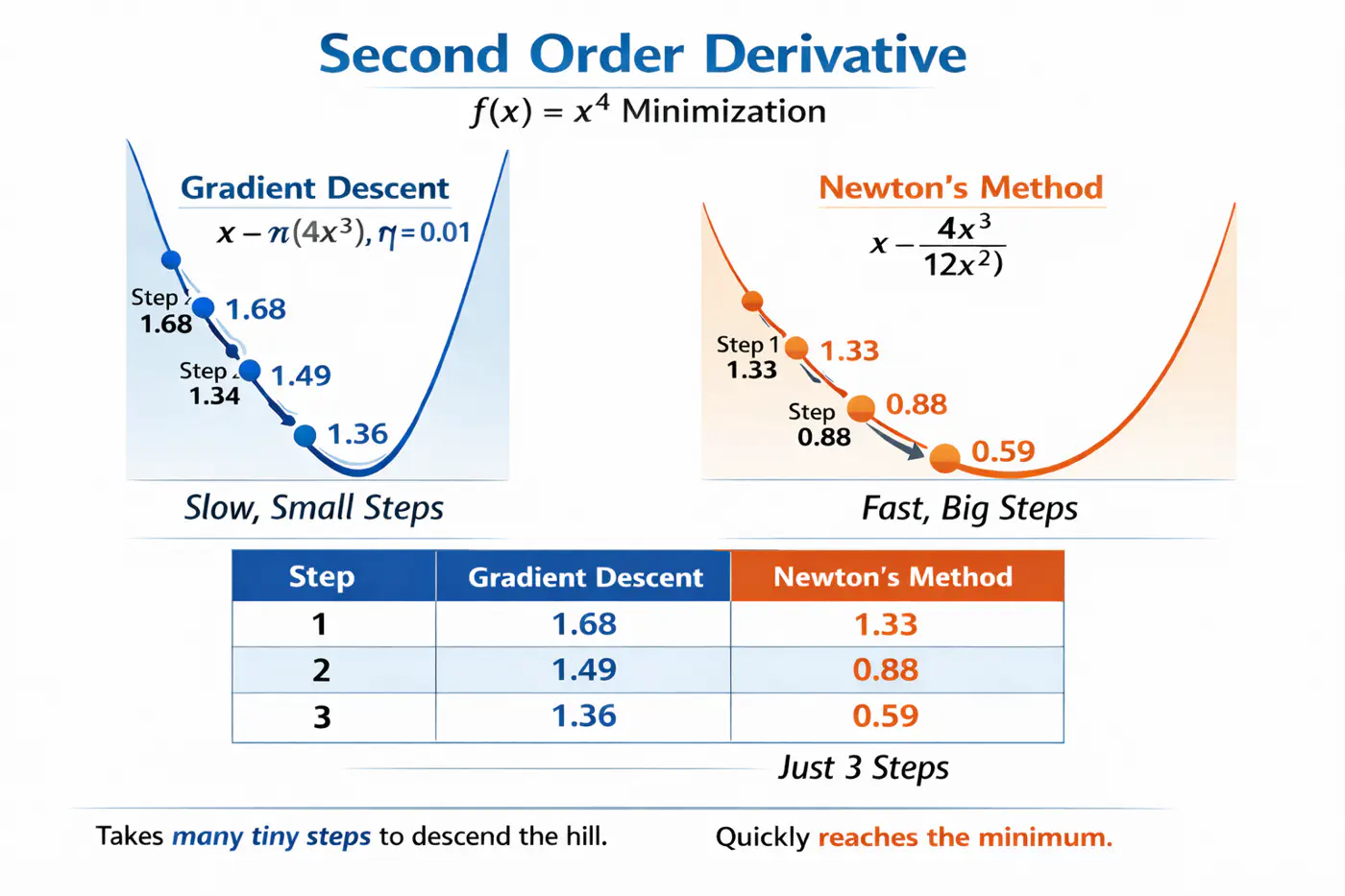
Second order Derivative
⭐️Uses second derivative (Hessian), i.e, curvature, in addition to first derivative (gradient) to optimize the objective function more quickly and accurately than GBDT.
Let’s understand this with the problem to minimize \(f(x) = x^4\), using:
Gradient descent (uses only 1st order derivative, \(f'(x) = 4x^3\))
Newton’s method (uses both 1st and 2nd order derivatives \(f''(x) = 12x^2\))
Regularization
Adds explicit regularization terms (L1/L2 on leaf weights and tree complexity) into the boosting objective, helping reduce over-fitting.
\[
\text{Objective} = \underbrace{\sum_{i=1}^{n} L(y_i, \hat{y}_i)}_{\text{Training Loss}} + \underbrace{\gamma T + \frac{1}{2}\lambda \sum_{j=1}^{T} w_j^2 + \alpha \sum_{j=1}^{T} |w_j|}_{\text{Regularization (The Tax)}}
\]
Sparsity-Aware Split Finding
💡Real-world data often contains many missing values or zero-entries (sparse data).
👉 XGBoost introduces a ‘default direction’ for each node.
➡️During training, it learns the best direction (left or right) for missing values to go, making it significantly faster and more robust when dealing with sparse or missing data.
⭐️Developed by Microsoft, this framework is designed for high speed and efficiency with large datasets.
👉It grows trees leaf-wise rather than level-wise and uses Gradient-based One-Side Sampling (GOSS) to speed 🐇 up the finding of optimal split points.
Algorithmic Optimizations
🔵 Gradient-based One Side Sampling (GOSS) 🔵 Exclusive Feature Bundling (EFB) 🔵 Leaf-wise Tree Growth Strategy
Gradient-based One Side Sampling (GOSS)
❌ Traditional GBDT uses all data instances for gradient calculation, which is inefficient.
✅ GOSS focuses 🔬on instances with larger gradients (those that are less well-learned or have higher error).
🐛 Keeps all instances with large gradients but randomly samples from those with small gradients.
🦩This way, it prioritizes the most informative examples for training, significantly reducing the data used and speeding up 🐇 the process while maintaining accuracy.
Exclusive Feature Bundling (EFB)
🦀 High-dimensional data often contains many sparse, mutually exclusive features (features that never take a non-zero value simultaneously, such as, One Hot Encoding (OHE)).
💡 EFB bundles the non-overlapping features into a single, dense feature, reducing the number of features, without losing much information, saving computation.
Leaf-wise Tree Growth Strategy
❌ Traditional gradient boosting machines (like XGBoost), the trees are built level-wise (BFS-like), meaning all nodes at the current level are split before moving to the next level.
✅ LightGBM maintains a set of all potential leaves that can be split at any given time and selects the leaf (for splitting) that provides the maximum gain across the entire tree, regardless of its depth.
⭐️Developed by Yandex, this algorithm is specifically optimized for handling ‘categorical’ features without requiring extensive preprocessing (such as, one-hot encoding).
❌ Standard target encoding can lead to target leakage, where the model uses information from the target variable during training that would not be available during inference. 👉(model ‘cheats’ by using a row’s own label to predict itself).
✅ CatBoost calculates the target statistics (average target value) for each category based only on the
history of previous training examples in a random permutation of the data.
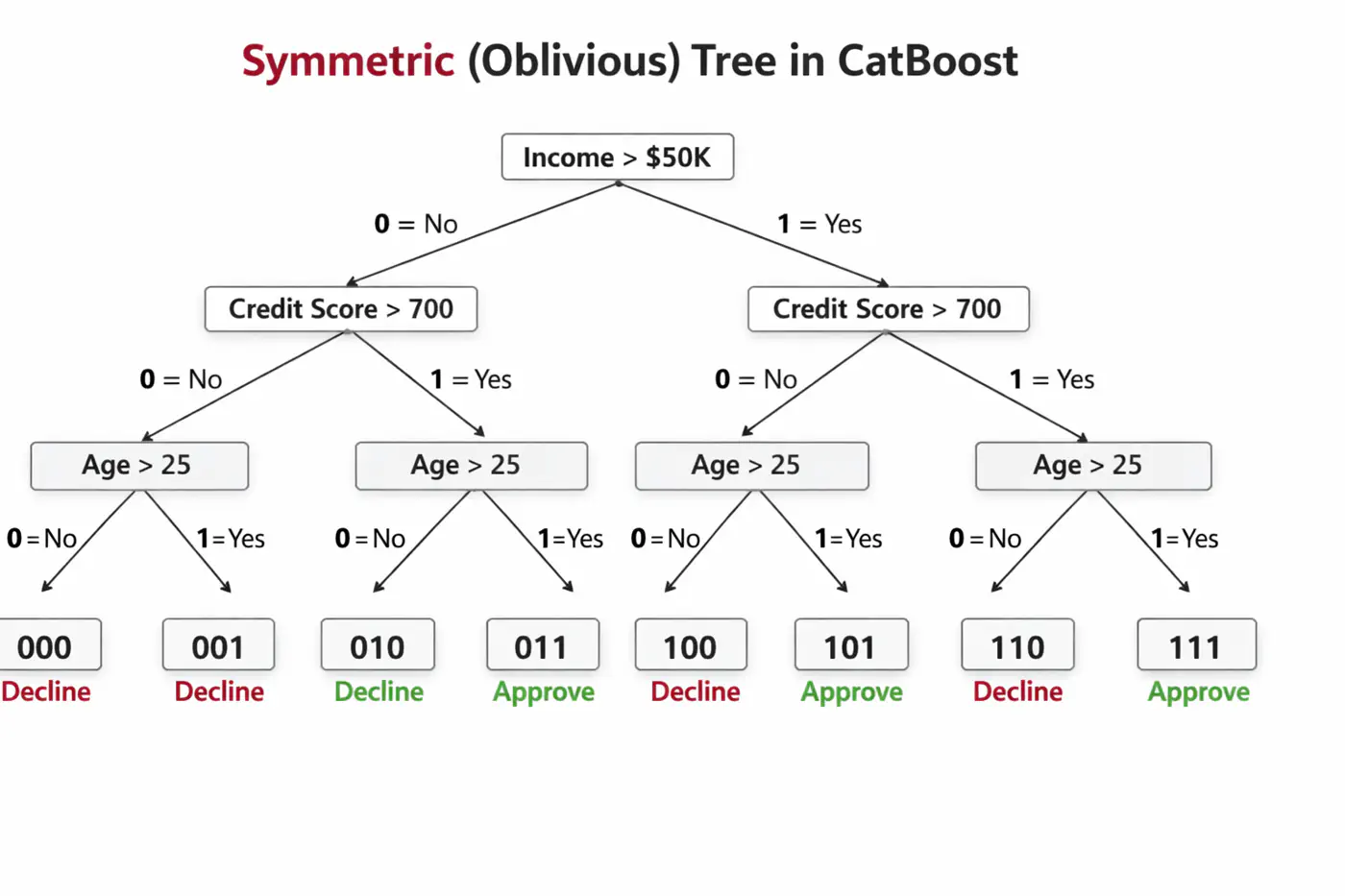
Symmetric (Oblivious) Trees
🦋 Uses symmetric decision trees by default. 👉 In symmetric trees, the same split condition is applied at each level across the entire tree structure.
🦘Does not walk down the tree using ‘if-else’ logic, instead it evaluates decision conditions to create a binary
index (e.g 101) and jumps directly to that leaf 🍃 in memory 🧠.
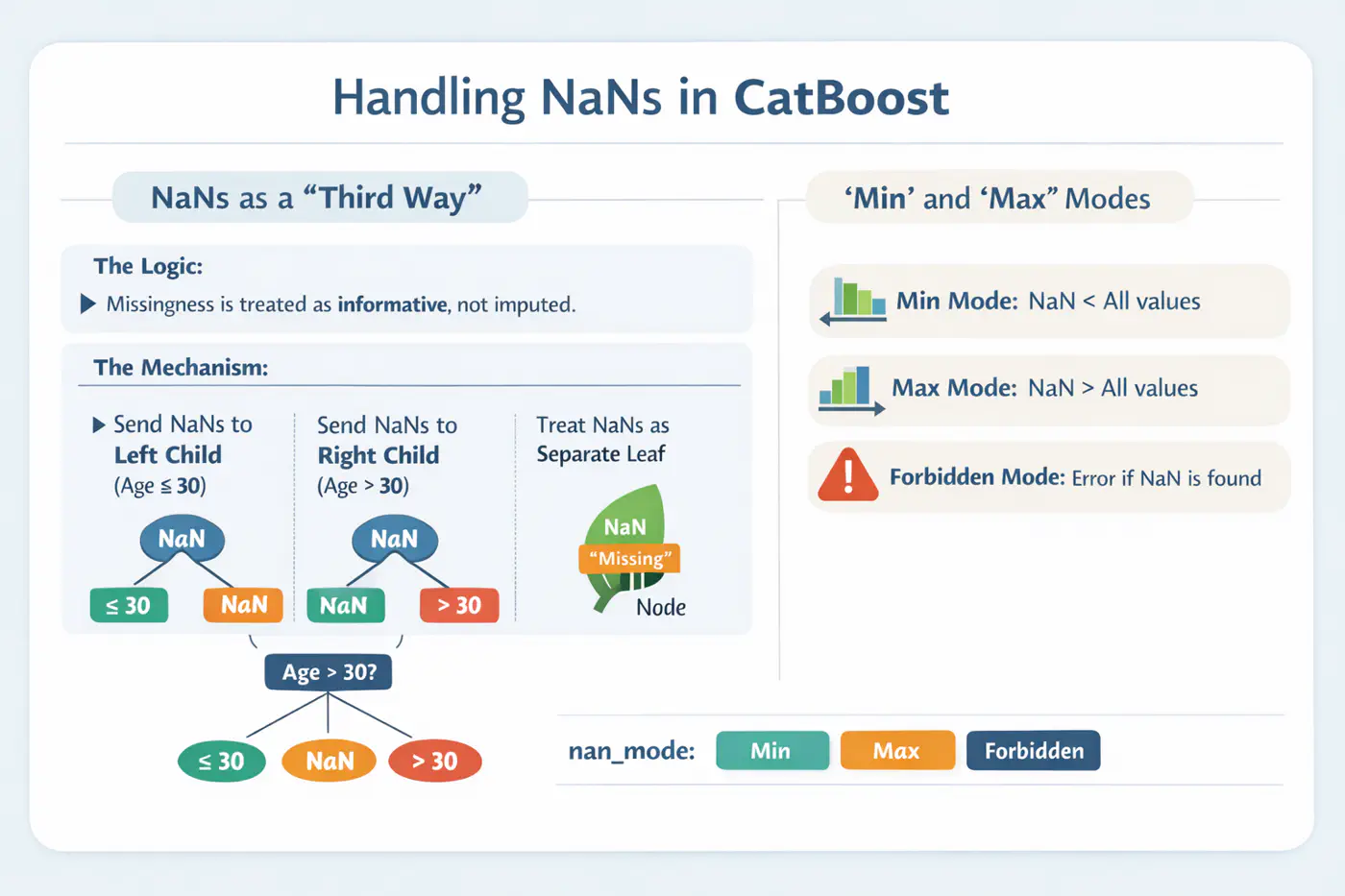
Handling Missing Values
⚙️ CatBoost offers built-in, intelligent handling of missing values and sparse features, which often require manual preprocessing in other GBDT libraries.
💡Treats ‘NaN’ as a distinct category, reducing the need for imputation.
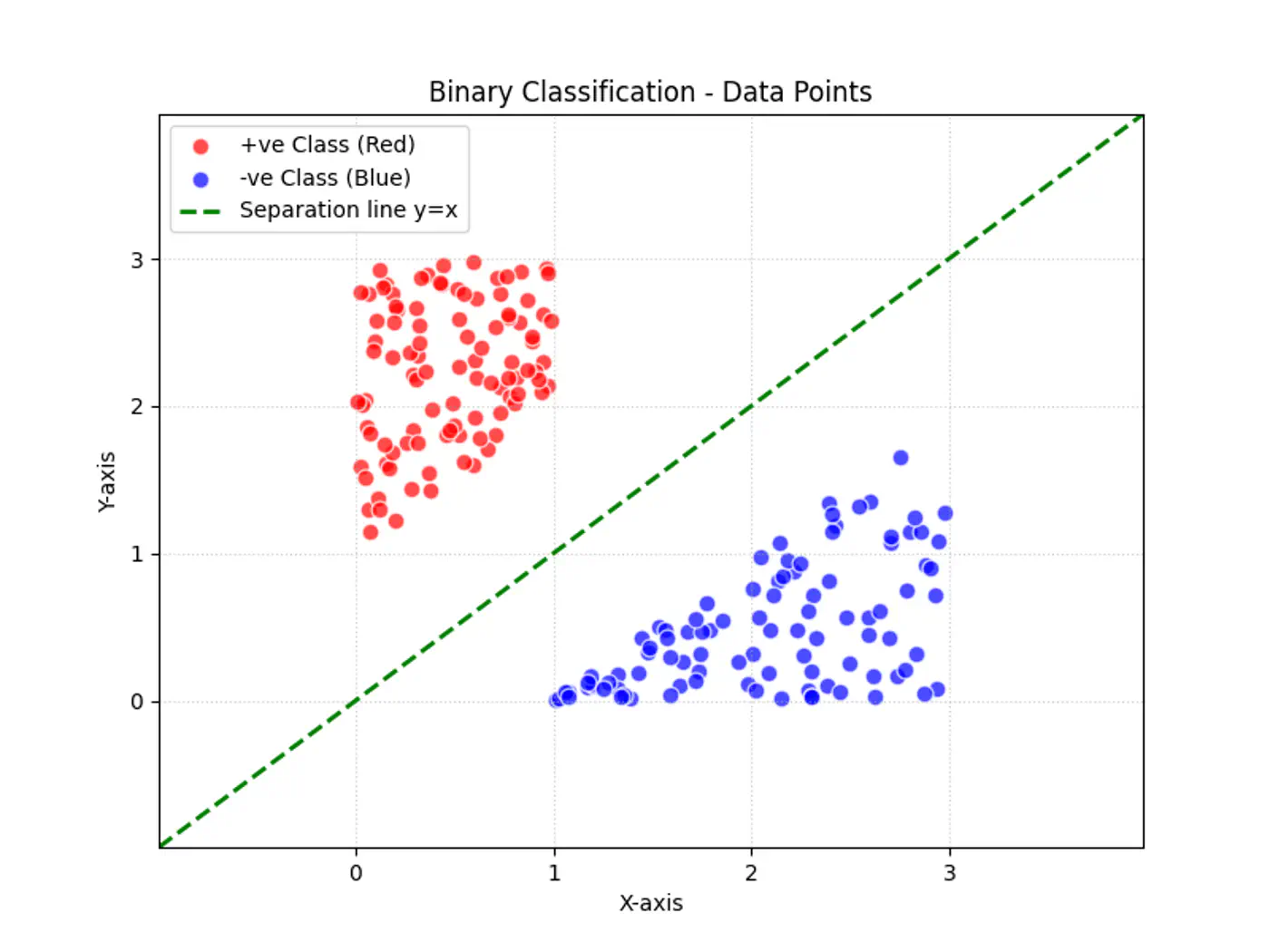
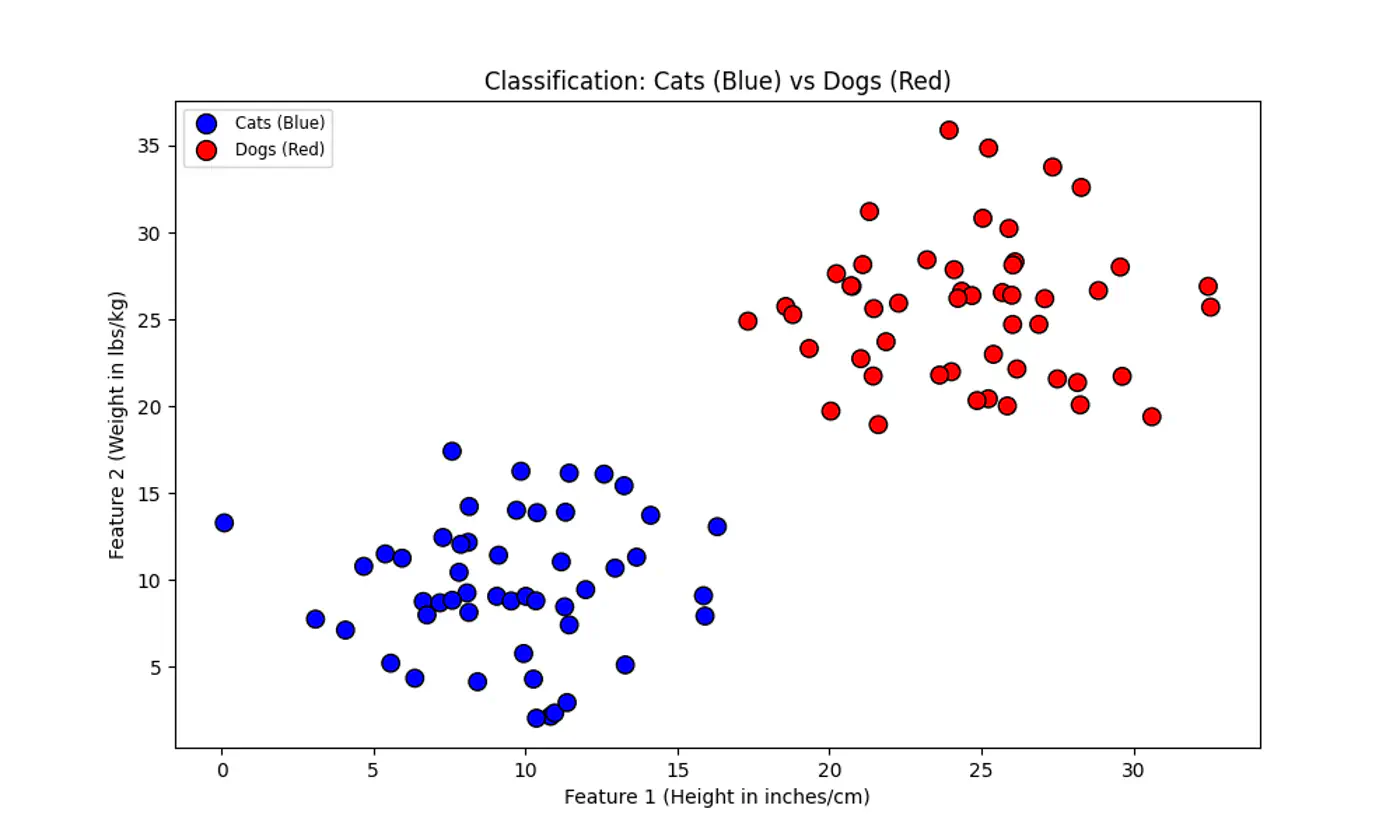
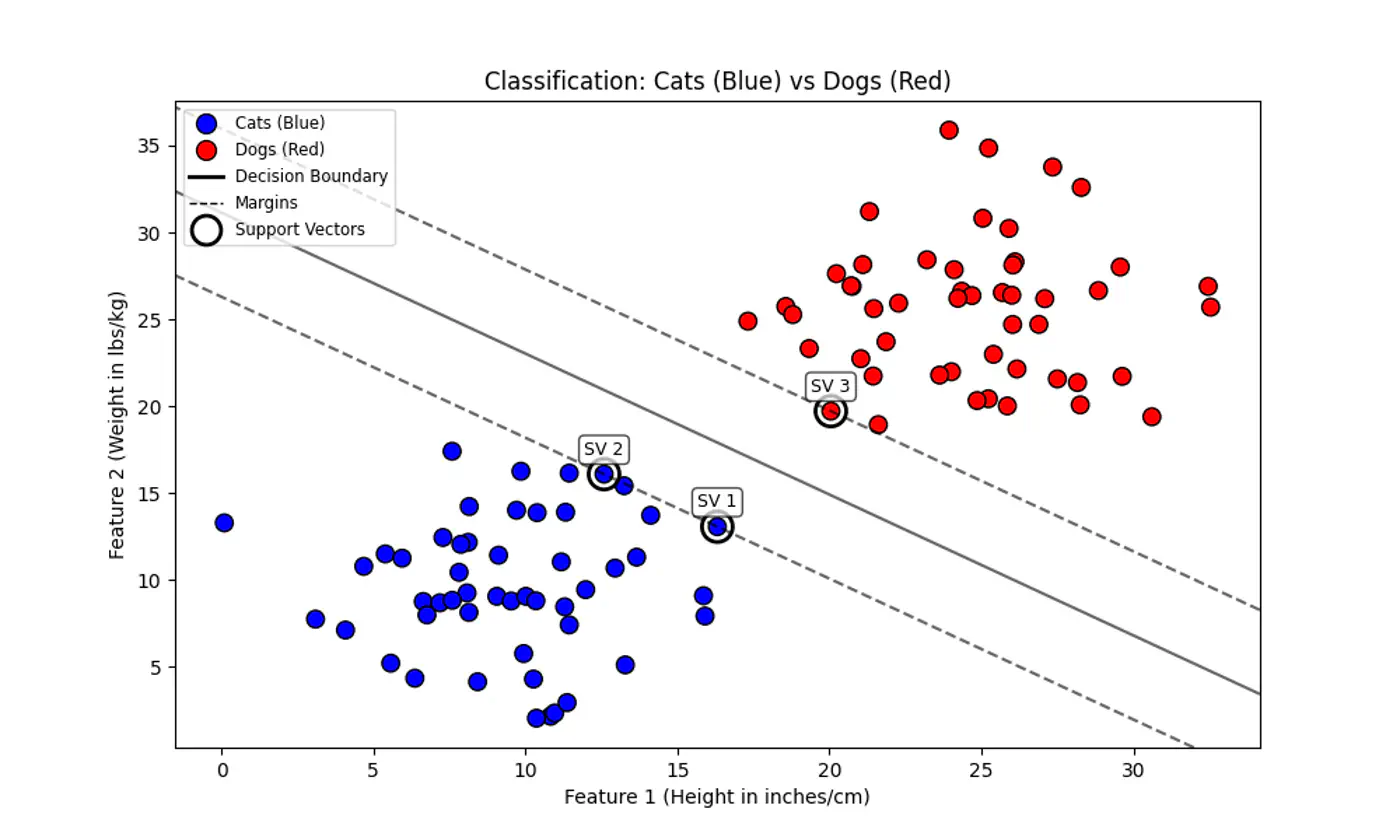
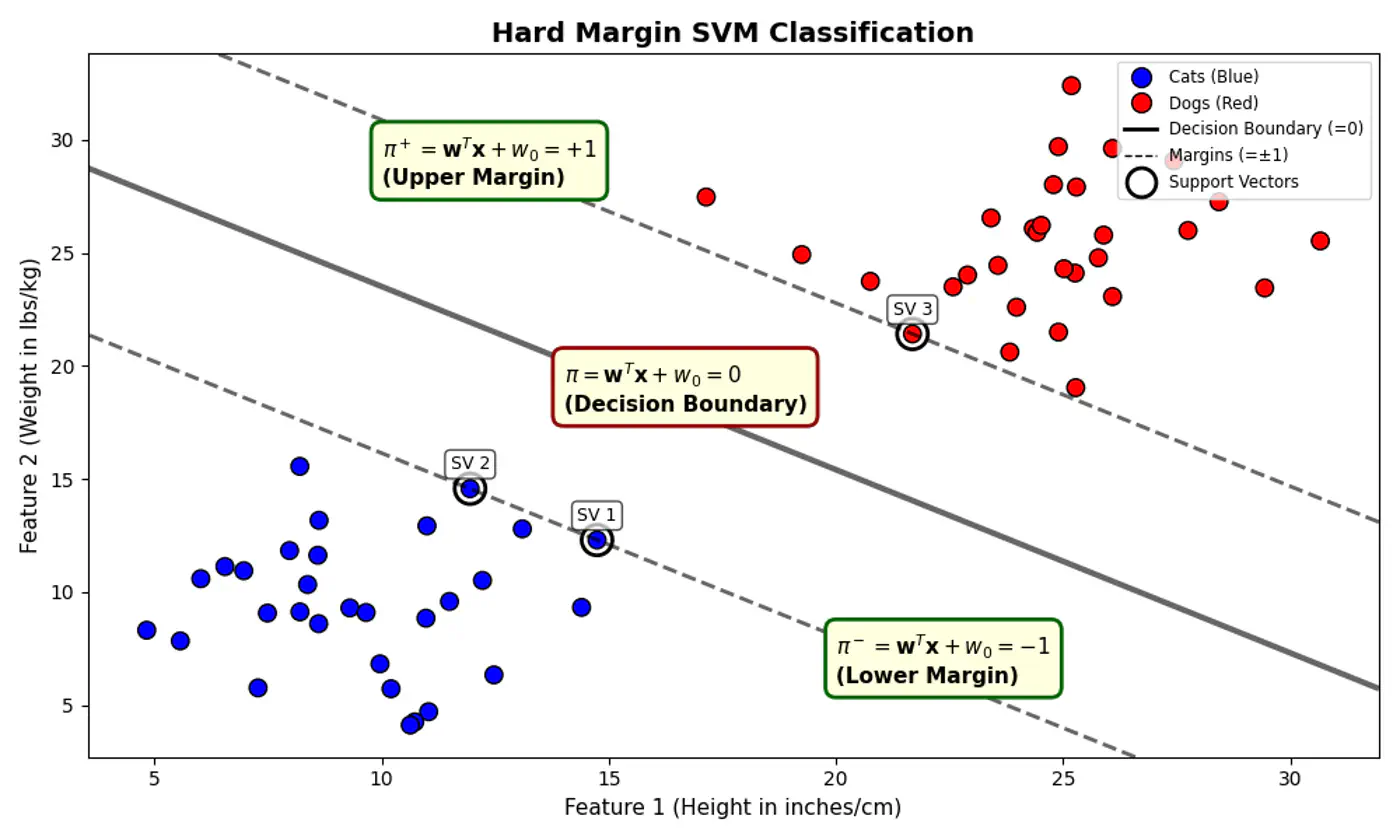
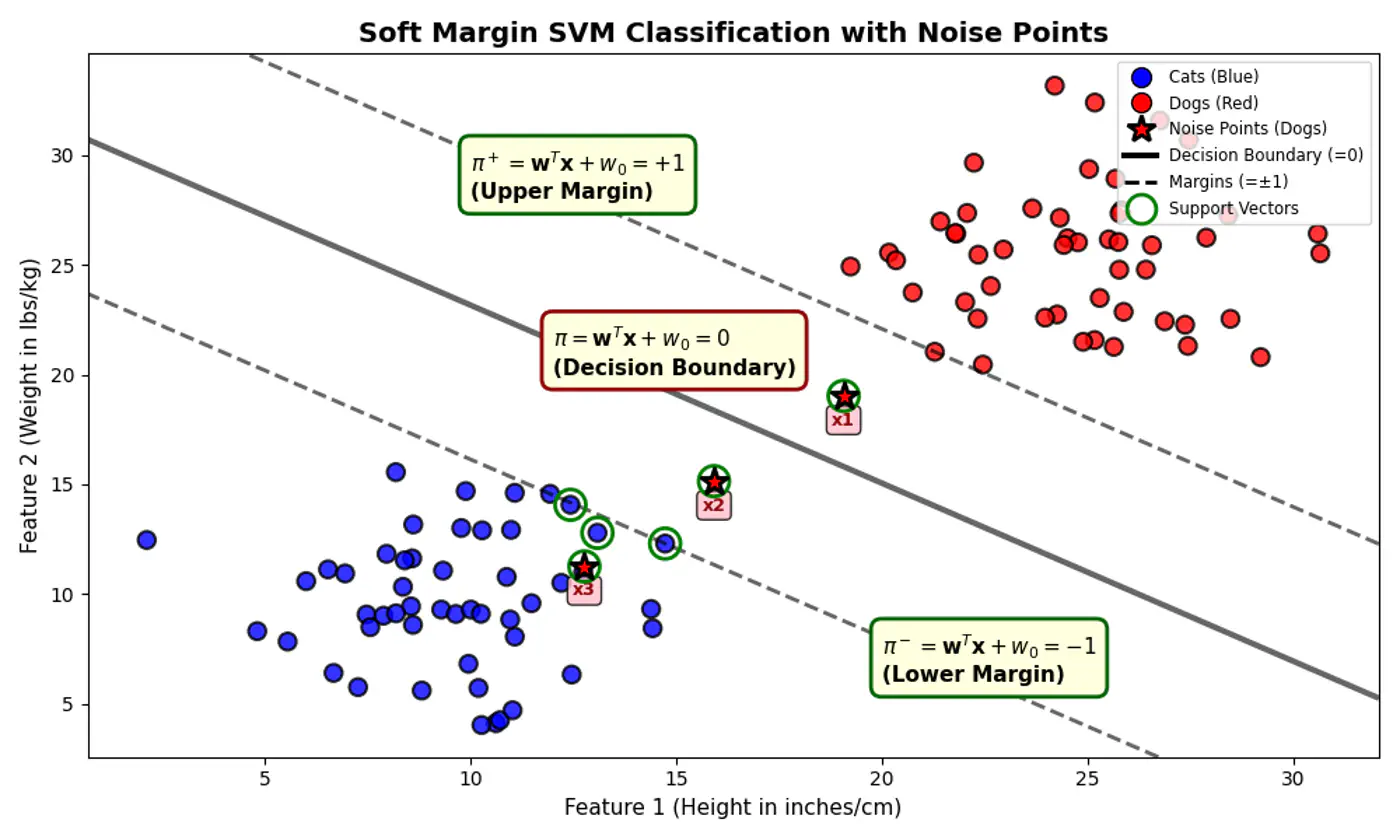
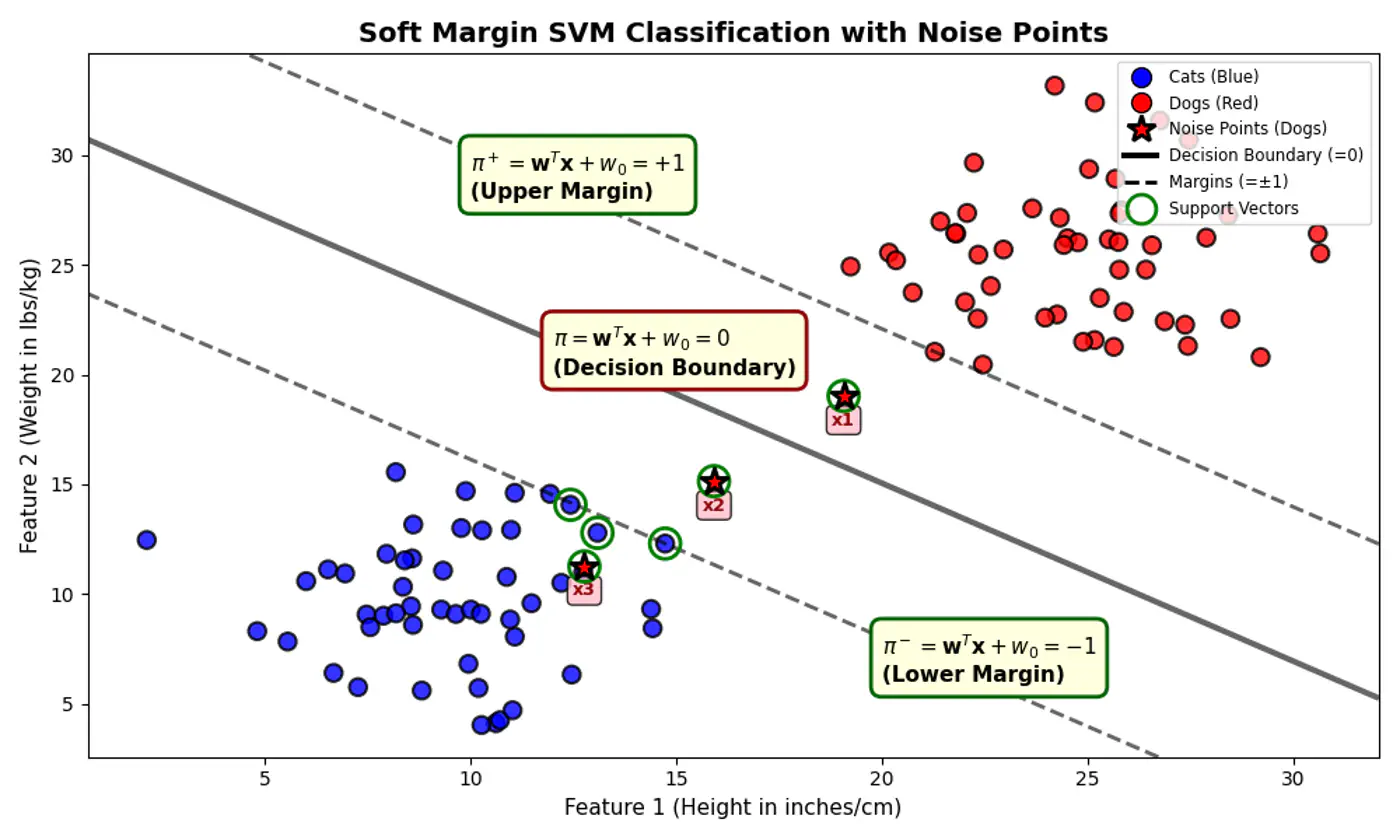
Data is perfectly linearly separable, i.e, there must exist a hyperplane that can perfectly separate the data into two distinct classes without any misclassification.
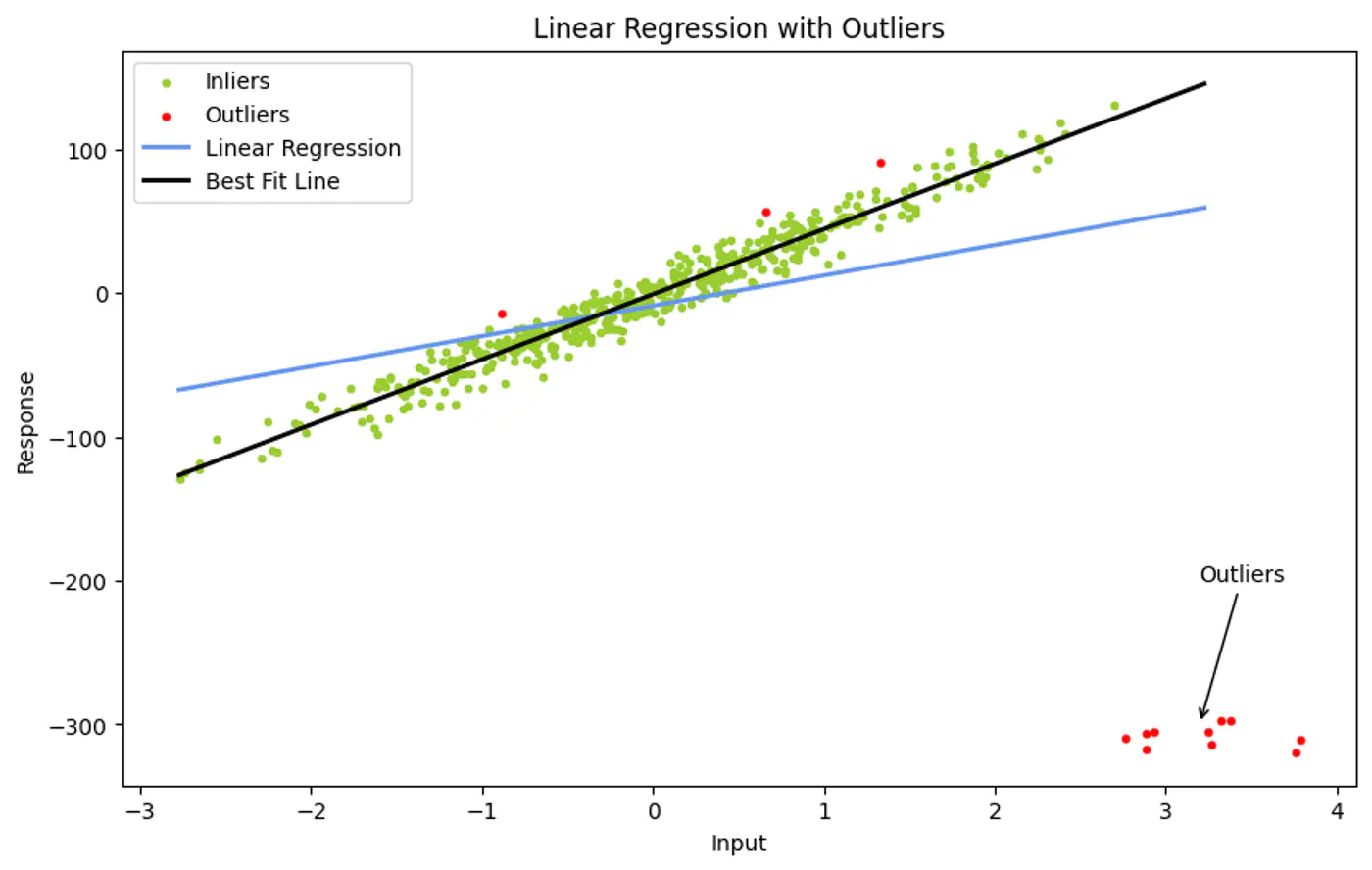
No noise or outliers that fall within the margin or on the wrong side of the decision boundary. Note: Even a single outlier can prevent the algorithm from finding a valid solution or drastically affect the boundary’s position, leading to poor generalization.
Hard Margin: fence is made of steel. Nothing can cross it.
Soft Margin: fence is made of rubber(porous). Some points can ‘push’ into the margin or even cross over to the wrong side, but we charge them a penalty 💵 for doing so.
Issue
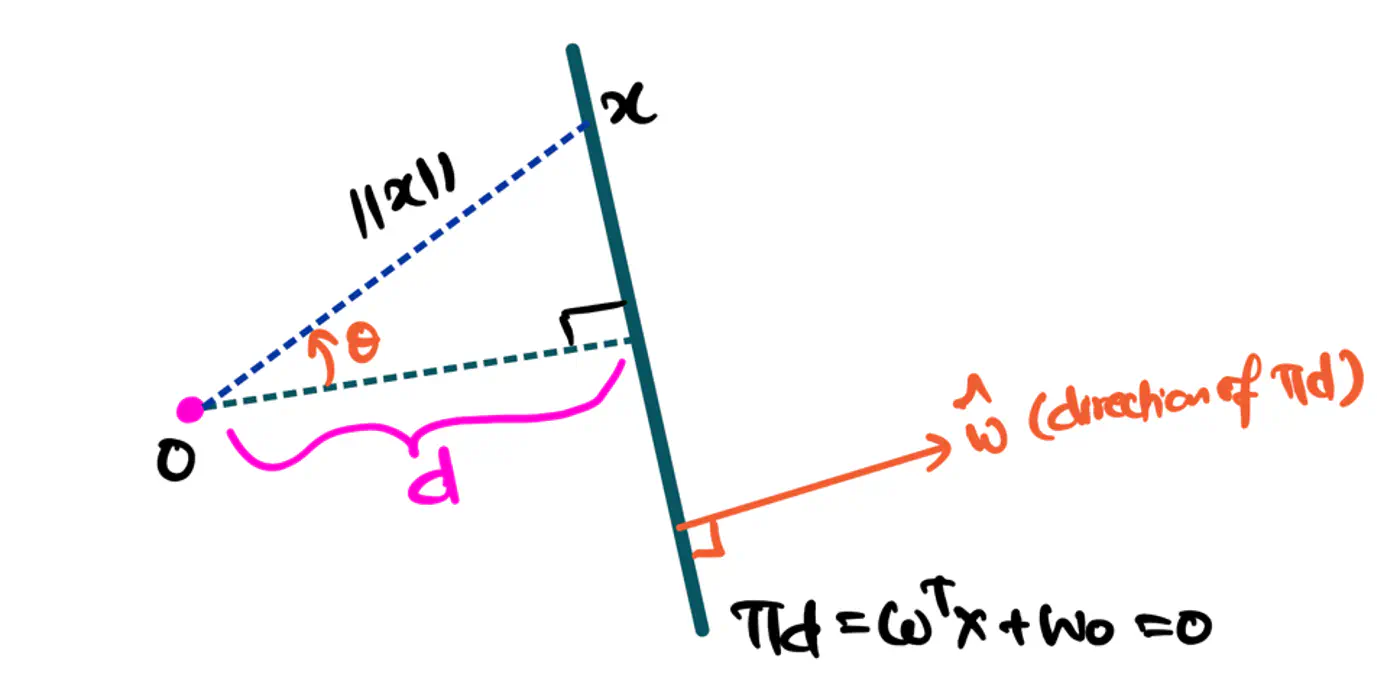
Distance from decision boundary:
Distance of positive labelled points must be \(\ge 1\)
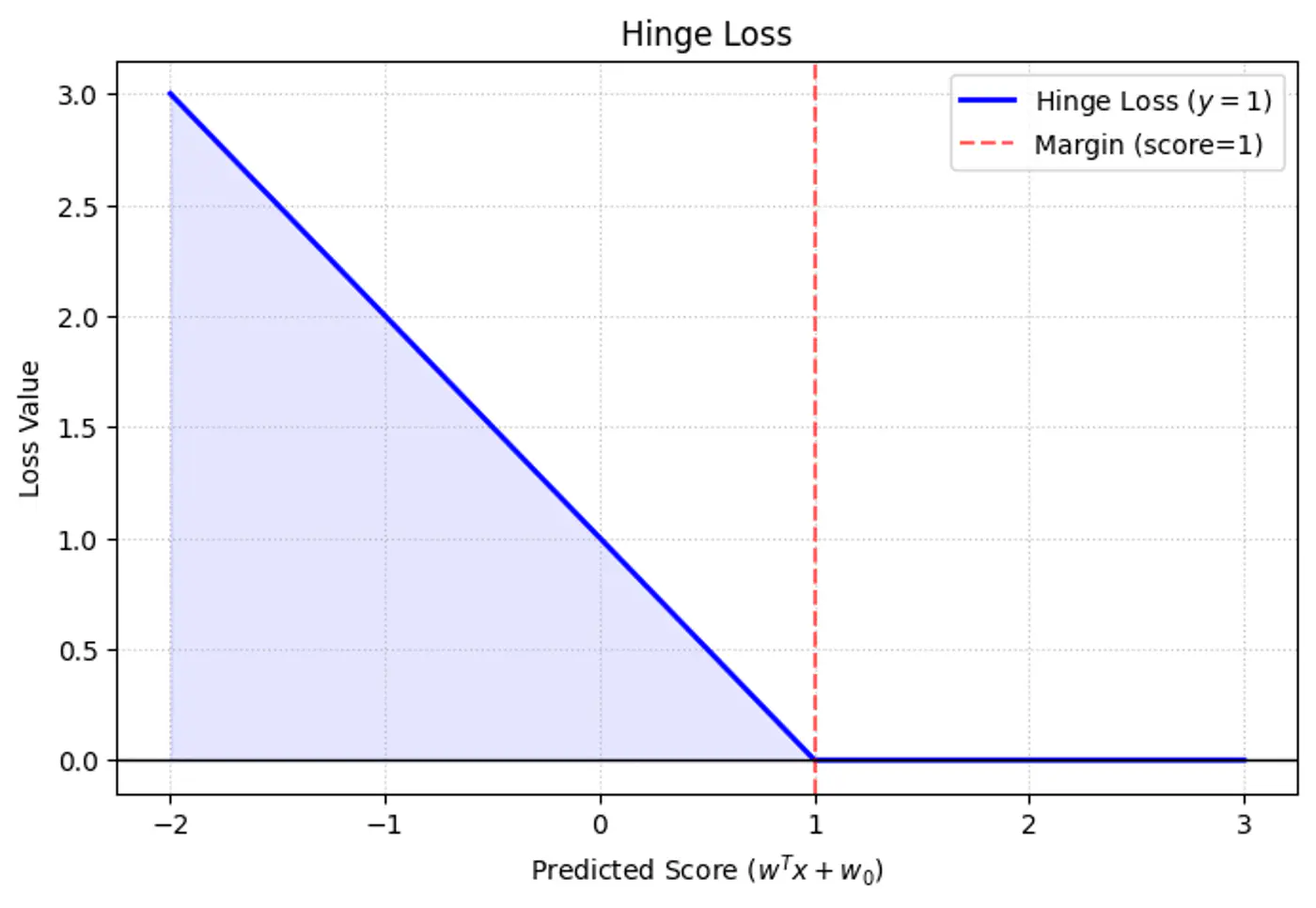
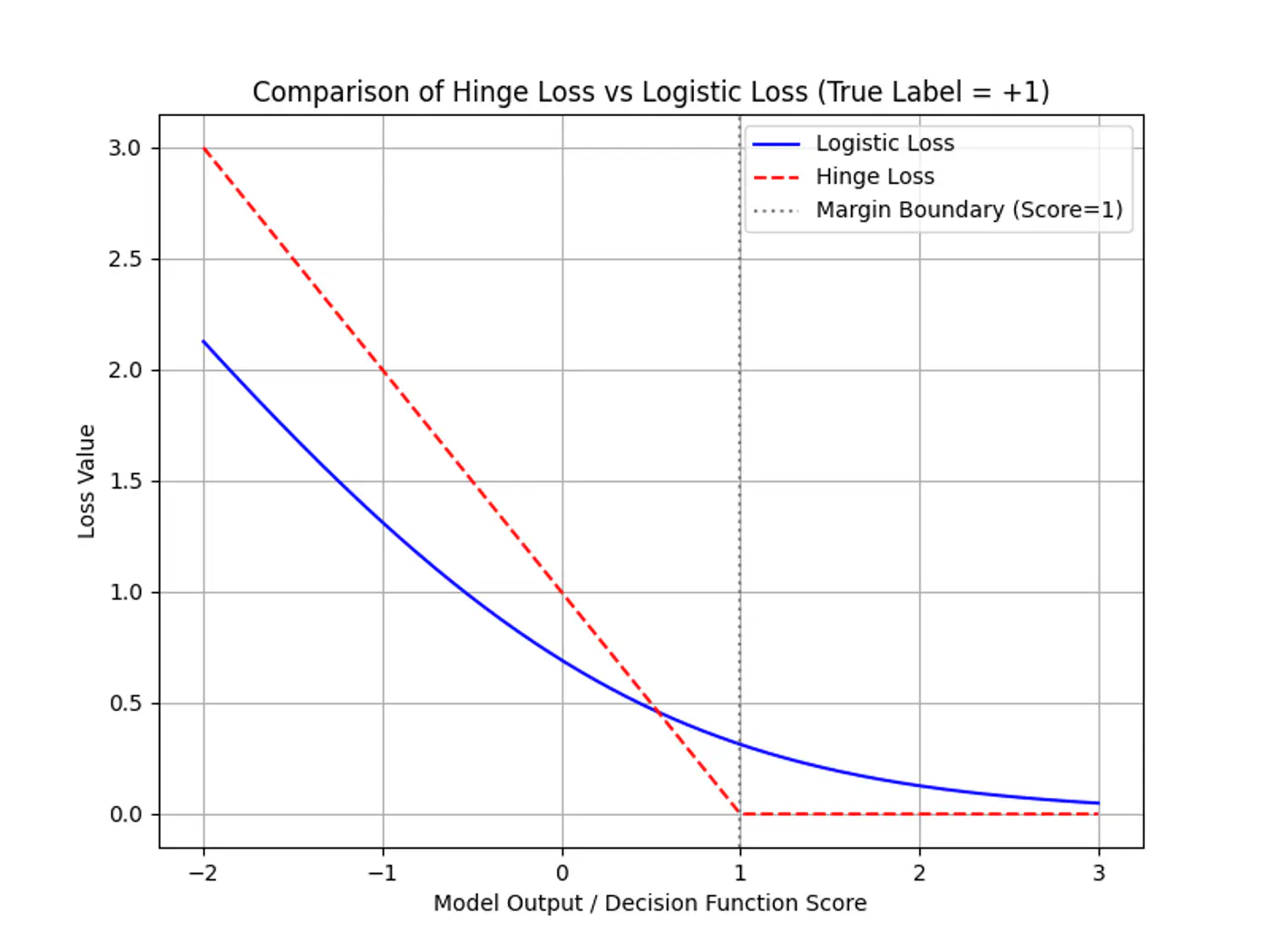
Minimization: We want to minimize \(L(w, w_0, \xi, \alpha, \mu)\) w.r.t primal variables (\(w, w_0, \xi_i \) ) to find the hyperplane with the largest possible margin.
Maximization: We want to maximize \(L(w, w_0, \xi, \alpha, \mu)\) w.r.t dual variables (\(\alpha_i, \mu_i\) ) to ensure all training constraints are satisfied.
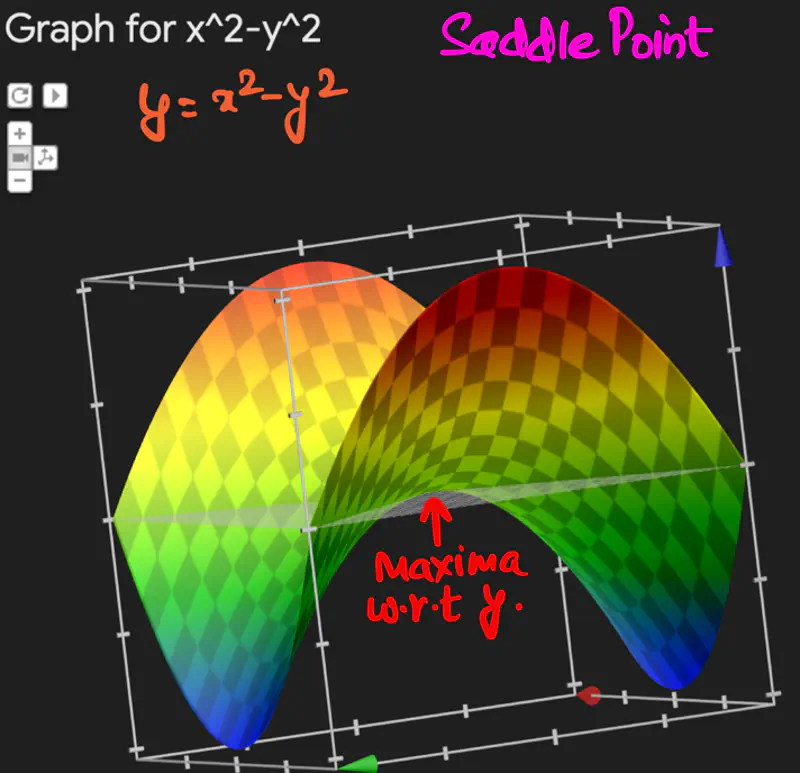
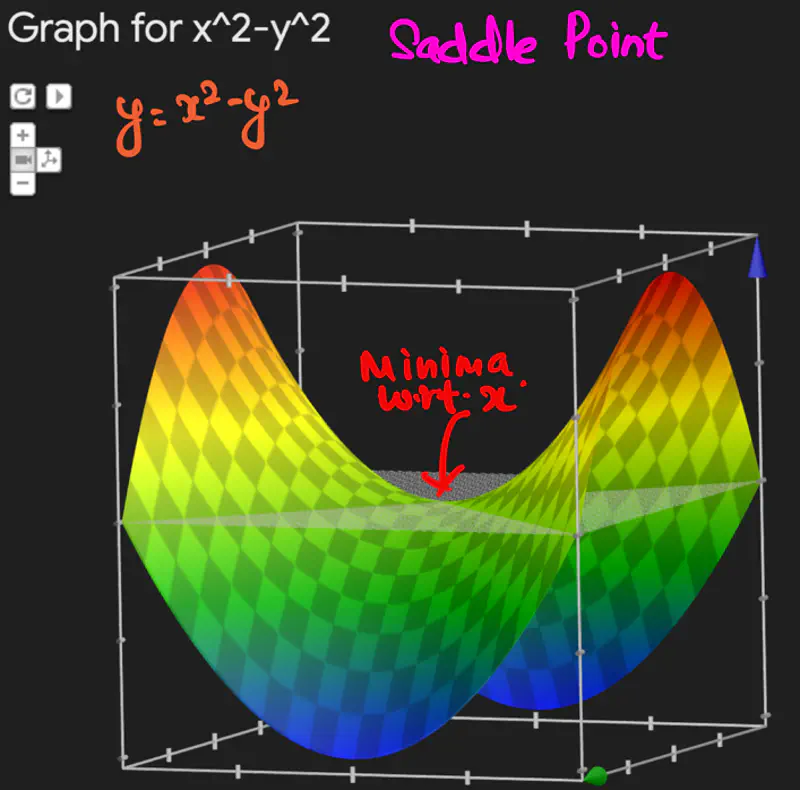
Note: A point that is simultaneously a minimum for one set of variables and a maximum for another is, by definition,
a saddle point.
Karush–Kuhn–Tucker (KKT) Conditions
👉To find the Dual, we find the saddle point by taking partial derivatives with respect to the primal variables \((w, w_0, \xi)\)
and equating them to 0.
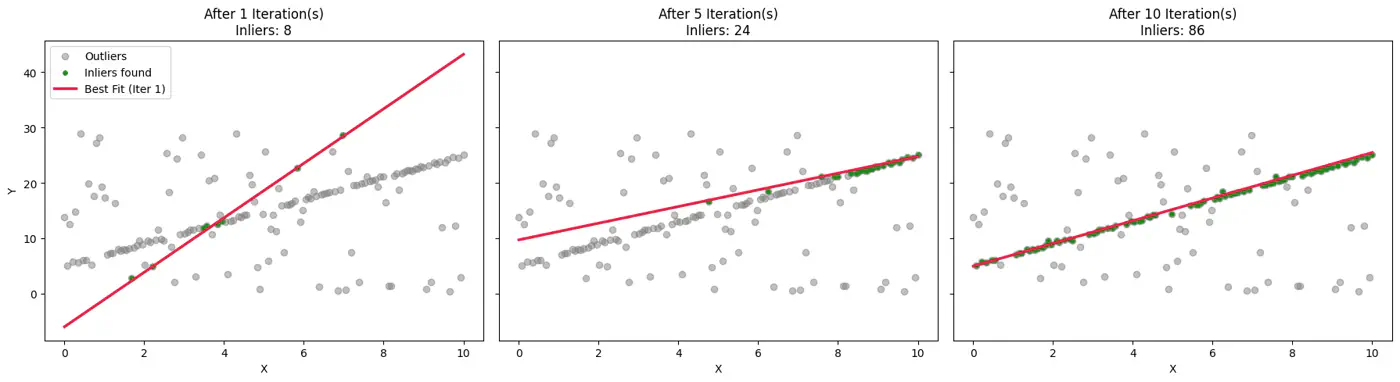
Note: Even if you have 1 million training points, if only 500 are support vectors, the summation only runs for 500 terms. All other points have \(\alpha_i = 0\) and vanish.
👉If our data is not linearly separable in its original space , we can map it to a higher-dimensional feature space
(where D»d) using a transformation function .
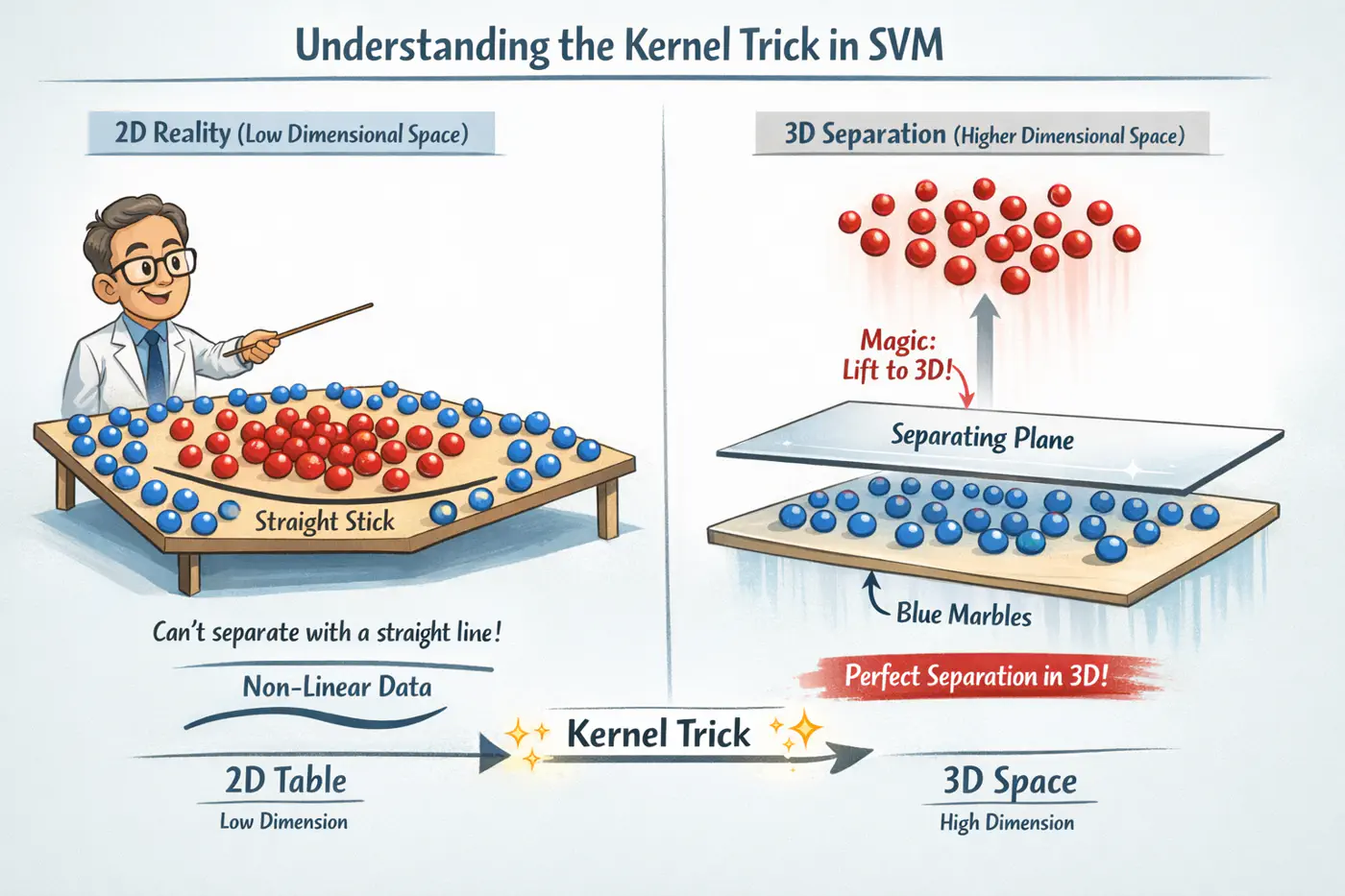
Kernel Trick 🪄
Bridge between Dual formulation and the geometry of high dimensional spaces.
It is a way to manipulate inner product spaces without the computational cost 💰 of explicit transformation.
👉The ‘shape’ of the decision boundary is entirely determined by how similar points are to one another, not by their absolute coordinates.
Non-Linear Separation
If our data is not linearly separable in its original space \(\mathbb{R}^d\), we can map it to a higher-dimensional
\(\mathbb{R}^D\) feature space (where D»d) using a transformation function \(\phi(x)\) .
Problem 🤔
If we choose a very high-dimensional mapping (e.g. \(D = 10^6\) or \(D = \infty\) ), calculating and then performing
the dot product \(\phi(x_i)^T \phi(x_j)\) becomes computationally impossible or extremely slow.
Kernel Trick 👻
So we define a function called ‘Kernel Function’.
The ‘Kernel Trick’ 🪄 is an optimization that replaces the dot product of a high-dimensional mapping with
a function of the dot product in the original space.
Instead of mapping (to higher dimension) \(x_i \rightarrow \phi(x_i)\), \(x_j \rightarrow \phi(x_j)\),
and calculating the dot product. We simply compute \(K(x_i, x_j)\) directly in the original input space.
👉The ‘Kernel Function’ gives the similar mathematical equivalent of mapping it to a higher dimensions and taking the dot product.
Note: For \(K(x_i, x_j)\) to be a valid kernel, it must satisfy Mercer’s Condition.
Polynomial (Quadratic) Kernel
Below is an example for a quadratic Kernel function in 2D that is equivalent to mapping the vectors
to 3D and taking a dot product in 3D.
Important: The tensor product \(x\otimes x\) creates a vector (or matrix) containing all combinations of the features.
e.g. if \(x=[x_{1},x_{2}]\), then \(x\otimes x=[x_{1}^{2},x_{1}x_{2},x_{2}x_{1},x_{2}^{2}]\) 
Note: Because the Taylor series has an infinite number of terms, feature map has an infinite number of dimensions.
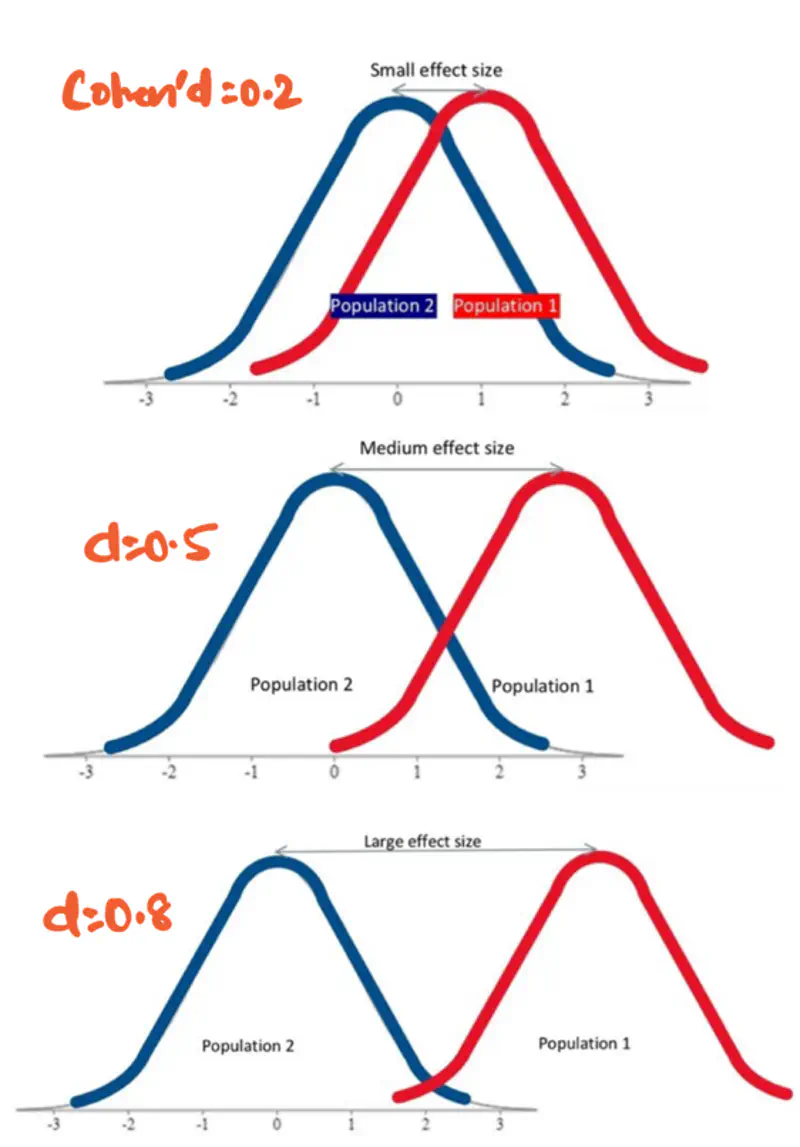
Bias-Variance Trade-Off ⚔️
High Gamma(low \(\sigma\)): Over-Fitting
Makes the kernel so ‘peaky’ that each support vector only influences its immediate neighborhood.
Decision boundary becomes highly irregular, ‘wrapping’ tightly around individual data points to ensure they are classified correctly.
Low Gamma(high \(\sigma\)): Under-Fitting
The Gaussian bumps are wide and flat.
Decision boundary becomes very smooth, essentially behaving more like a linear or low-degree polynomial classifier.
👉Imagine a ‘tube’ of radius \(\epsilon\) surrounding the regression line.
Points inside the tube are considered ‘correct’ and incur zero penalty.
Points outside the tube are penalized based on their distance from the tube’s boundary.
Ignore Errors
👉SVR ignores errors as long as they are within a certain distance (\(\epsilon\)) from the true value.
🎯This makes SVR inherently robust to noise and outliers, as it does not try to fit every single point perfectly,
only those that ‘matter’ to the structure of the data.
Note: Standard regression (like OLS) tries to minimize the squared error between the prediction and every data point.
➡️ For computing the joint distribution of say d=1000 words, we need to learn from possible \(2^{1000}\) combinations.
\(2^{1000}\) > the atoms in the observable 🔭 universe 🌌.
We will never have enough training data to see every possible combination of words even once.
Most combinations would have a count of zero.
🦉So, how do we solve this ?
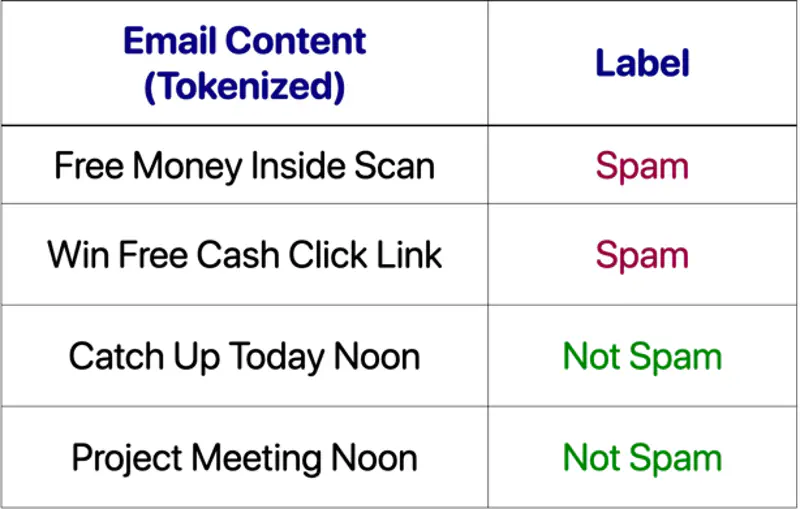
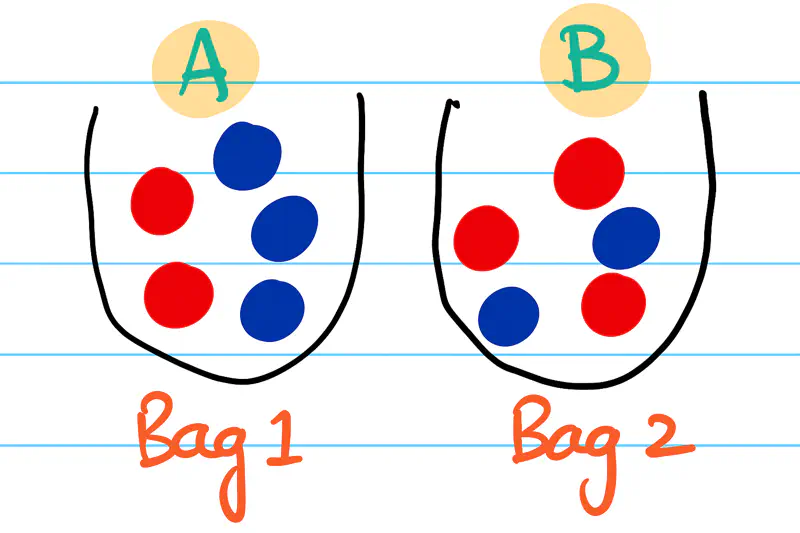
Naive Assumption
💡The ‘Naive’ assumption is a ‘Conditional Independence’ assumption, i.e, we assume each word appears independently of the others, given the class Spam/Not Spam.
e.g. In a spam email, the likelihood of ‘Free’ and ‘Money’ 💵 appearing are treated as independent events, even though they usually appear together.
Note: The conditional independence assumption makes the probability calculations easier, i.e, the joint probability
simply becomes the product of individual probabilities, conditional on the label.
We can generalize it for any number of class labels ‘y’:
\[\implies P(y|W) \propto \prod_{i=1}^d P(w_i|y)\times P(y) \quad \text{ where, y = class label} \]\[ P(w_i|y) = \frac{count(w_i ~in~ y)}{\text{total words in class y}} \]
Note: We compute the probabilities for both Spam/Not Spam and assign the final label to email, depending upon which probability is higher.
Note: Every point belongs to one and only one cluster.
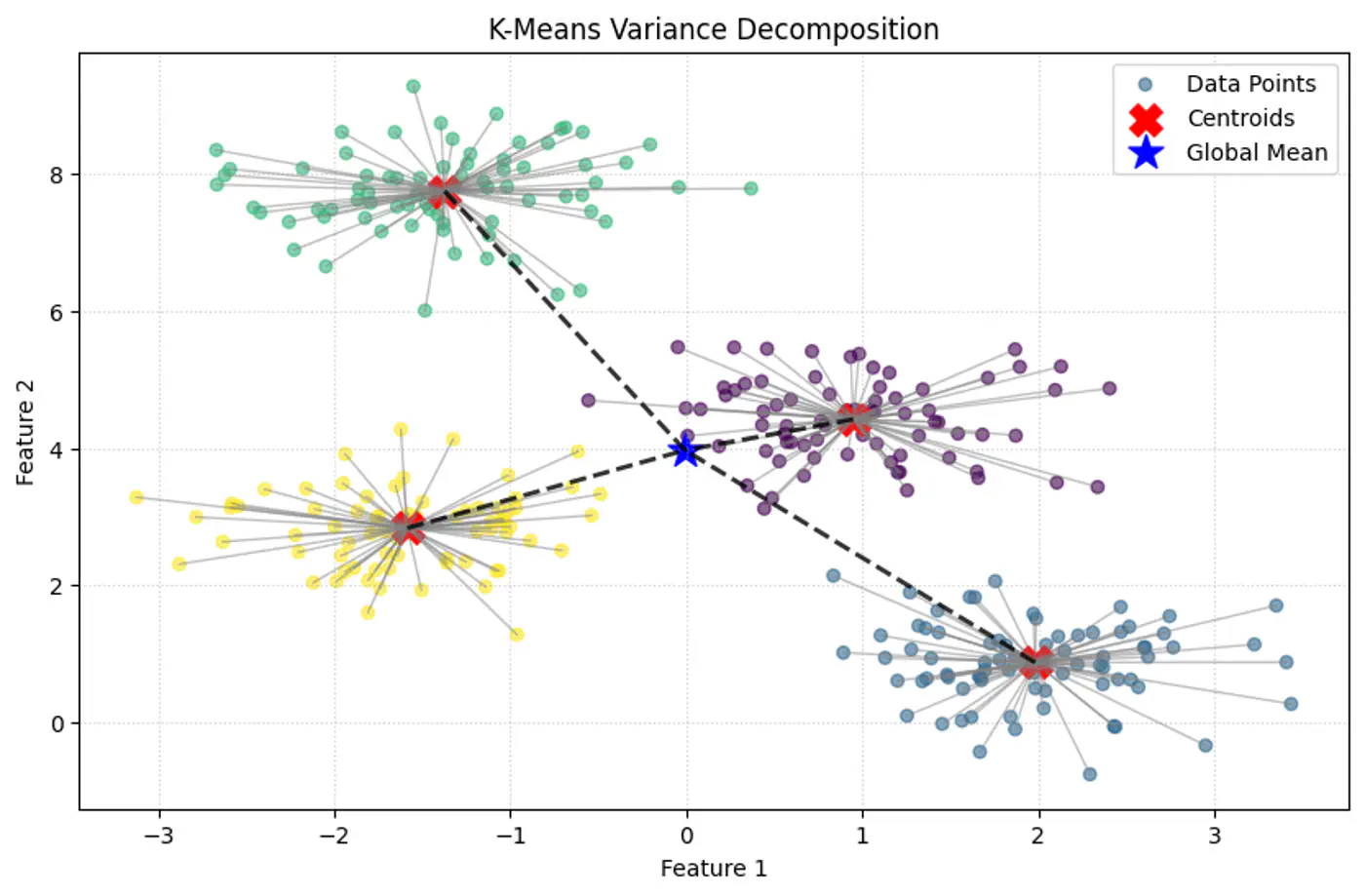
Variance Decomposition
💡Within-Cluster Sum of Squares (WCSS) is nothing but variance.
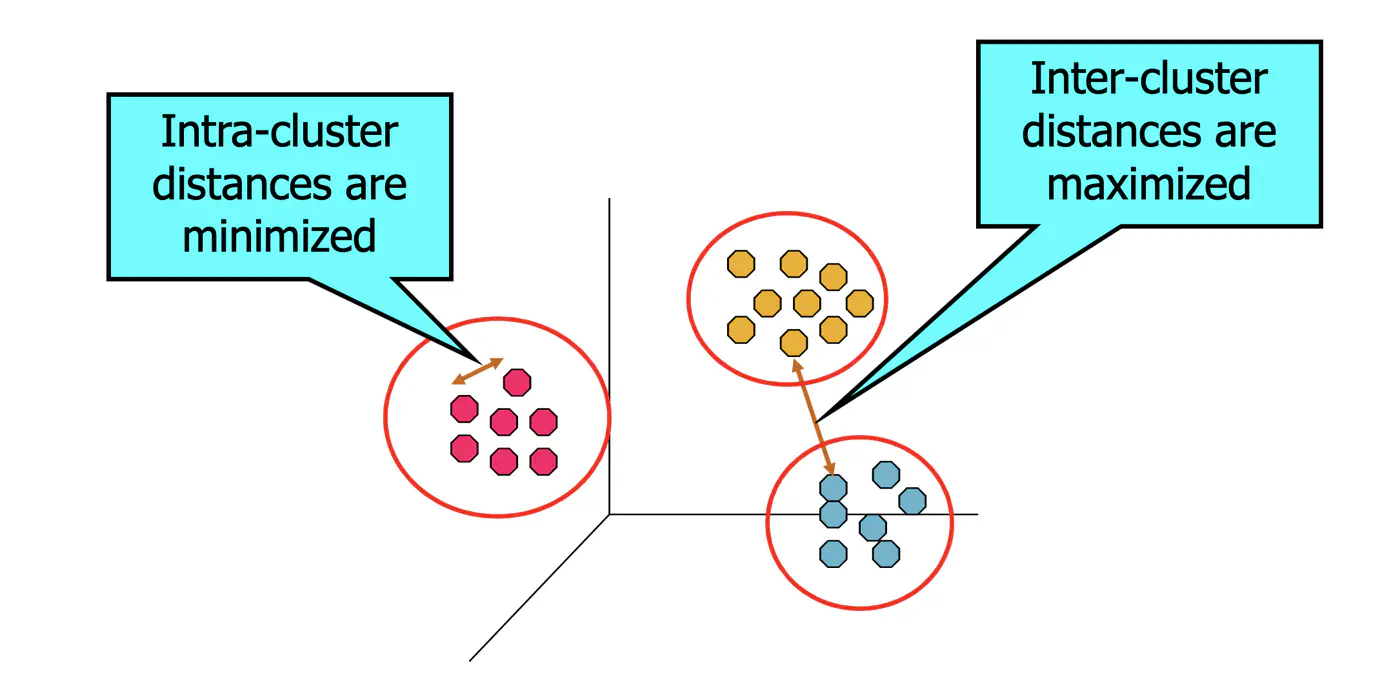
⭐️ Total Variance = Within-Cluster Variance + Between-Cluster Variance
👉K-Means minimizes within-Cluster variance, which implicitly maximizes between-cluster separation.
Geometric Interpretation:
Each point is ‘pulled’ toward its cluster center.
The objective measures total squared distance of all points to their centers.
Lower J(C, μ) means tighter, more compact clusters.
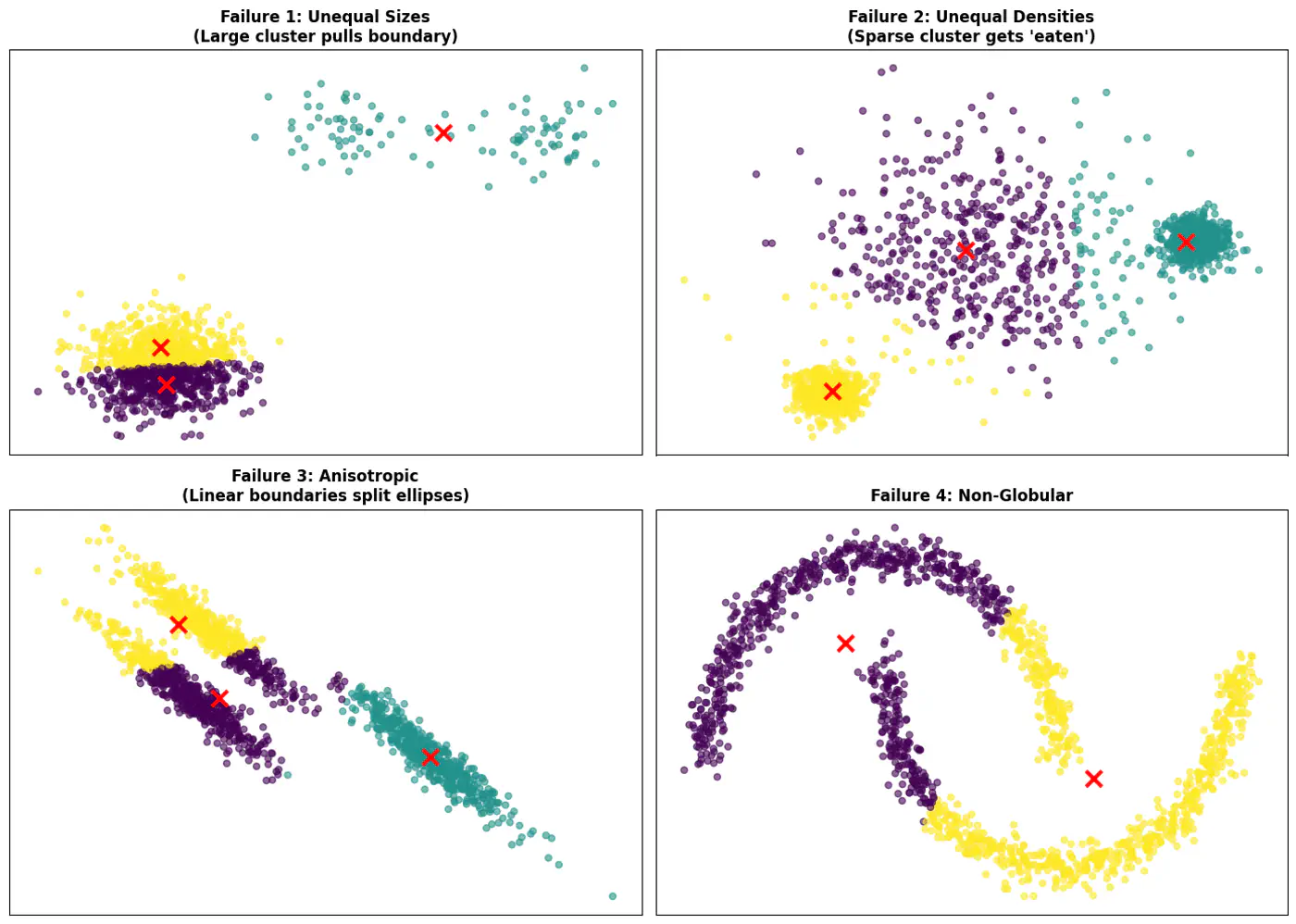
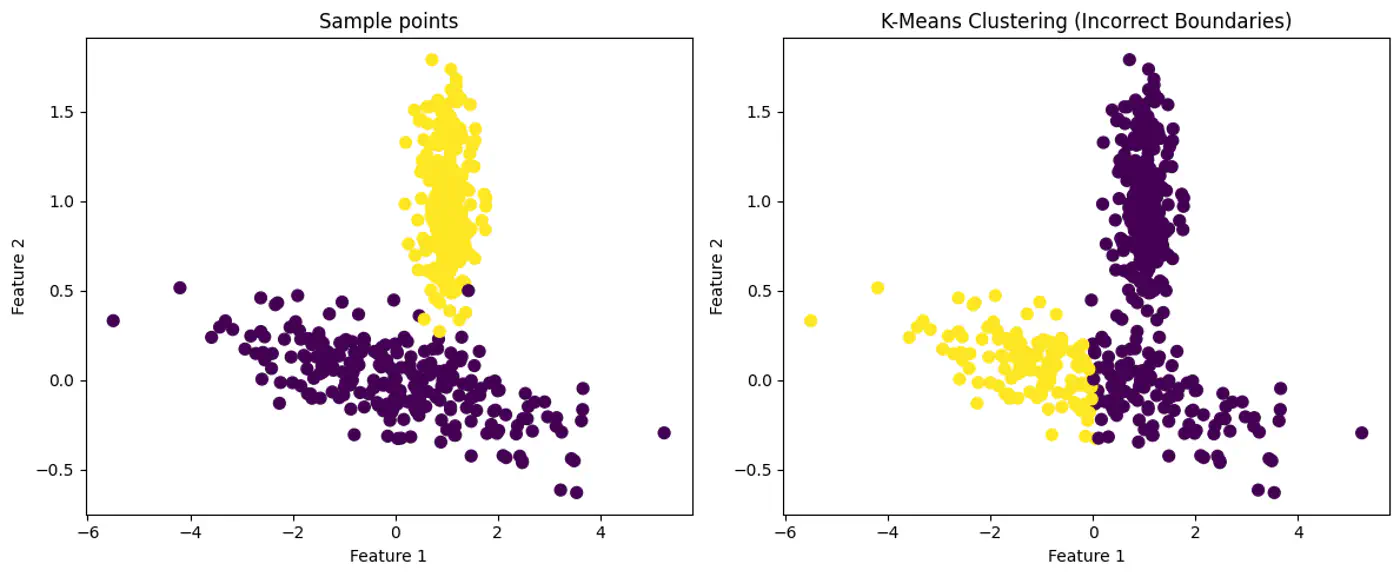
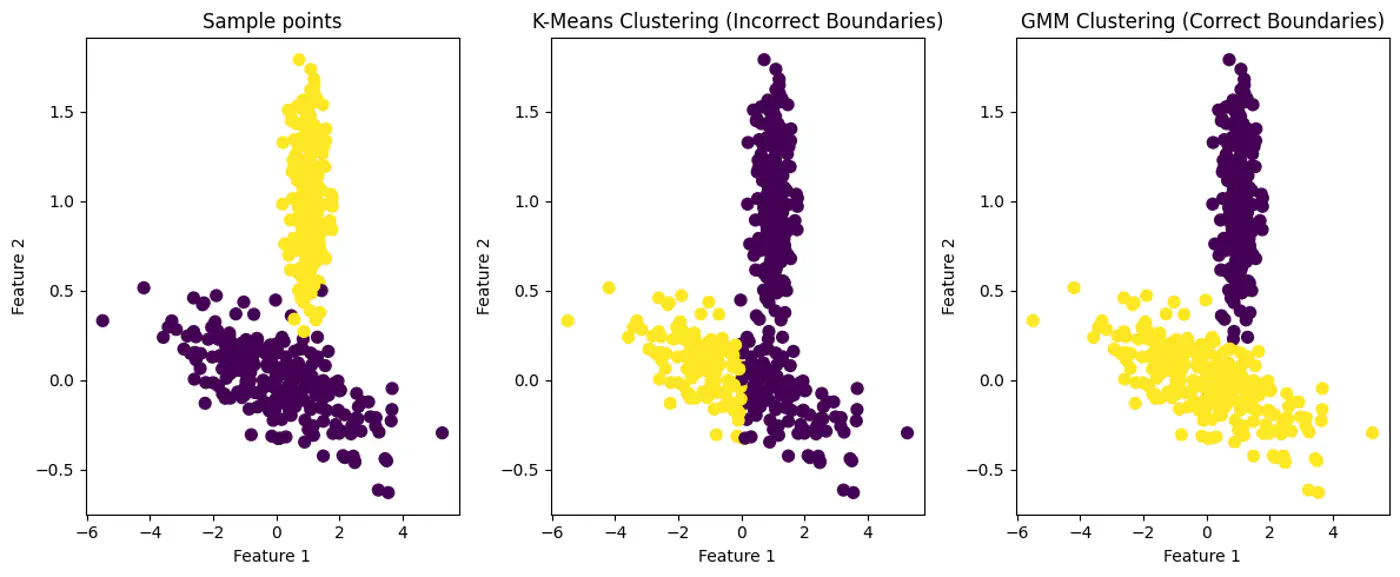
Note: K-Means works best when clusters are roughly spherical, similarly sized, and well-separated.
Combinatorial Explosion 💥
⭐️The problem requires partitioning ’n’ observations into ‘k’ distinct, non-overlapping clusters, which is given by
the Stirling number of the second kind, which grows at a rate roughly equal to \(k^n/k!\).
👉This large number of possible combinations makes the problem NP-Hard.
🦉The k-means optimization problem is NP-hard because it belongs to a class of problems for which no efficient
(polynomial-time ⏰) algorithm is known to exist.
Since, we cannot enumerate all partitions (i.e, partitioning ’n’ observations into ‘k’ distinct, non-overlapping clusters),
Lloyd’s algorithm provides a local search heuristic (approximate algorithm).
Lloyd's Algorithm ⚙️
Iterative method for partitioning ’n’ data points into ‘k’ groups by repeatedly assigning data points to the nearest centroid (mean) and then recalculating centroids until assignments stabilize, aiming to minimize within-cluster variance.
Repeat until convergence, i.e, until cluster assignments and centroids no longer change significantly.
a) Assignment: Assign each data point to the cluster whose centroid is closest (usually using Euclidean distance).
For each point xᵢ: cᵢ = argminⱼ ||xᵢ - μⱼ||²
b) Update: Recalculate the centroid (mean) of each cluster.
For each cluster j: μⱼ = (1/|Cⱼ|) Σₓᵢ∈Cⱼ xᵢ
Issues🚨
Initialization sensitive, different initialization may lead to different clusters.
Tries to make each cluster of same size that may not be the case in real world.
Tries to make each cluster with same density(variance)
Does not work well with non-globular(spherical) data.
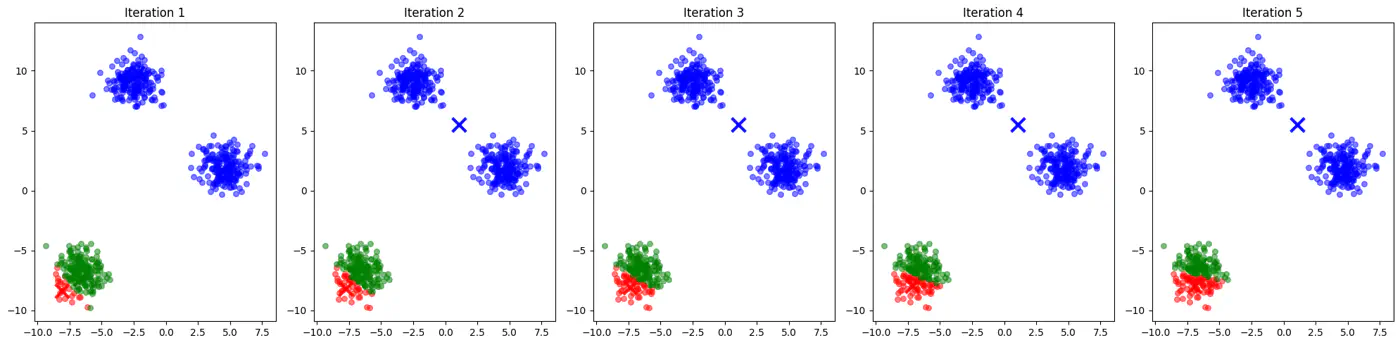
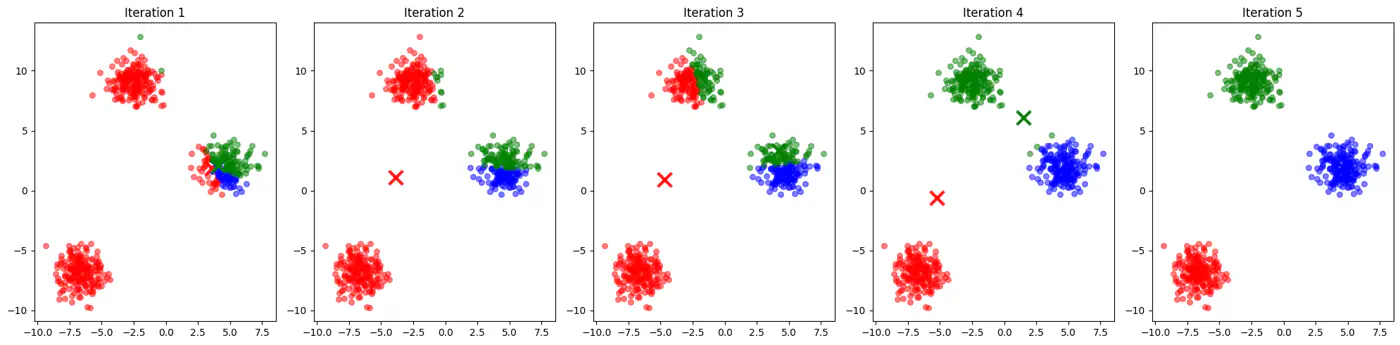
👉See how 2 different runs of K-Means algorithm gives totally different clusters.
👉Also, K-Means does not work well with non-spherical clusters, or clusters with different densities and sizes.
Solutions
✅ Do multiple runs 🏃♂️and choose the clustering with minimum error. ✅ Do not select initial points randomly, but some logic, such as, K-means++ algorithm. ✅ Use hierarchical clustering or density based clustering DBSCAN.
If two initial centroids belong to the same natural cluster, the algorithm will likely split that natural cluster in half and be forced to merge two other distinct clusters elsewhere to compensate.
Inconsistent; different runs may lead to different clusters.
Slow convergence; Centroids may need to travel much farther across the feature space, requiring more iterations.
👉Example for different K-Means algorithm runs give different clusters
K-Means++ Algorithm
💡Addresses the issue due to random initialization by aiming to spread out the initial centroids across the data points.
Steps:
Select the first centroid: Choose one data point randomly from the dataset to be the first centroid.
Calculate distances: For every data point x not yet selected as a centroid, calculate the distance, D(x), between x
and the nearest centroid chosen so far.
Select the next centroid: Choose the next centroid from the remaining data points with a probability
proportional to D(x)^2. This makes it more likely that a point far from existing centroids is selected, ensuring the initial centroids are well-dispersed.
Repeat: Repeat steps 2 and 3 until ‘k’ number of centroids are selected.
Run standard K-means: Once the initial centroids are chosen, the standard k-means algorithm proceeds with assigning
data points to the nearest centroid and iteratively updating the centroids until convergence.
Problem 🚨
🦀 If our data is extremely noisy (outliers), the probabilistic logic (\(\propto D(x)^2\)) might accidentally
pick an outlier as a cluster center.
Solution ✅
Do robust preprocessing to remove outliers or use K-Medoids algorithm.
In K-Means, the centroid is the arithmetic mean of the cluster. The mean is very sensitive to outliers.
Not interpretable; centroid is the mean of cluster data points and may not be an actual data point, hence not representative.
Medoid
⭐️Medoid is a specific data point from a dataset that acts as the ‘center’ or most representative member of its cluster.
👉It is defined as the object within a cluster whose average dissimilarity (distance) to all other members in that
same cluster is the smallest.
K-Medoids (PAM) Algorithm
💡Selects actual data points from the dataset as cluster representatives, called medoids (most centrally located).
👉a.k.a Partitioning Around Medoids(PAM).
Steps:
Initialization: Select ‘k’ data points from the dataset as the initial medoids using K-Means++ algorithm.
Assignment: Calculate the distance (e.g., Euclidean or Manhattan) from each non-medoid point to all medoids and assign each point to the cluster of its nearest medoid.
Update (Swap):
For each cluster, swap current medoid with a non-medoid point from the same cluster.
For each swap, calculate the total cost 💰(sum of distances from medoid).
Pick the medoid with minimum cost 💰.
Repeat🔁: Repeat the assignment and update steps until (convergence), i.e, medoids no longer change or
a maximum number of iterations is reached.
Note: Kind of brute-force algorithm, computationally expensive for large dataset.
Advantages
✅ Robust to Outliers: Since medoids are actual data points rather than averages, extreme values (outliers)
do not skew the center of the cluster as they do in K-Means. ✅ Flexible Distance Metrics: It can work with any dissimilarity measure (Manhattan, Cosine similarity), making it ideal
for categorical or non-Euclidean data. ✅ Interpretable Results: Cluster centers are real observations (e.g., a ‘typical’ customer profile), which makes
the output easier to explain to stakeholders.
👉 Elbow Method: Quickest to compute; good for initial EDA (Exploratory Data Analysis).
👉 Dunn Index: Focuses on the ‘gap’ between the closest clusters.
👉 Silhouette Score: Balances compactness and separation.
👉 Domain specific knowledge and system constraints.
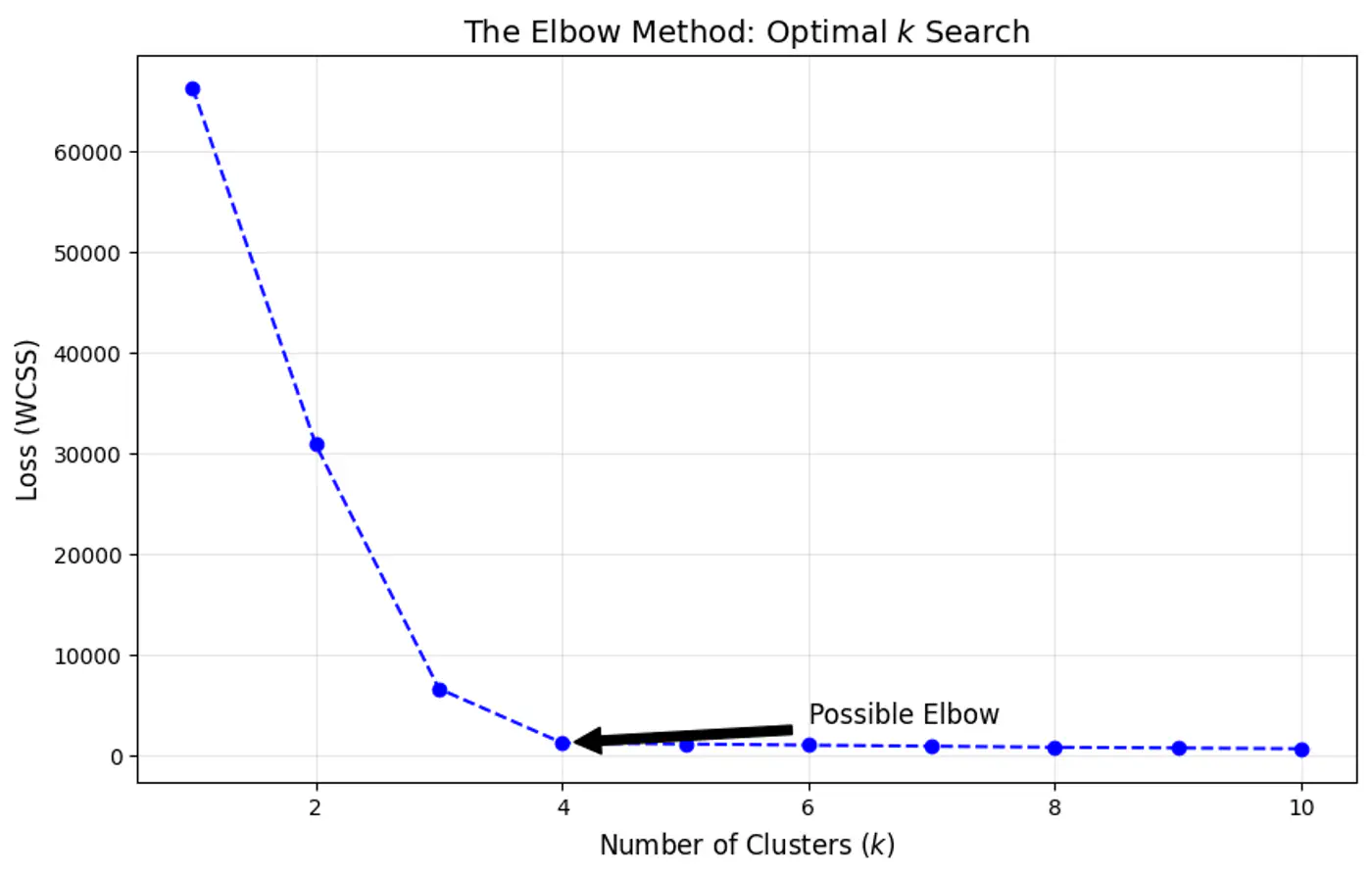
Elbow Method
⭐️Heuristic used to determine the optimal number of clusters (k) for clustering by visualizing how the
quality of clustering improves as ‘k’ increases.
🎯The goal is to find a value of ‘k’ where adding more clusters provides a diminishing return in terms of variance reduction.
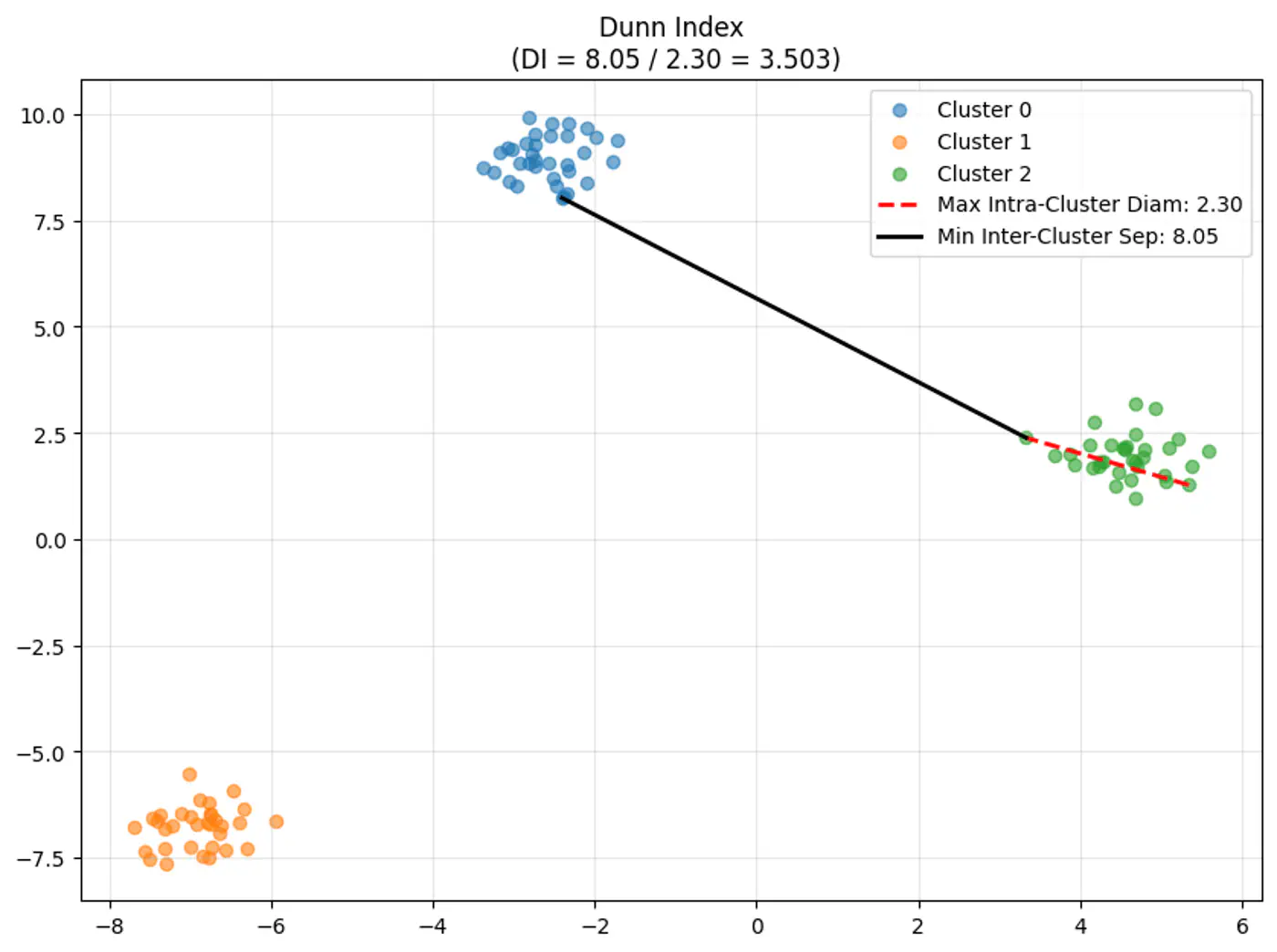
Dunn Index [0, \(\infty\))
⭐️Clustering quality evaluation metric that measures: separation (between clusters) and compactness (within clusters)
Note: A higher Dunn Index value indicates better clustering, meaning clusters are well-separated from each other and compact.
👉Dunn Index Formula:
\[DI = \frac{\text{Minimum Inter-Cluster Distance(between different clusters)}}{\text{Maximum Intra-Cluster Distance(within a cluster)}}\]\[DI = \frac{\min_{1 \le i < j \le k} \delta(C_i, C_j)}{\max_{1 \le l \le k} \Delta(C_l)}\]
👉Let’s understand the terms in the above formula:
\(\delta(C_i, C_j)\) (Inter-Cluster Distance):
Measures how ‘far apart’ the clusters are.
Distance between the two closest points of different clusters (Single-Linkage distance).
\[\delta(C_i, C_j) = \min_{x \in C_i, y \in C_j} d(x, y)\]
\(\Delta(C_l)\) (Intra-Cluster Diameter):
Measures how ‘spread out’ a cluster is.
Distance between the two furthest points within the same cluster (Complete-Linkage distance).
\[\Delta(C_l) = \max_{x, y \in C_l} d(x, y)\]
Measure of Closeness
Single Linkage (MIN): Uses the minimum distance between any two points in different clusters.
Complete Linkage (MAX): Uses the maximum distance between any two points in same cluster.
✅ Elbow Method: Quickest to compute; good for initial EDA.
✅ Dunn Index: Focuses on the ‘gap’ between the closest clusters. ——- We have seen the above 2 methods in the previous section ———-
👉 Silhouette Score: Balances compactness and separation.
👉 Domain specific knowledge and system constraints.
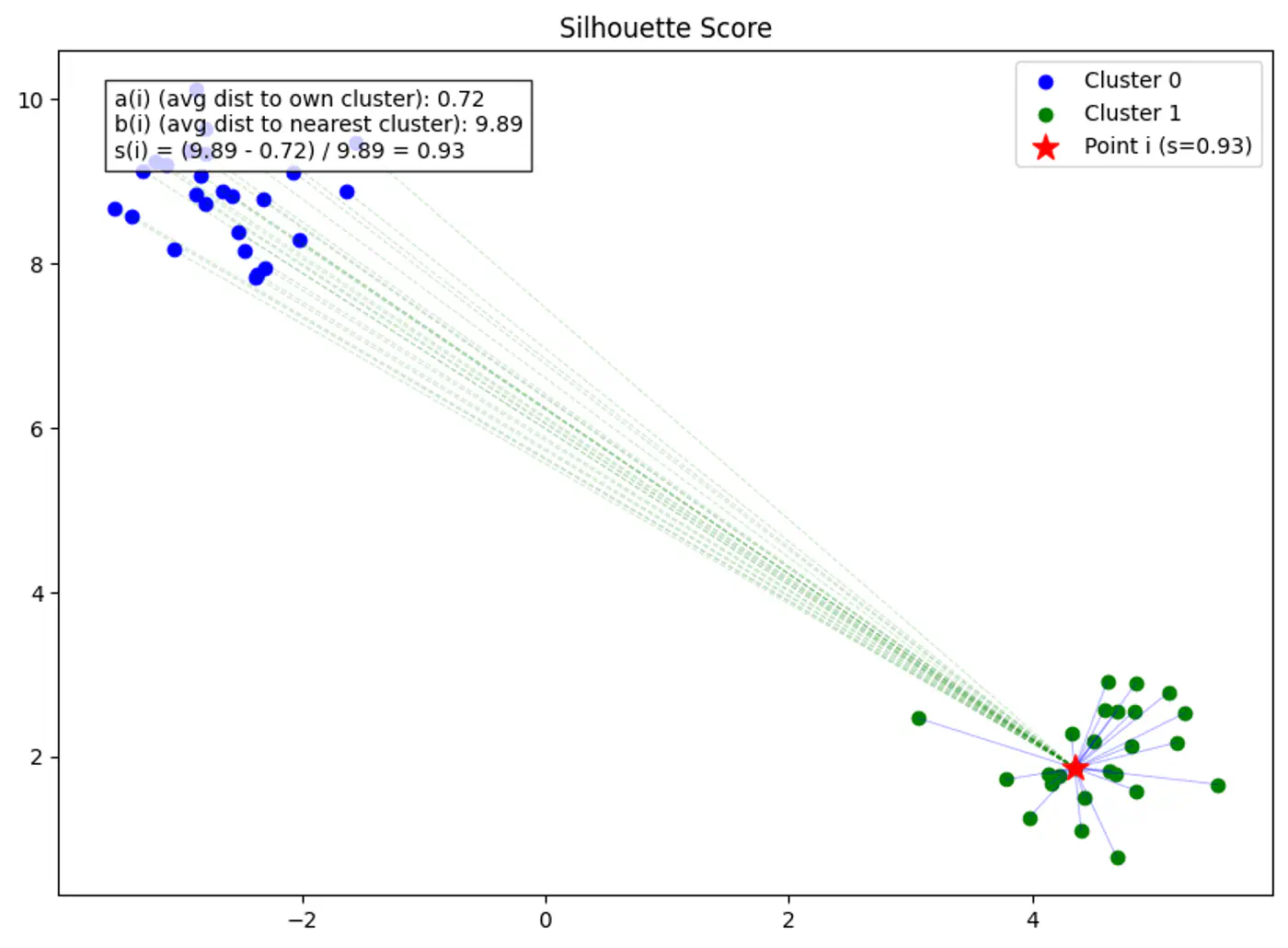
Silhouette Score [-1, 1]
⭐️Clustering quality evaluation metric that measures how similar a data point is to its own cluster (cohesion)
compared to other clusters (separation).
Note: Higher scores (closer to 1) indicate better-defined, distinct clusters, while scores near 0 suggest overlapping clusters, and negative scores mean points might be in the wrong cluster.
Silhouette Score Formula
Silhouette score for point ‘i’ is the difference between separation b(i) and cohesion a(i), normalized by the larger of the two.
\[ s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))} \]
Note: The Global Silhouette Score is simply the mean of s(i) for all points in the dataset.
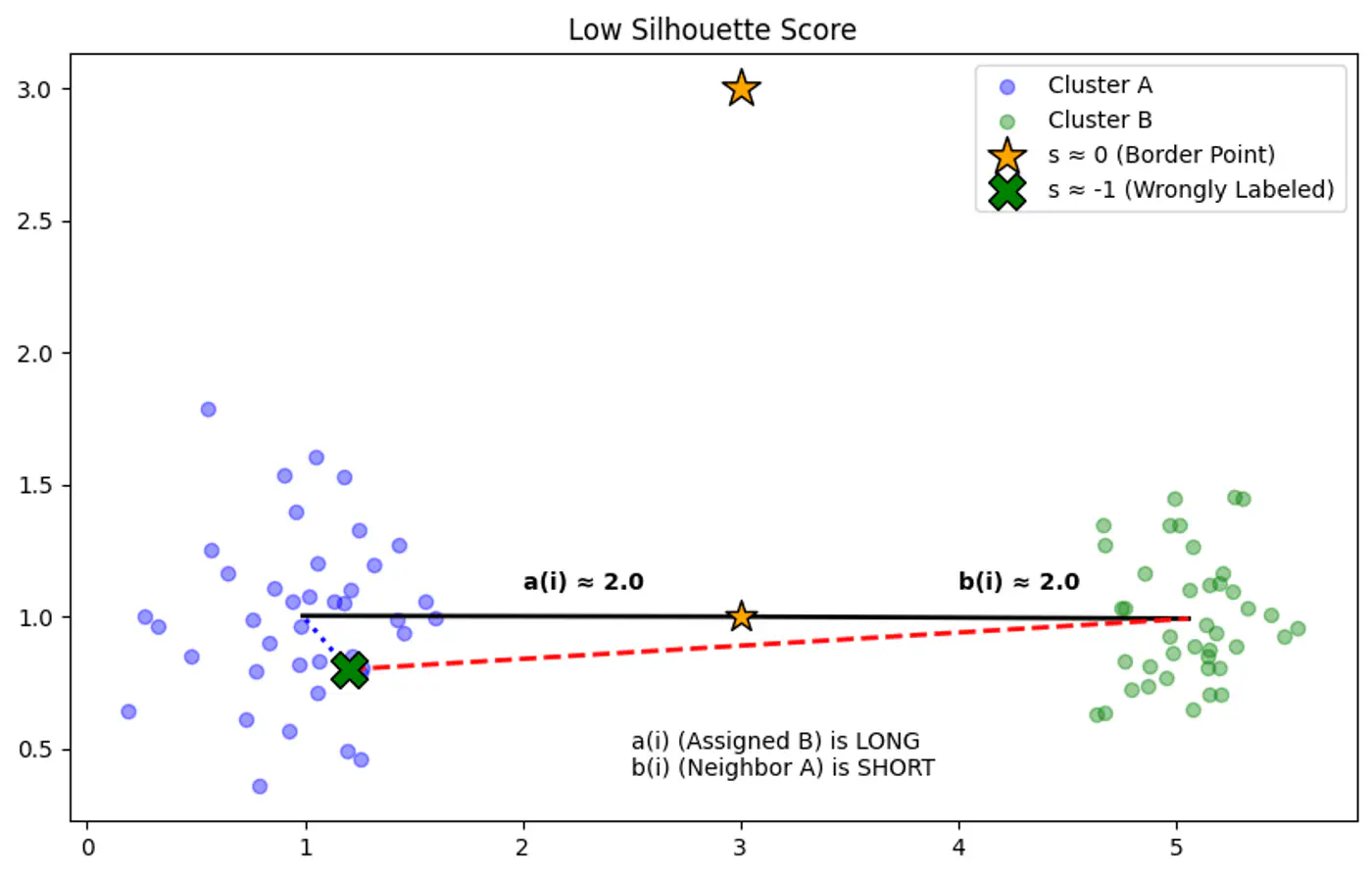
👉Example for Silhouette Score:
👉Example for Silhouette Score of 0(Border Point) and negative(Wrong Cluster).
🦉Now let’s understand the terms in Silhouette Score in detail.
Cohesion a(i)
Average distance between point ‘i’ and all other points in the same cluster.
Note: Higher b(i) means the point is very far from the next closest cluster.
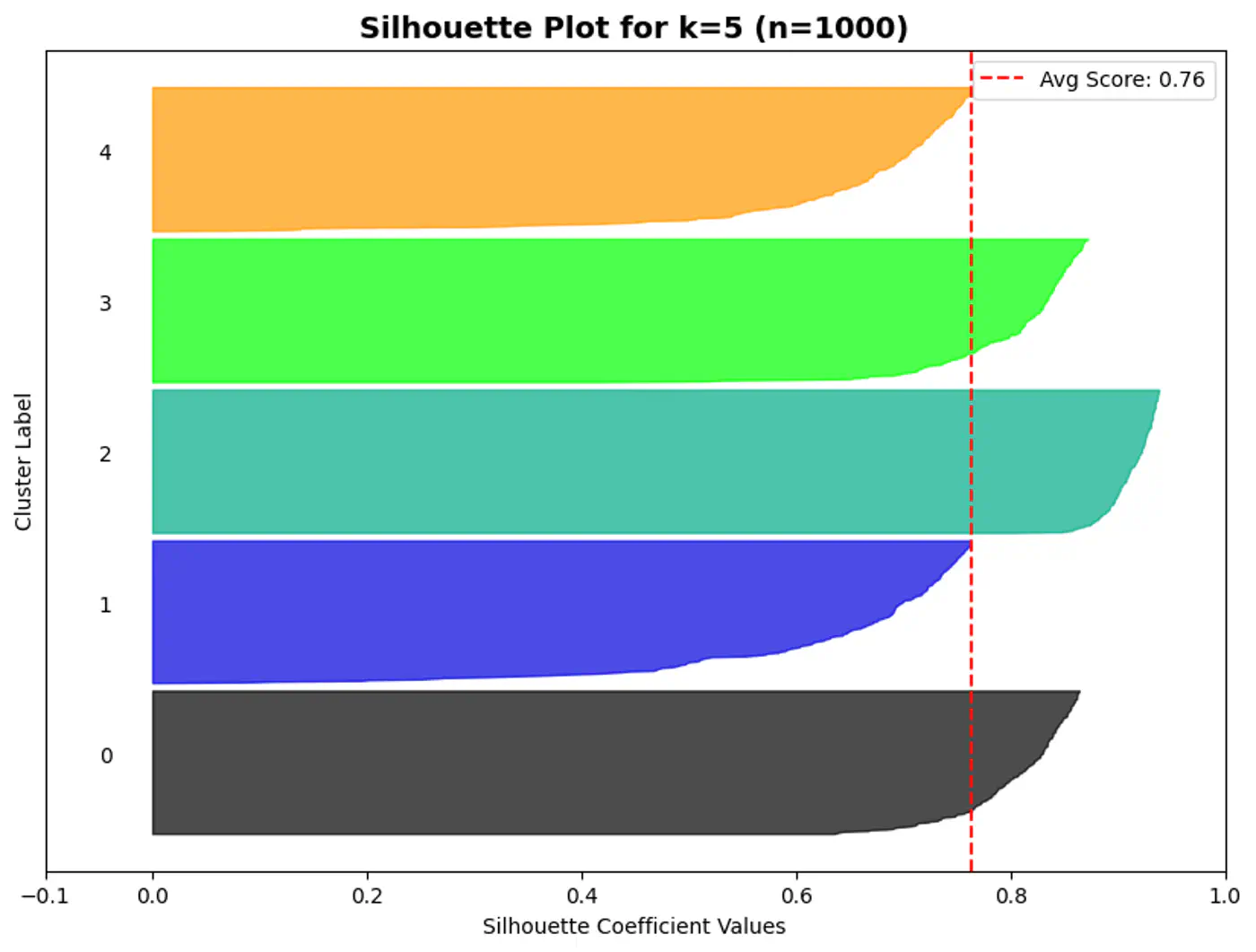
Silhouette Plot
⭐️A silhouette plot is a graphical tool used to evaluate the quality of clustering algorithms (like K-Means),
showing how well each data point fits within its cluster.
👉Each bar gives the average silhouette score of the points assigned to that cluster.
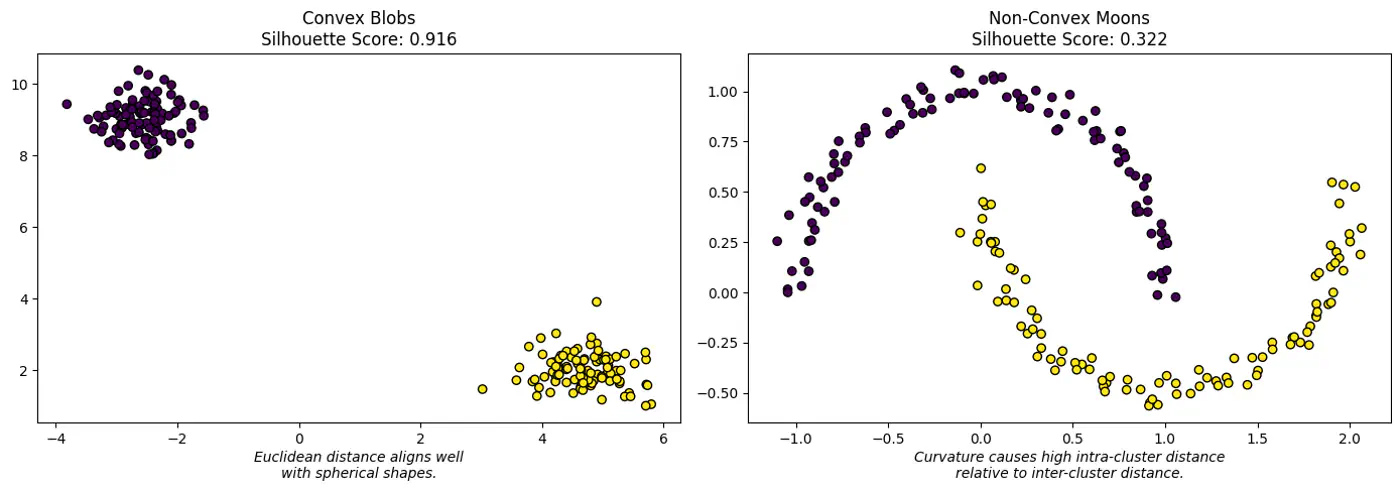
Geometric Interpretation
⛳️ Like K-Means, the Silhouette Score (when using Euclidean distance) assumes convex clusters.
🌘 If we use it on ‘Moon’ shaped clusters, it will give a low score even if the clusters are perfectly separated,
because the ‘average distance’ to a neighbor might be small due to the curvature of the manifold.
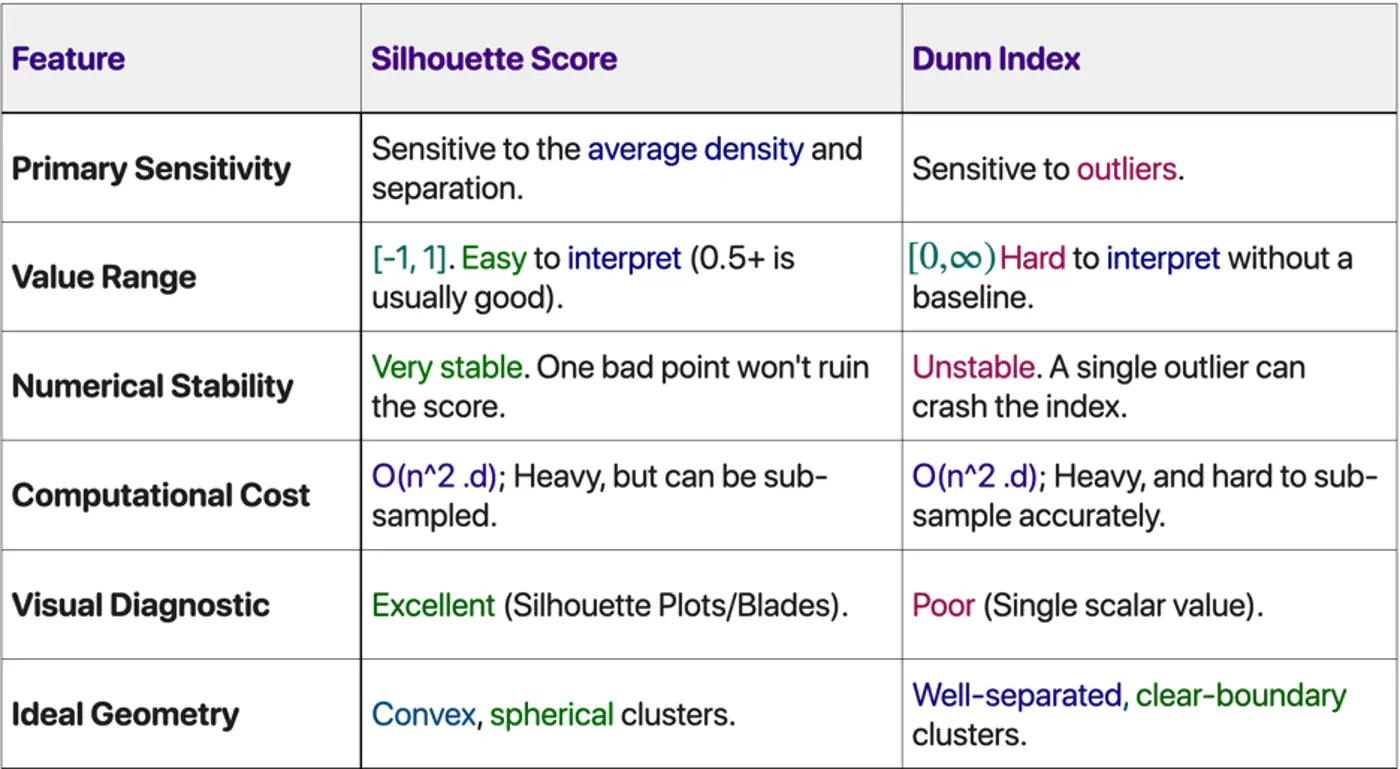
Silhouette Score Vs Dunn Index
Choose Silhouette Score if: ✅ Need a human-interpretable metric to present to stakeholders. ✅ Dealing with real-world noise and overlapping ‘fuzzy’ boundaries. ✅ Want to see which specific clusters are weak (using the plot).
Choose Dunn Index if: ✅ Performing ‘Hard Clustering’ where separation is a safety or business requirement. ✅ Data is pre-cleaned of outliers (e.g., in a curated embedding space). ✅ Need to compare different clustering algorithms (e.g., K-Means vs. DBSCAN) on a high-integrity task.
🤷 We might not know in advance the number of distinct clusters ‘k’ in the dataset.
🕸️ Also, sometimes the dataset may contain a nested structure or some inherent hierarchy, such as, file system,
organizational chart, biological lineages, etc.
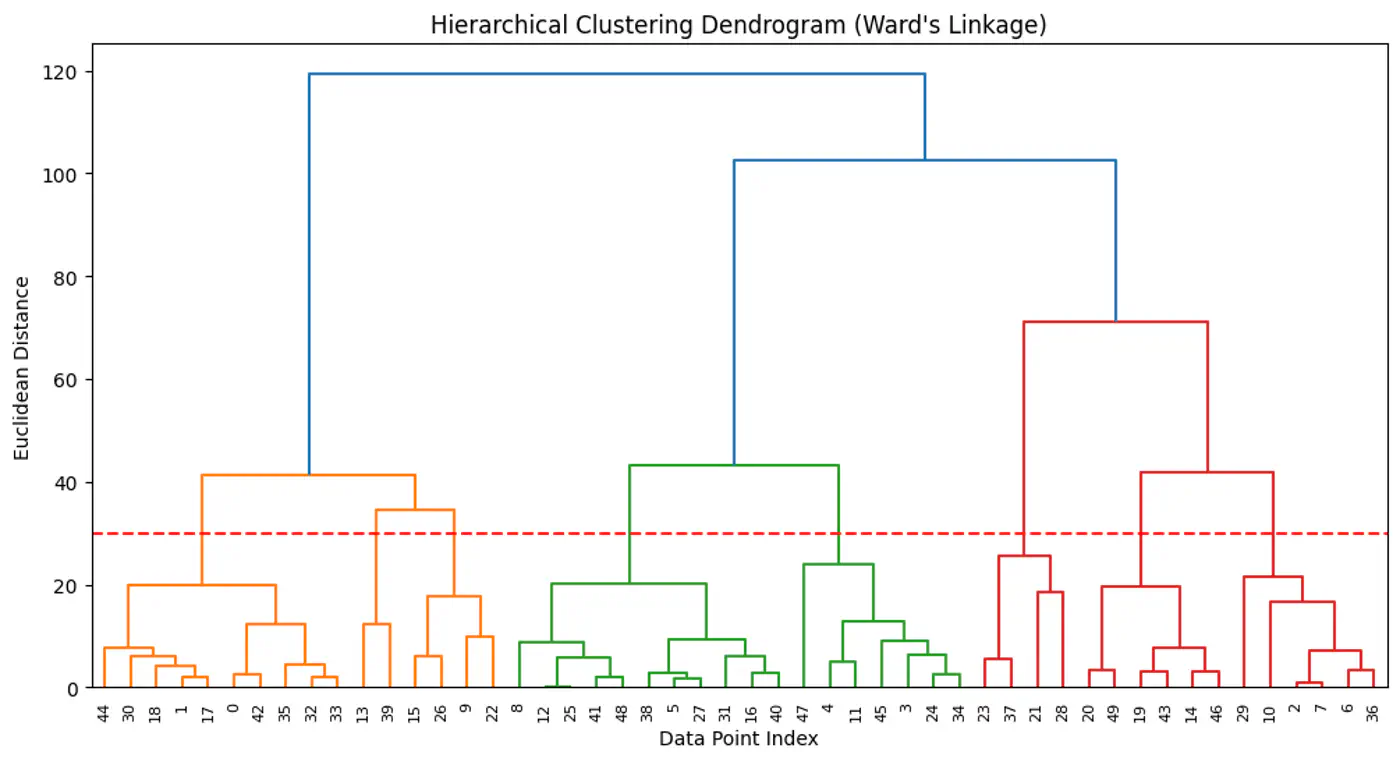
Hierarchical Clustering
⭐️ Method of cluster analysis that seeks to build a hierarchy of clusters, resulting in a tree like structure called dendrogram.
👉Hierarchical clustering allows us to explore different possibilities (of ‘k’) by cutting the dendrogram at various levels.
2 Philosophies
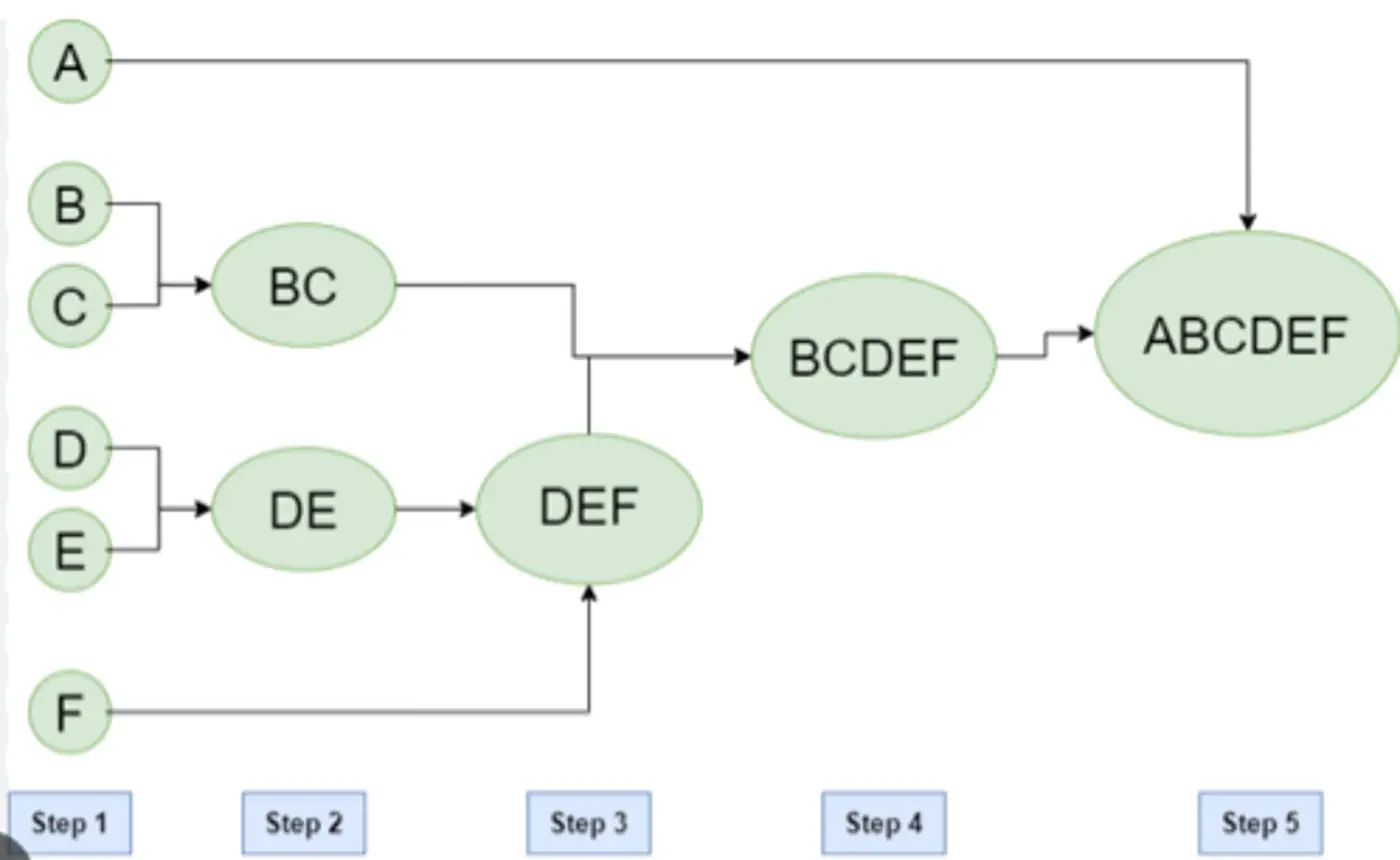
Agglomerative (Bottom-Up): Most common, also known as Agglomerative Nesting (AgNes).
Every data point starts as its own cluster.
In each step, merge the two ‘closest’ clusters.
Repeat step 2, until all points are merged in a single cluster.
Divisive (Top-Down):
All data points start in one large cluster.
In each step, divide the cluster into two halves.
Repeat step 2, until every point is its own cluster.
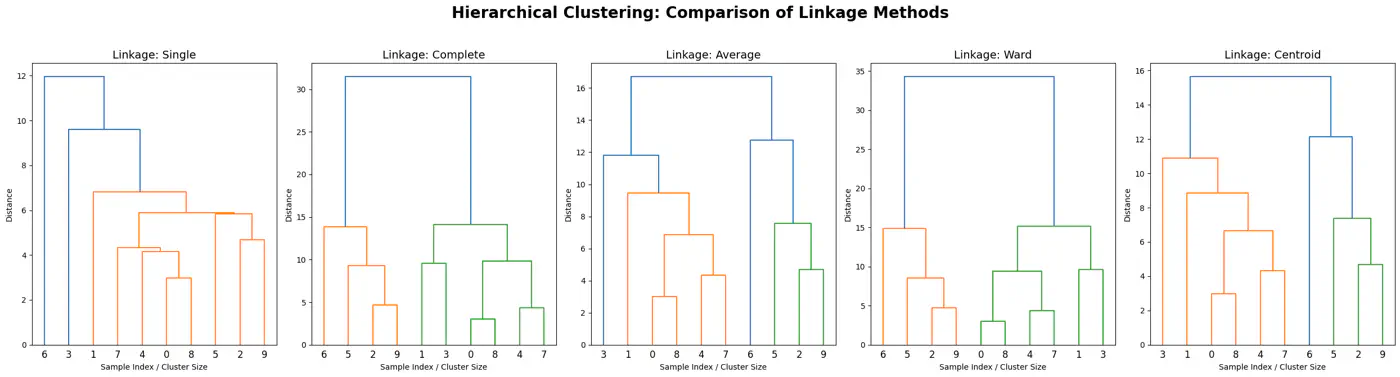
Agglomerative Clustering Example:
Closeness of Clusters
Ward’s Method:
Merges clusters to minimize the increase in the total within-cluster variance (sum of squared errors), resulting in compact, equally sized clusters.
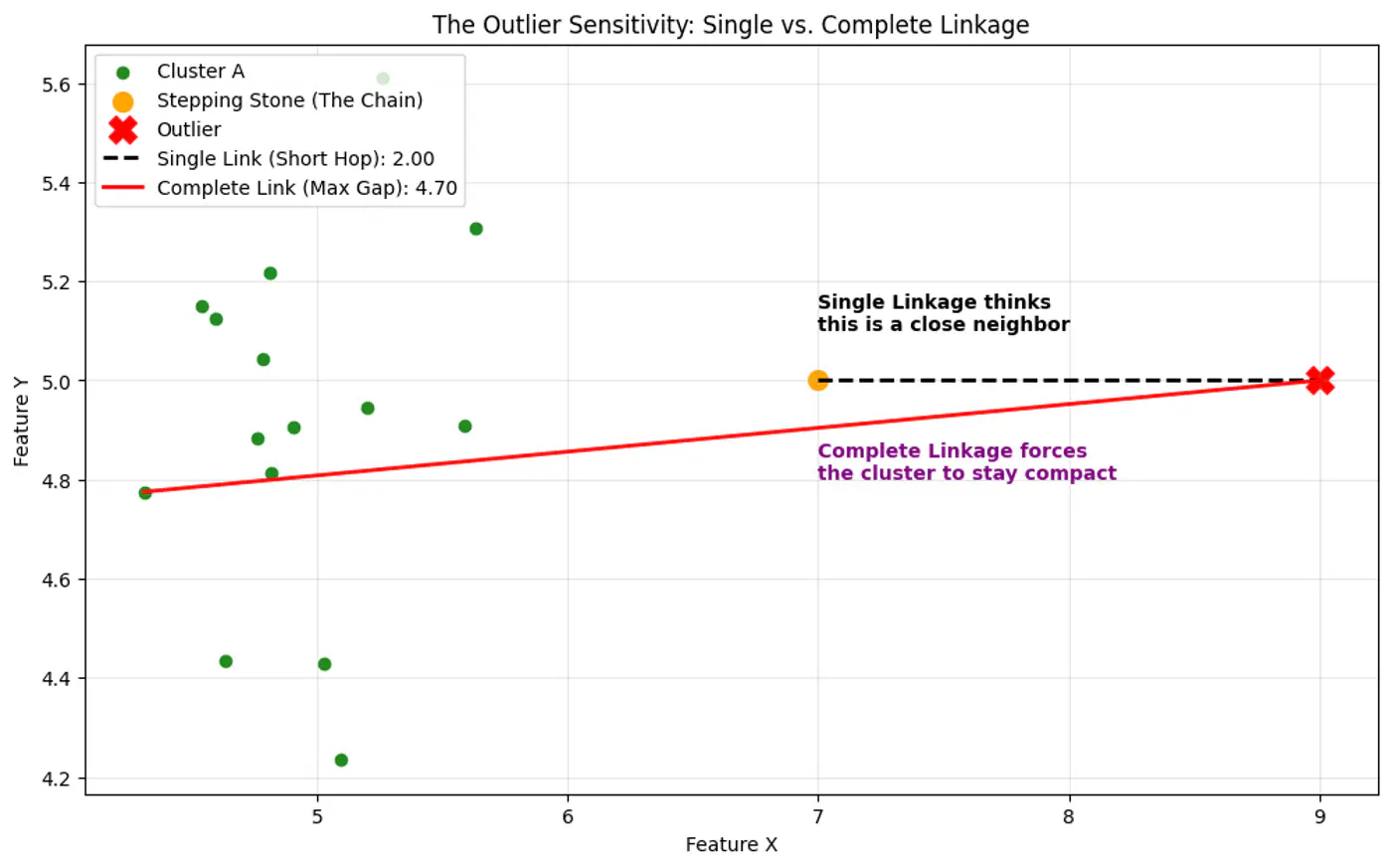
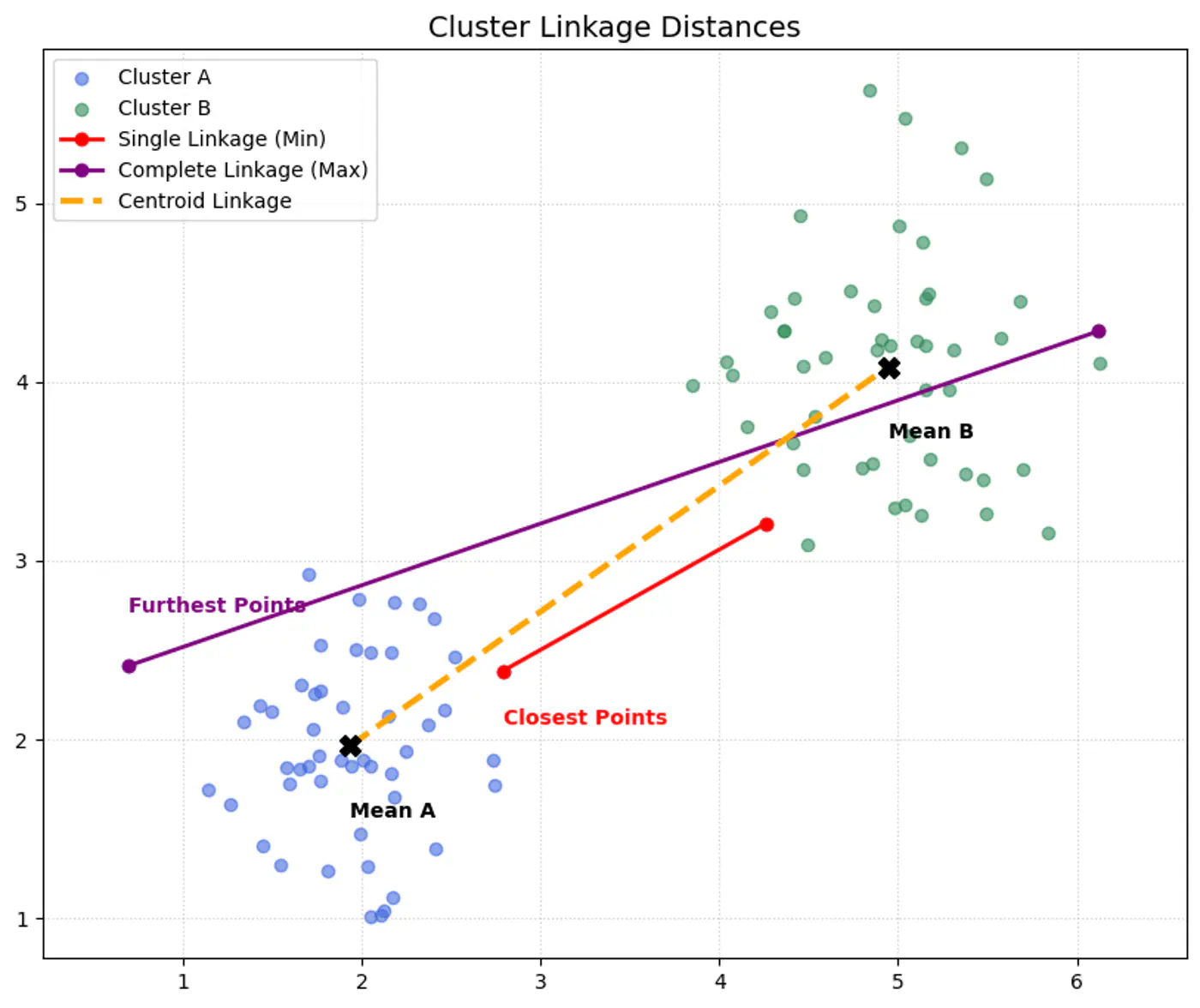
Single Linkage (MIN):
Uses the minimum distance between any two points in different clusters.
Prone to creating long, ‘chain-like’ 🔗 clusters, sensitive to outliers.
Complete Linkage (MAX):
Uses the maximum distance between any two points in different clusters.
Forms tighter, more spherical clusters, less sensitive to outliers than single linkage.
Average Linkage:
Combines clusters by the average distance between all points in two clusters, offering a compromise between single and complete linkage.
A good middle ground, often overcoming limitations of single and complete linkage.
Centroid Method:
Merges clusters based on the distance between their centroids (mean points).
👉Single Linkage is moresensitive to outlier than Complete Linkage, as Single Linkage can keep linking to the closest point
forming a bridge to outlier.
👉All cluster linkage distances.
👉We get different clustering using different linkages.
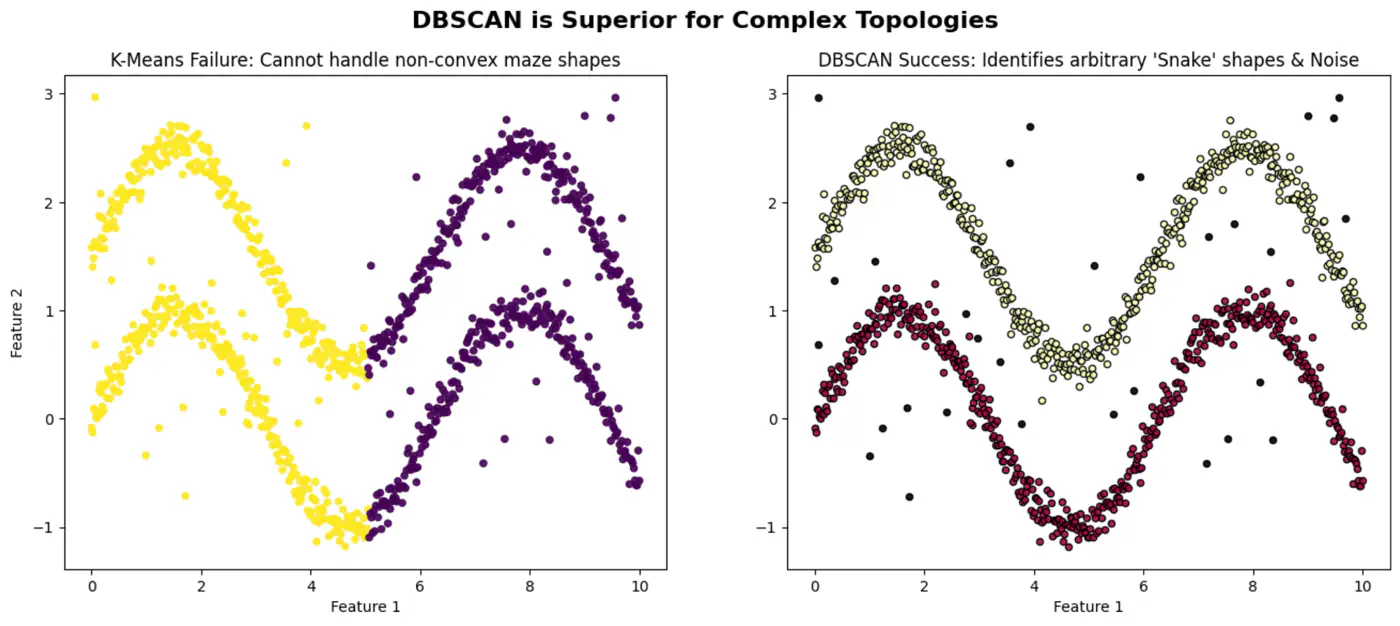
Density Based Spatial Clustering of Application with Noise
Issues with K-Means
Non-Convex Shapes: K-Means can not find ‘crescent’ or ‘ring’ shape clusters.
Noise: K-Means forces every point into a cluster, even outliers.
Main Question for Clustering ?
👉K-Means asks:
“Which center is closest to this point?”
👉DBSCAN asks:
“Is this point part of a dense neighborhood?”
Intuition 💡
Cluster is a contiguous region of high density in the data space, separated from other clusters by areas of low density.
DBSCAN
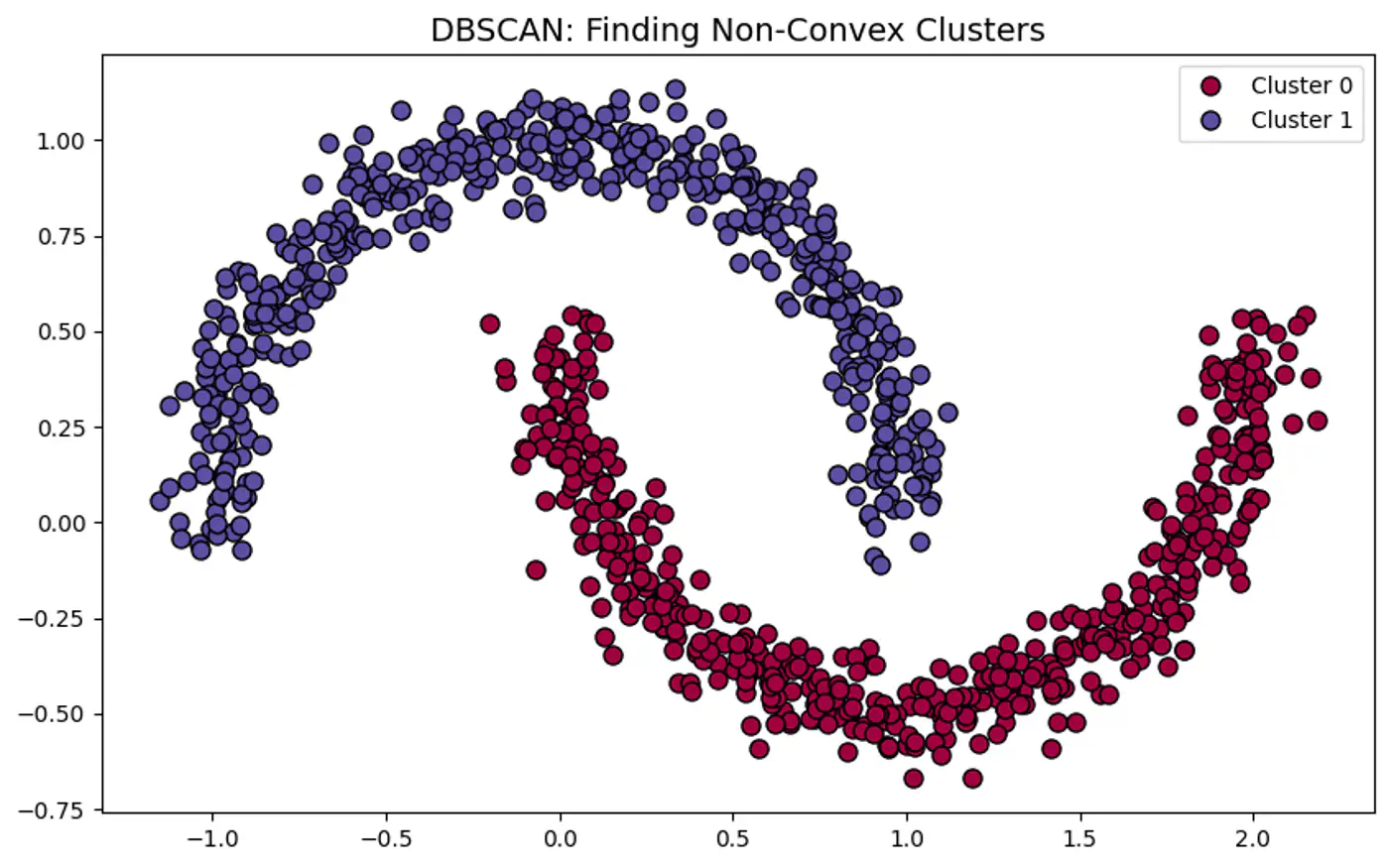
⭐️Groups closely packed data points into clusters based on their density, and marks points that lie alone in low-density regions as outliers or noise.
Note: Unlike K-means, DBSCAN can find arbitrarily shaped clusters and does not require the number of clusters to be specified beforehand.
Hyper-Parameters 🎛️
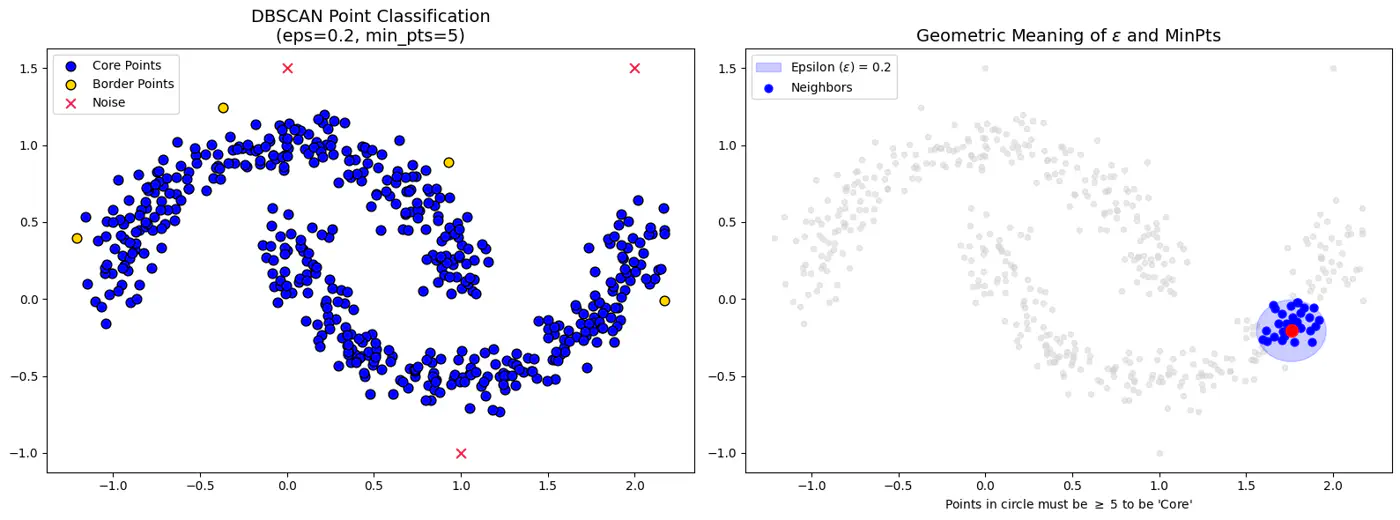
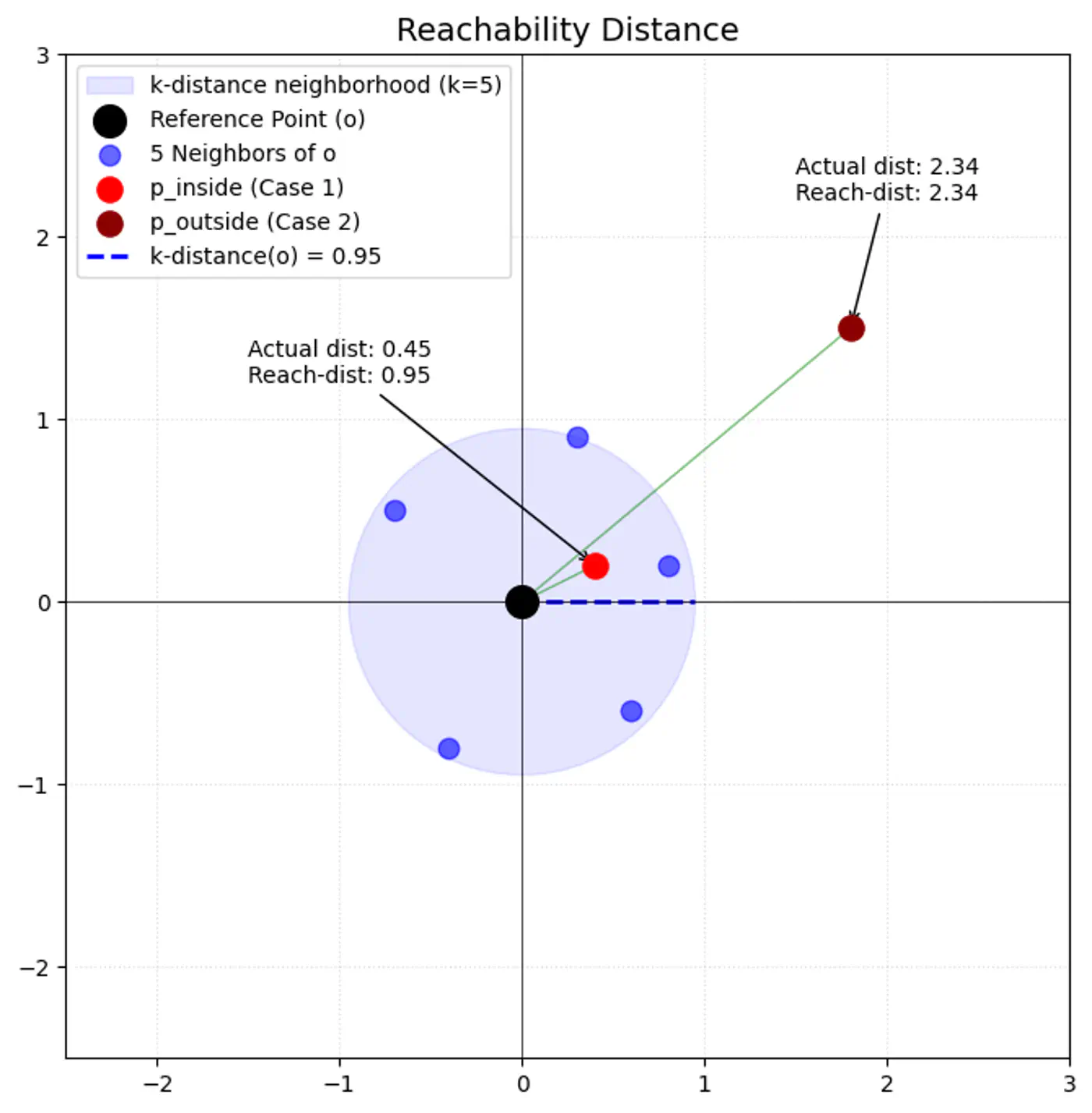
Epsilon (eps or \(\epsilon\)):
Radius that defines the neighborhood around a data point.
If it’s too small, many points will be noise, and if too large, distinct clusters may merge.
Minimum Points(minPts or min_samples):
Minimum number of data points required within a point’s -neighborhood for that point to be considered a dense region (a core point).
Defines threshold for ‘density’.
Rule of thumb: minPts dimensions + 1; use larger value for noisy data (minPts 2*dimensions).
Types of Points
Core Point:
If it has at least minPts (including itself) within its -neighborhood.
Forms the dense backbone of the clusters and can expand them.
Border Point:
If it has at fewer than minPts within its -neighborhood but falls within the -neighborhood of a core point.
Border points belong to a cluster but cannot expand it further.
Noise Point (Outlier):
If it is neither a core point nor a border point, i.e., it is not density-reachable from any core point.
Not assigned to any cluster.
DBSCAN Algorithm ⚙️
Random Start:
Mark all points as unvisited; pick an arbitrary unvisited point ‘P’ from the dataset.
Density Check:
Check the point P’s ϵ-neighborhood.
If ‘P’ has at least minPts, it is identified as a core point, and a new cluster is started.
If it has fewer than minPts, the point is temporarily labeled as noise (it might become a border point later).
Cluster Expansion:
Recursively visit all points in P’s ϵ-neighborhood.
If they are also core points, their neighbors are added to the cluster.
Iteration 🔁:
This ‘density-reachable’ logic continues until the cluster is fully expanded.
The algorithm then picks another unvisited point and repeats the process, discovering new clusters or marking more points as noise until all points are processed.
👉DBSCAN can correctly detect non-spherical clusters.
👉DBSCAN Points and Epsilon-Neighborhood.
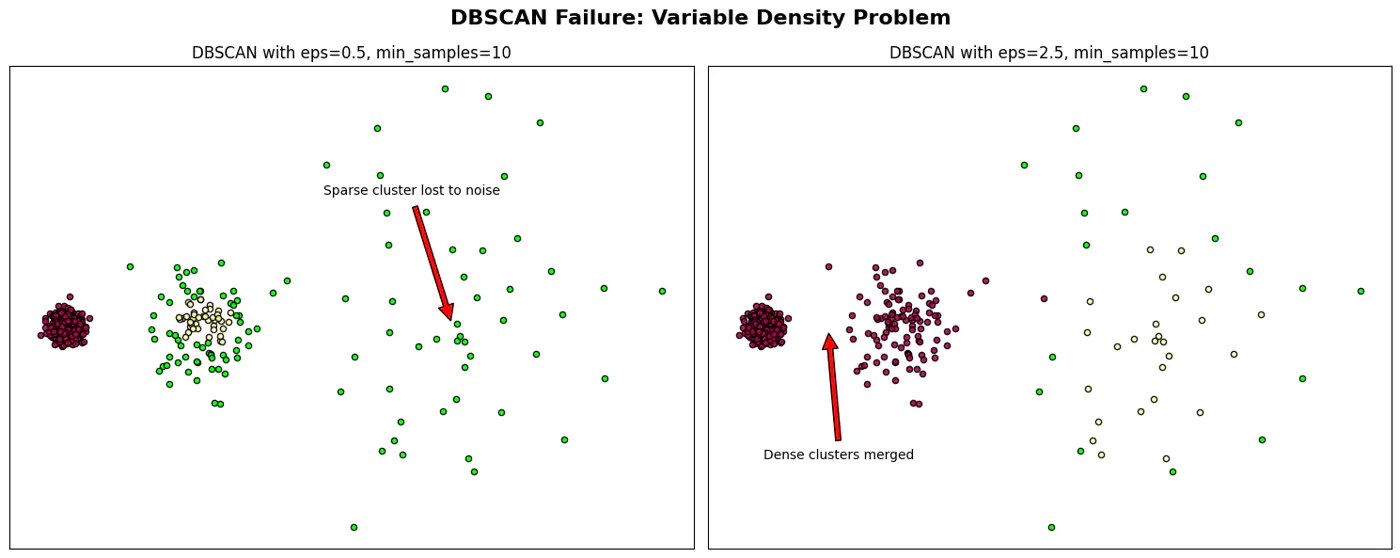
When DBSCAN Fails ?
Varying Density Clusters:
Say A cluster is very dense and B is sparse, a single cannot satisfy both clusters.
High Dimensional Data:
‘Curse of Dimensionality’ - In high-dimensional space, the distance between any two points converge.
Note: Sensitive to parameter eps and minPts; tricky to get it work.
👉DBSCAN Failure and Epsilon ((\epsilon)
When to use DBSCAN ?
Arbitrary Cluster Shapes:
When clusters are intertwined, nested, or ‘moon-shaped’; where K-Means would fail by splitting them.
Presence of Noise and Outliers:
Robust to noise and outliers because it explicitly identifies low-density points as noise (labeled as -1) rather than forcing them into a cluster.
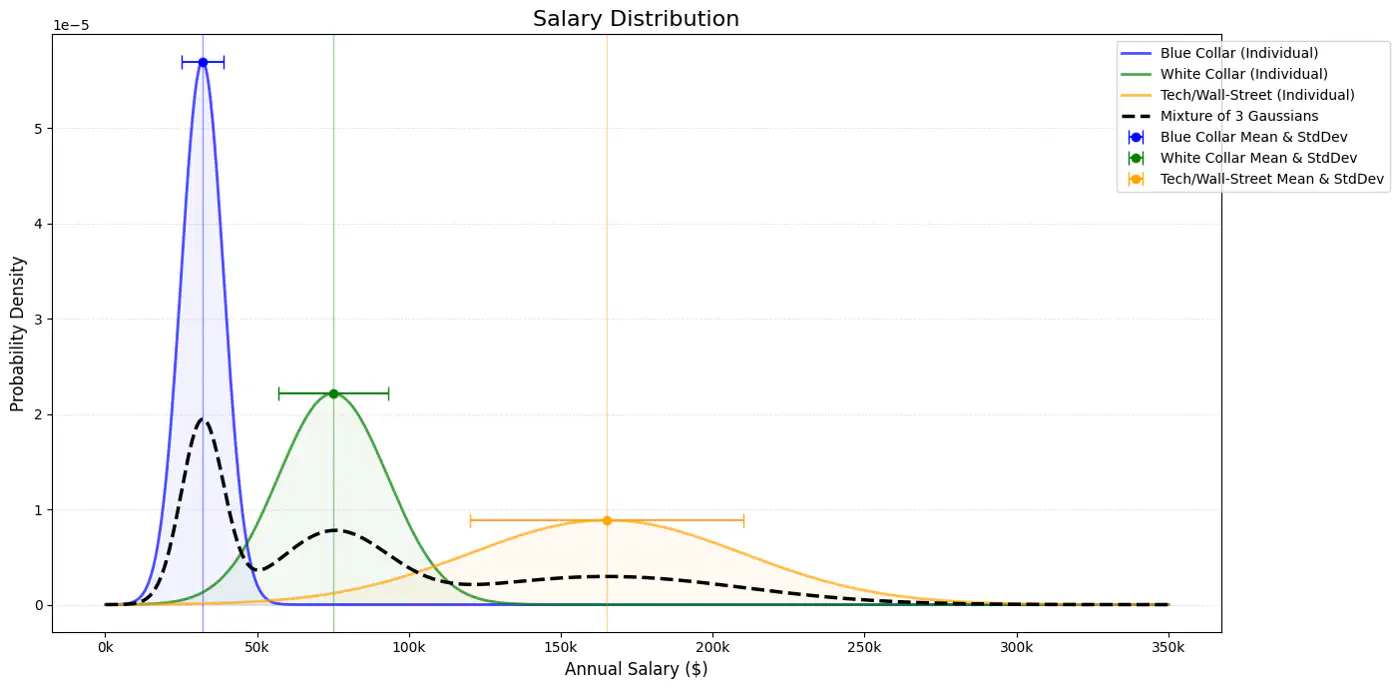
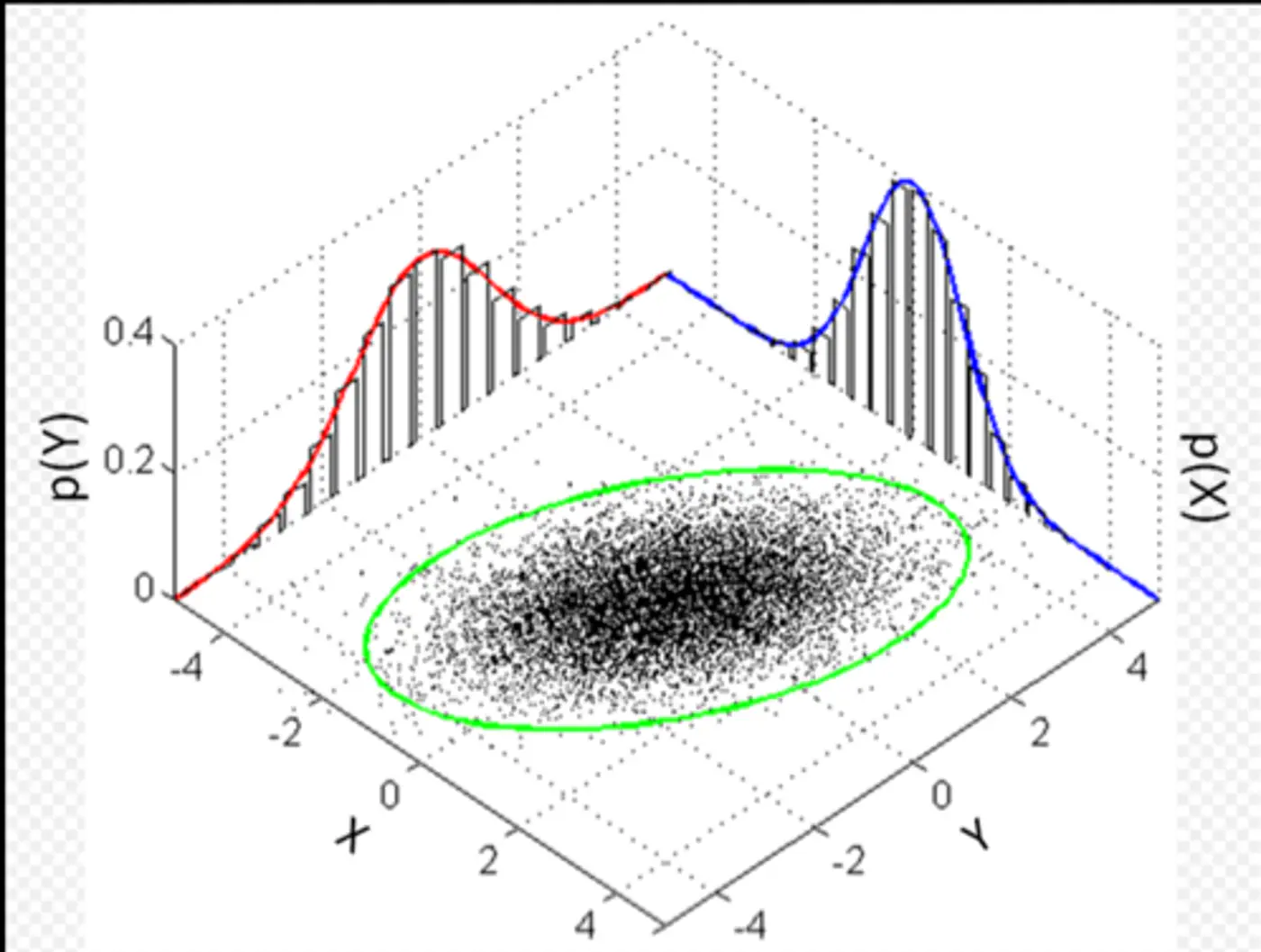
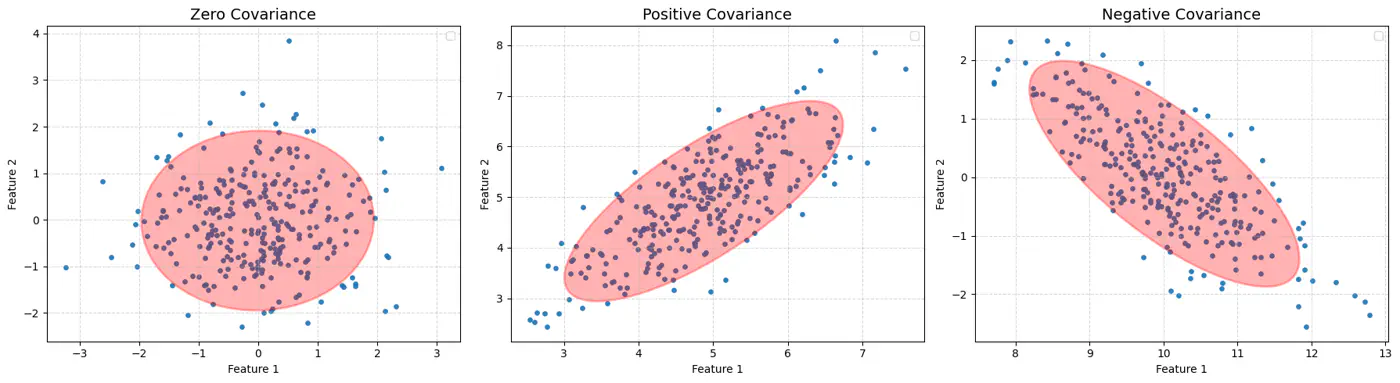
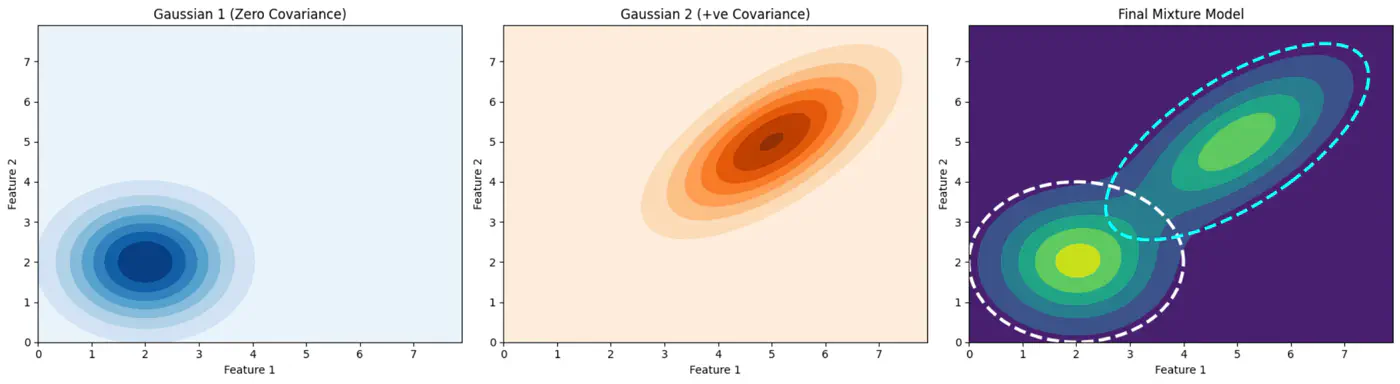
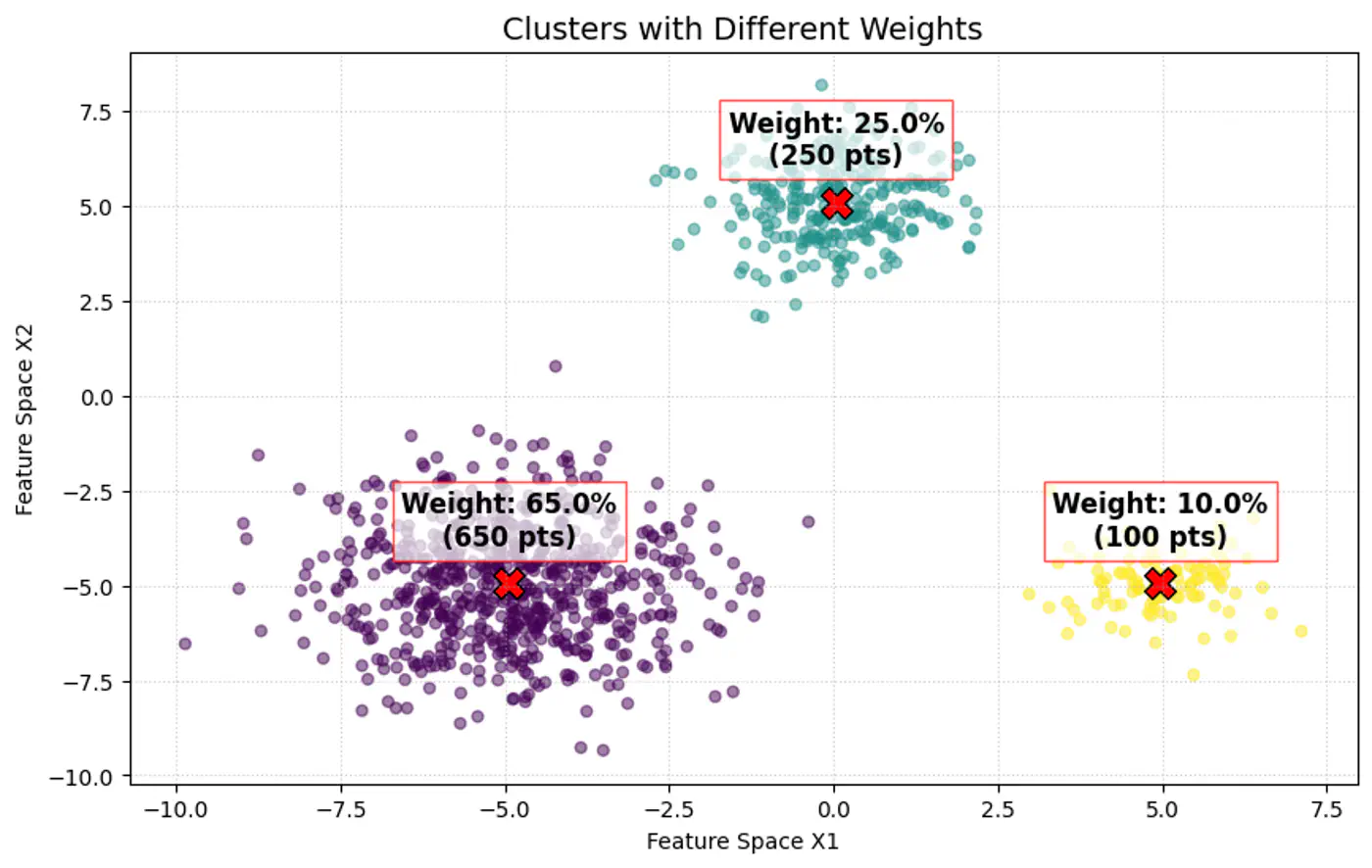
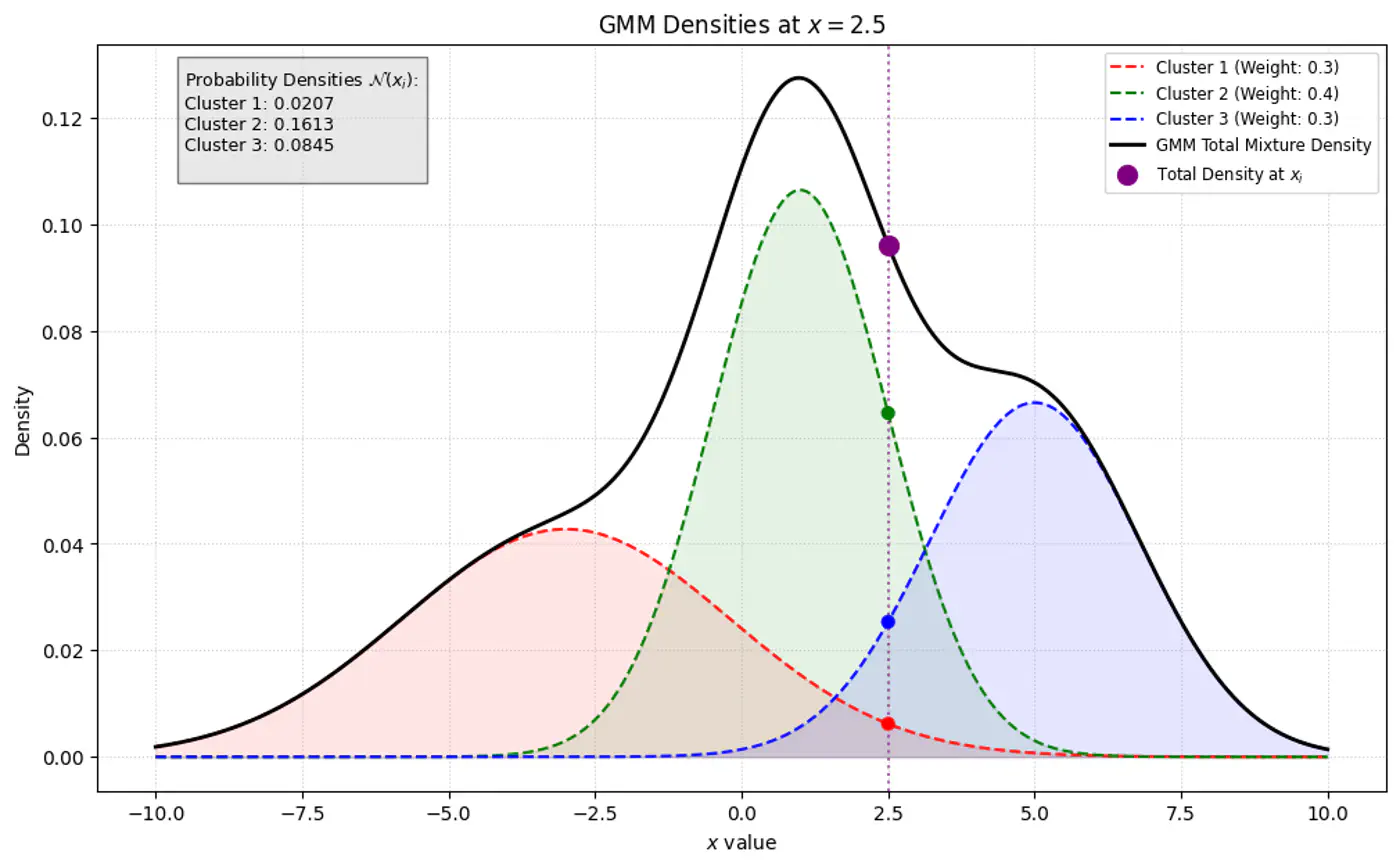
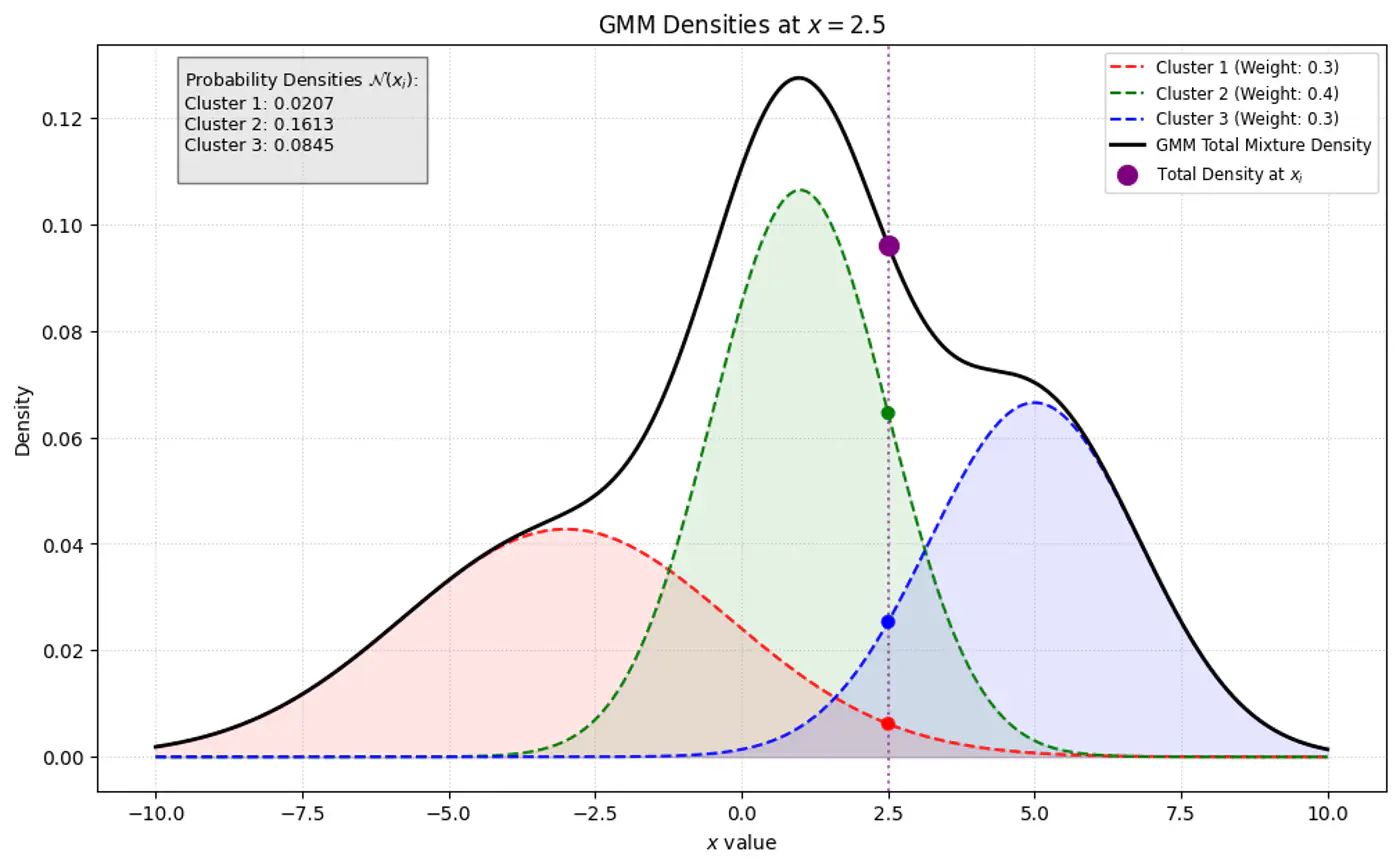
\(\pi_k\): mixing coefficient (weight) of the k-th component, such that, \(\pi_k \ge 0\) and \(\sum _{k=1}^{K}\pi _{k}=1\).
\(\mathcal{N}(x_i|\mathbf{\mu }_{k},\mathbf{\Sigma }_{k})\): probability density function of the k-th Gaussian component
with mean \(\mu_k\) and covariance matrix \(\Sigma_k\).
\(\mathbf{\theta }=\{(\pi _{k},\mathbf{\mu }_{k},\mathbf{\Sigma }_{k})\}_{k=1}^{K}\): complete set of parameters to be estimated.
👉 Weight of the cluster is proportional to the number of points in the cluster.
👉Below image shows the weighted Gaussian PDF, given the weights of clusters.
GMM Optimization (Why MLE Fails?)
🎯 Goal of a GMM optimization is to find the set of parameters \(\Theta =\{(\pi _{k},\mu _{k},\Sigma _{k})\mid k=1,\dots ,K\}\) that maximize the likelihood of observing the given data.
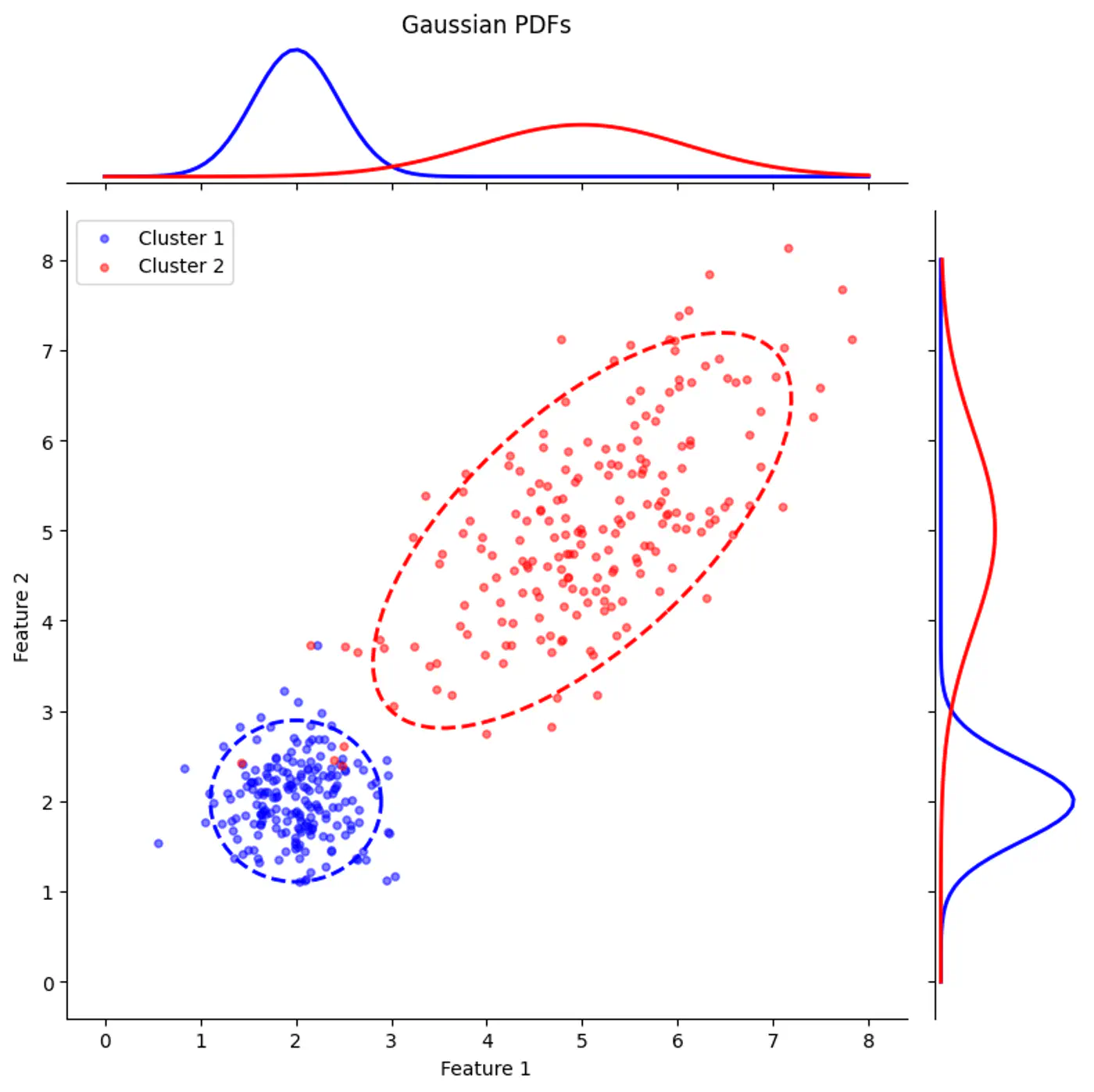
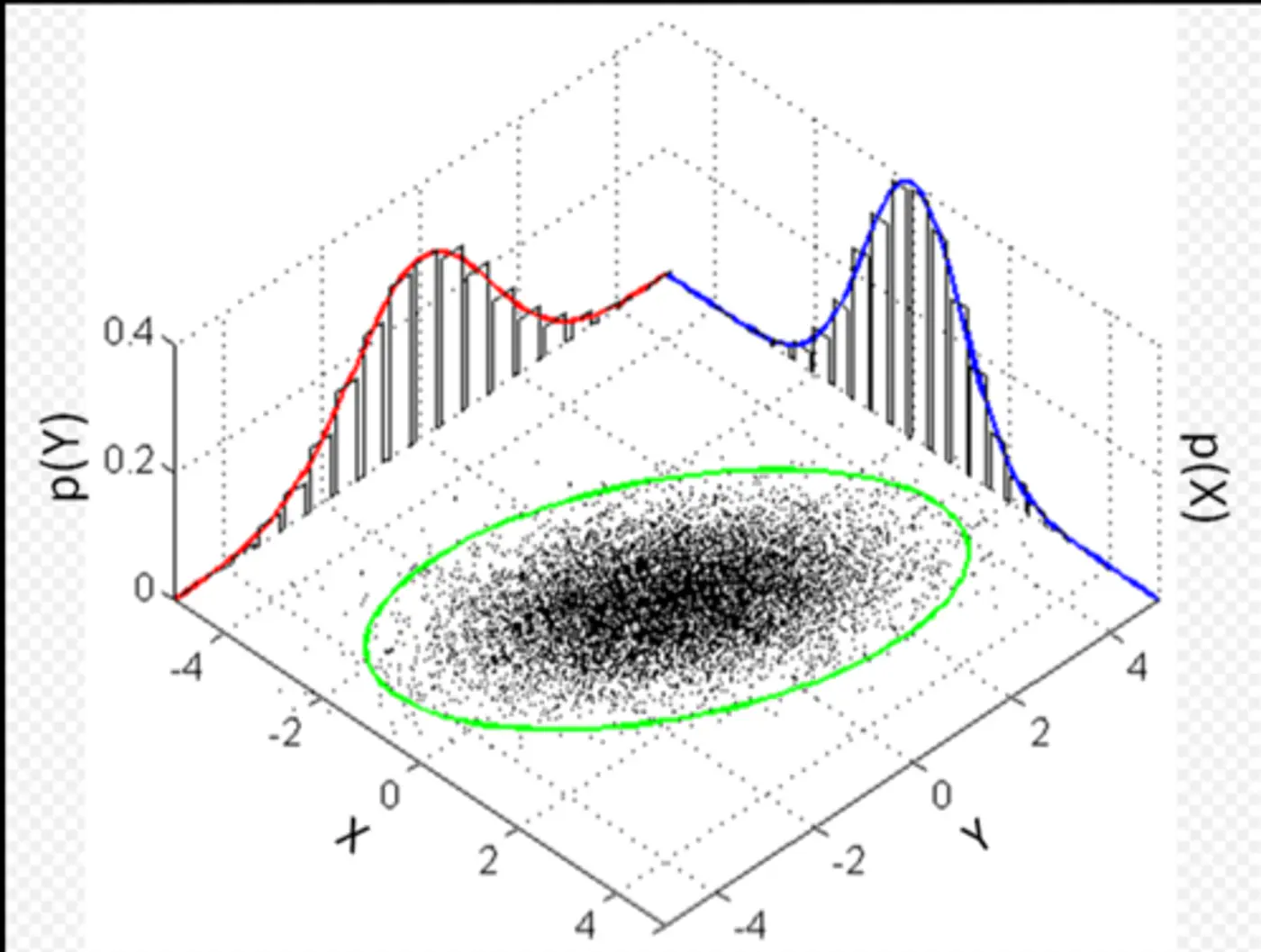
⭐️Imagine we are measuring the heights of people in a college.
We see a distribution with two peaks (bimodal).
We suspect there are two underlying groups:
Group A (Men) and Group B (Women).
Observation:
Observed Variable (X): Actual height measurements.
Latent Variable (Z): The ‘label’ (Man or Woman) for each person.
Note: We did not record gender, so it is ‘hidden’ or ‘latent’.
Latent Variable Model
A Latent Variable Model assumes that the observed data ‘X’ is generated by first picking a latent state ‘z’
and then drawing a sample from the distribution associated with that state.
GMM as Latent Variable Model
⭐️GMM is a latent variable model, meaning each data point \(\mathbf{x}_{i}\) is assumed to have an associated unobserved (latent) variable
\(z_{i}\in \{1,\dots ,K\}\) indicating which component generated it.
Note: We observe the data point, but we do not observe which cluster it belongs to (\(z_i\)).
Latent Variable Purpose
👉If we knew the value of \(z_i\) (component indicator) for every point, estimating the parameters of each Gaussian component would be straightforward.
Note: The challenge lies in estimatingboth the parameters of the Gaussians and the values
of the latent variables simultaneously.
The log-likelihood of the ‘complete data’ simplifies into a sum of logarithms:
\[\sum _{i}\log (\pi _{z_{i}}\mathcal{N}(x_{i}|\mu _{z_{i}},\Sigma _{z_{i}}))\]
Every point is assigned to exactly one cluster, so the sum disappears because there is only one cluster responsible for that point.
Note: This allows the logarithm to act directly on the exponential term of the Gaussian, leading to simple linear equations.
Hard Assignment Simplifies Estimation
👉When ‘z’ is known, every data point is ‘labeled’ with its parent component. To estimate the parameters (mean \(\mu_k\) and covariance \(\Sigma_k\)) for a specific component ‘k’ :
Gather all data points \(x_i\), where \(z_i\)= k.
Calculate the standard Maximum Likelihood Estimate.(MLE) for that single Gaussian using only those points.
Closed-Form Solution
⭐️ Knowing ‘z’ provides exact counts and component assignments, leading to direct formulae for the parameters:
Mean (\(\mu_k\)): Arithmetic average of all points assigned to component ‘k’.
Covariance (\(\Sigma_k\)): Sample covariance of all points assigned to component ‘k’.
Mixing Weight (\(\pi_k\)): Fraction of total points assigned to component ‘k’.
⭐️GMM is a latent variable model, where the variable \(z_i\) is a latent (hidden) variable that indicates which specific
Gaussian component or cluster generated a particular data point.
Chicken 🐓 & Egg 🥚 Problem
If we knew the parameters (\(\mu, \Sigma, \pi\)) we could easily calculate which cluster ‘z’ each point belongs to (using probability).
If we knew the cluster assignments ‘z’ of each point, we could easily calculate the parameters for each cluster (using simple averages).
🦉But we do not know either of them, as the parameters of the Gaussians - we aim to find and
cluster indicator latent variable is hidden.
Break the Loop 🔁
⛓️💥Guess one, i.e, cluster assignment ‘z’ to find the other, i.e, parameters \(\mu, \Sigma, \pi\).
But \(z_{ik}\) is a ‘hard’ assignment’ (either ‘0’ or ‘1’).
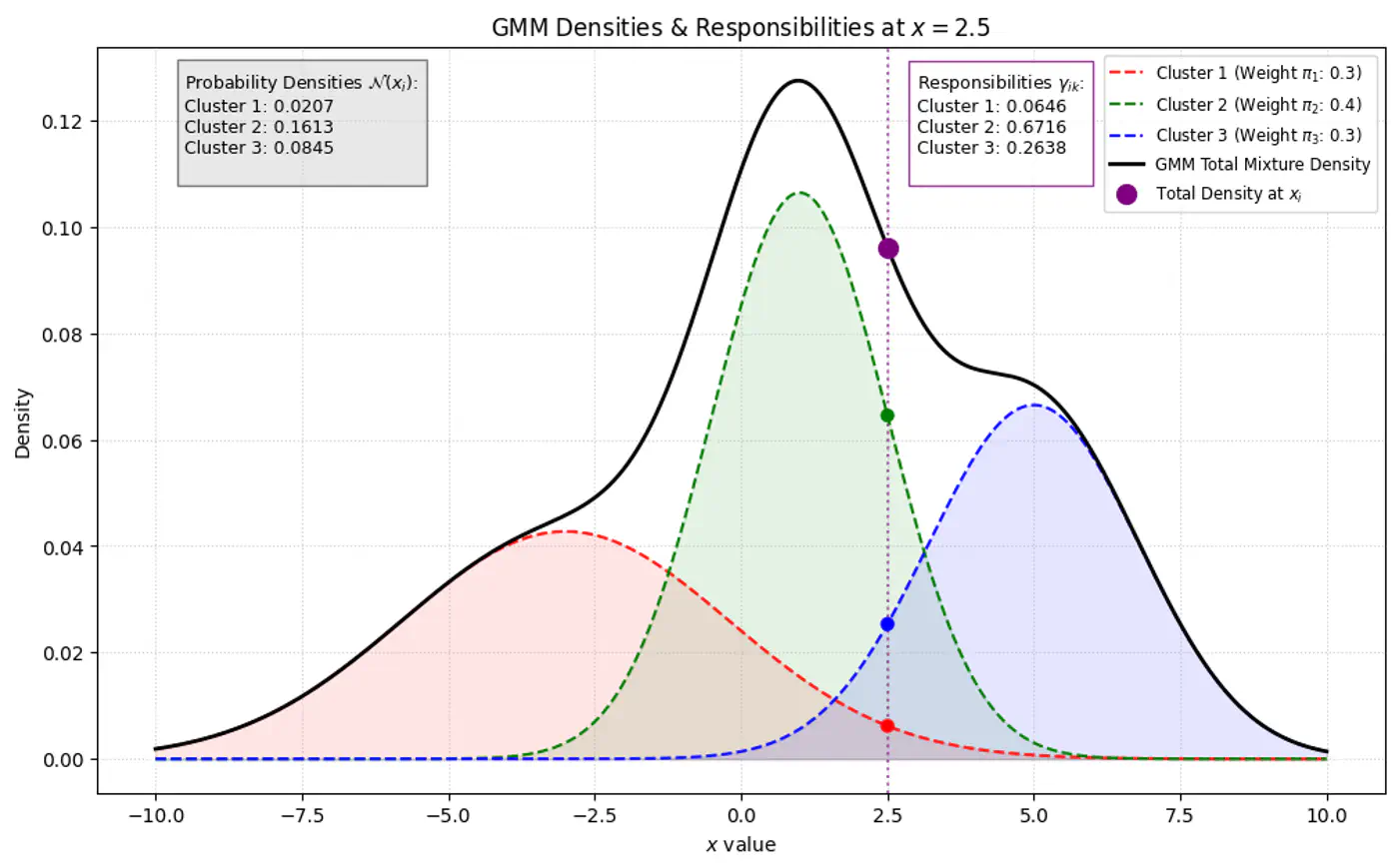
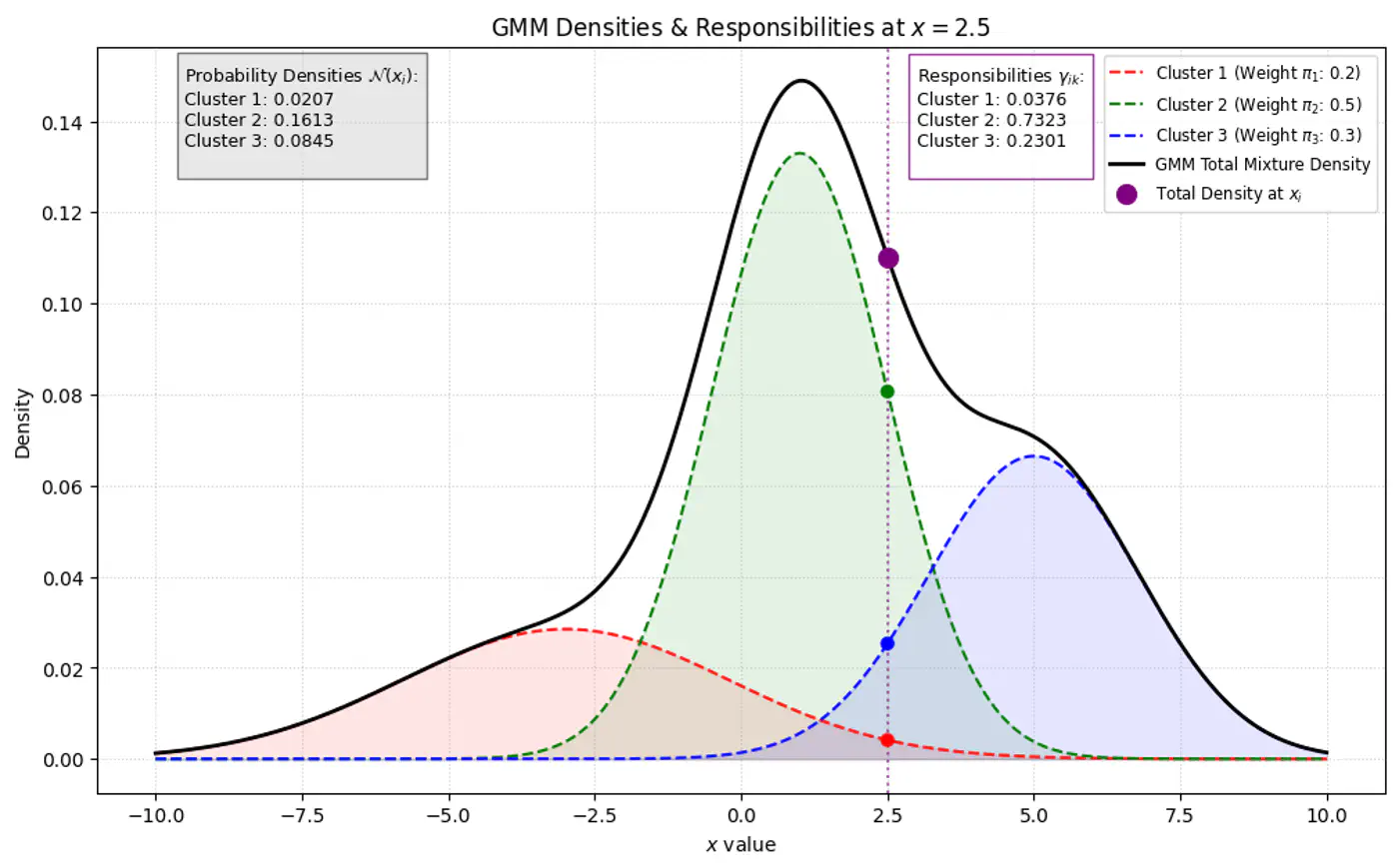
🦆 Because we do not observe ‘z’, we use another variable ‘Responsibility’ (\(\gamma_{ik}\)) as
a ‘soft’ assignment (value between 0 and 1).
🐣 \(\gamma_{ik}\) is the expected value of the latent variable \(z_{ik}\), given the observed data \(x_{i}\) and
parameters \(\Theta\).
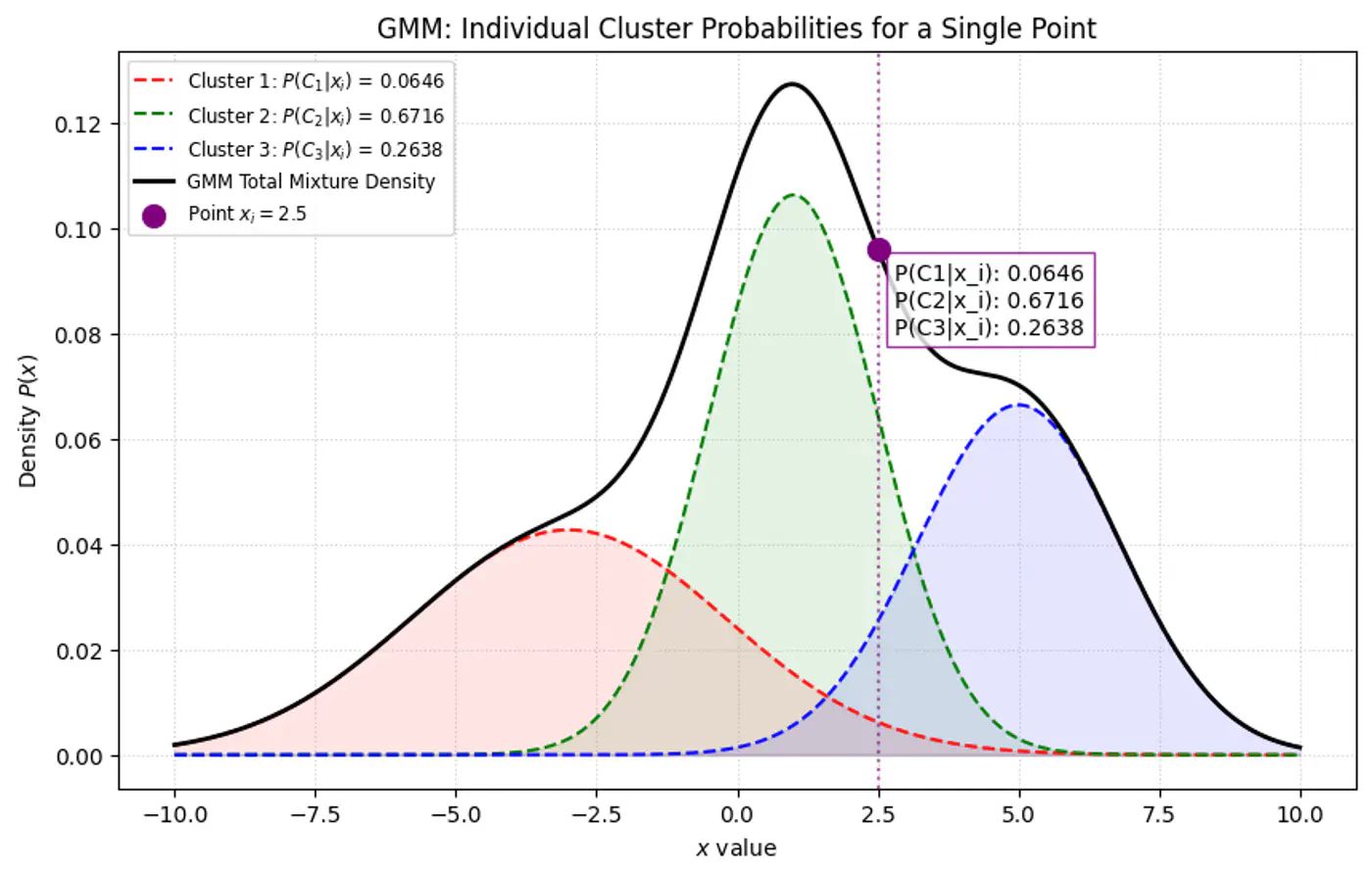
\[\gamma _{ik}=E[z_{ik}\mid x_{i},\theta ]=P(z_{ik}=1\mid x_{i},\theta )\]
Note: \(\gamma_{ik}\) is the posterior probability (or ‘responsibility’) that cluster ‘k’ takes for
explaining data point \(x_{i}\).
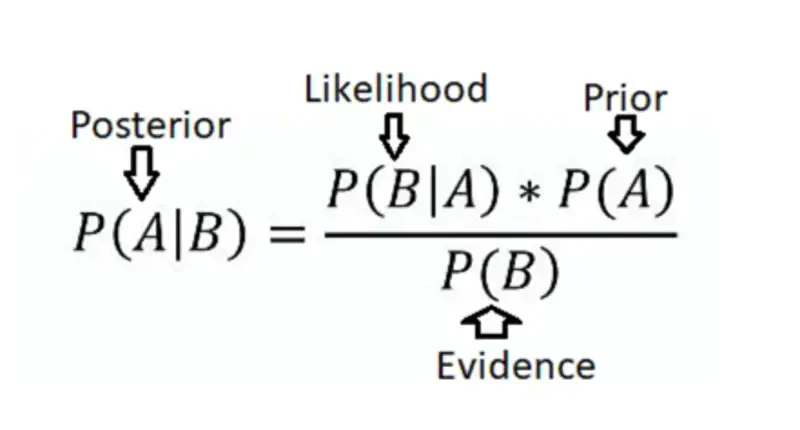
⭐️Using Bayes’ Theorem, we derive responsibility (posterior probability that component ‘k’ generated data point \(x_i\))
by combining the prior/weights (\(\pi_k\)) and the likelihood (\(\mathcal{N}(x_{i}\mid \mu _{k},\Sigma _{k})\)).
\(\pi_k\) : Probability that a randomly selected data point \(x_i\) belongs to the k-th component before we even look
at the specific value of \(x_i\), such that \(\pi_k \ge 0\) and \(\sum _{k=1}^{K}\pi _{k}=1\).
Maximization Step
👉Update the parameters (\(\mu, \Sigma, \pi\)) by calculating weighted versions of the standard MLE formulas using responsibilities as weight 🏋️♀️.
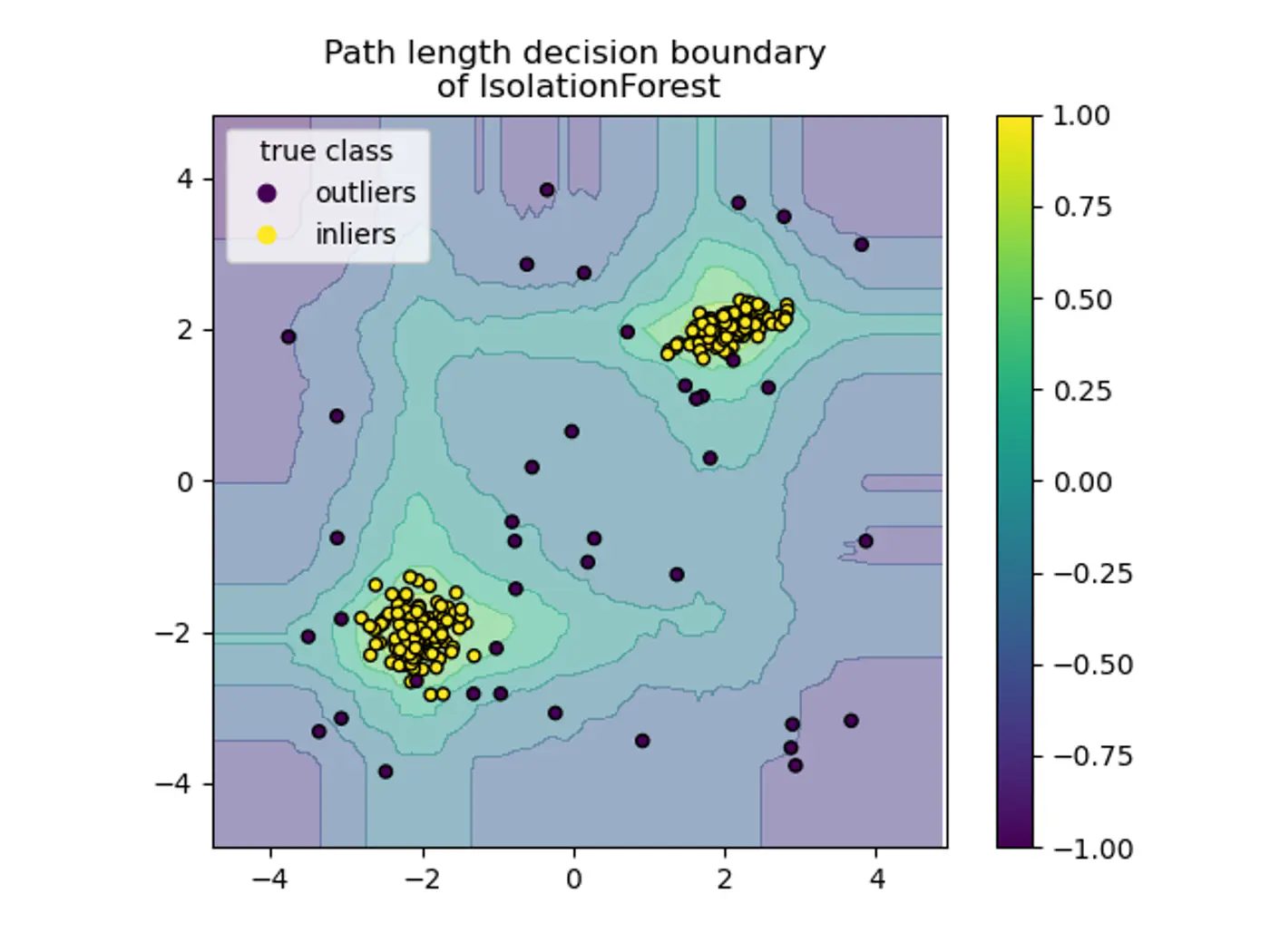
🦄 Anomaly is a rare item, event or observation which deviates significantly from the majority of the data and does
not conform to a well-defined notion of normal behavior.
Note: Such examples may arouse suspicions of being generated by a different mechanism, or appear inconsistent
with the remainder of that set of data.
Anomaly Detection
🐙 Anomaly detection (Outlier detection or Novelty detection) is the identification of unusual patterns
or anomalies or outliers in a given dataset.
What to do with Outliers ?
❌ Remove Outliers:
Rejection or omission of outliers from the data to aid statistical analysis, for example to compute the mean or standard deviation of the dataset.
Remove outliers for better predictions from models, such as linear regression.
🔦Focus on Outliers:
Fraud detection in banking and financial services.
Cyber-security: intrusion detection, malware, or unusual user access patterns.
Anomaly Detection Methods 🐉
Supervised
Semi-Supervised
Unsupervised (most common) ✅
Note: Labeled anomaly data is often unavailable in real-world scenarios.
Known Methods 🐈
Statistical Methods: Z-Score, large value means outlier, IQR, point beyond fences (Q1 - 1.5*IQR or Q3 + 1.5*IQR) is flagged as an outlier.
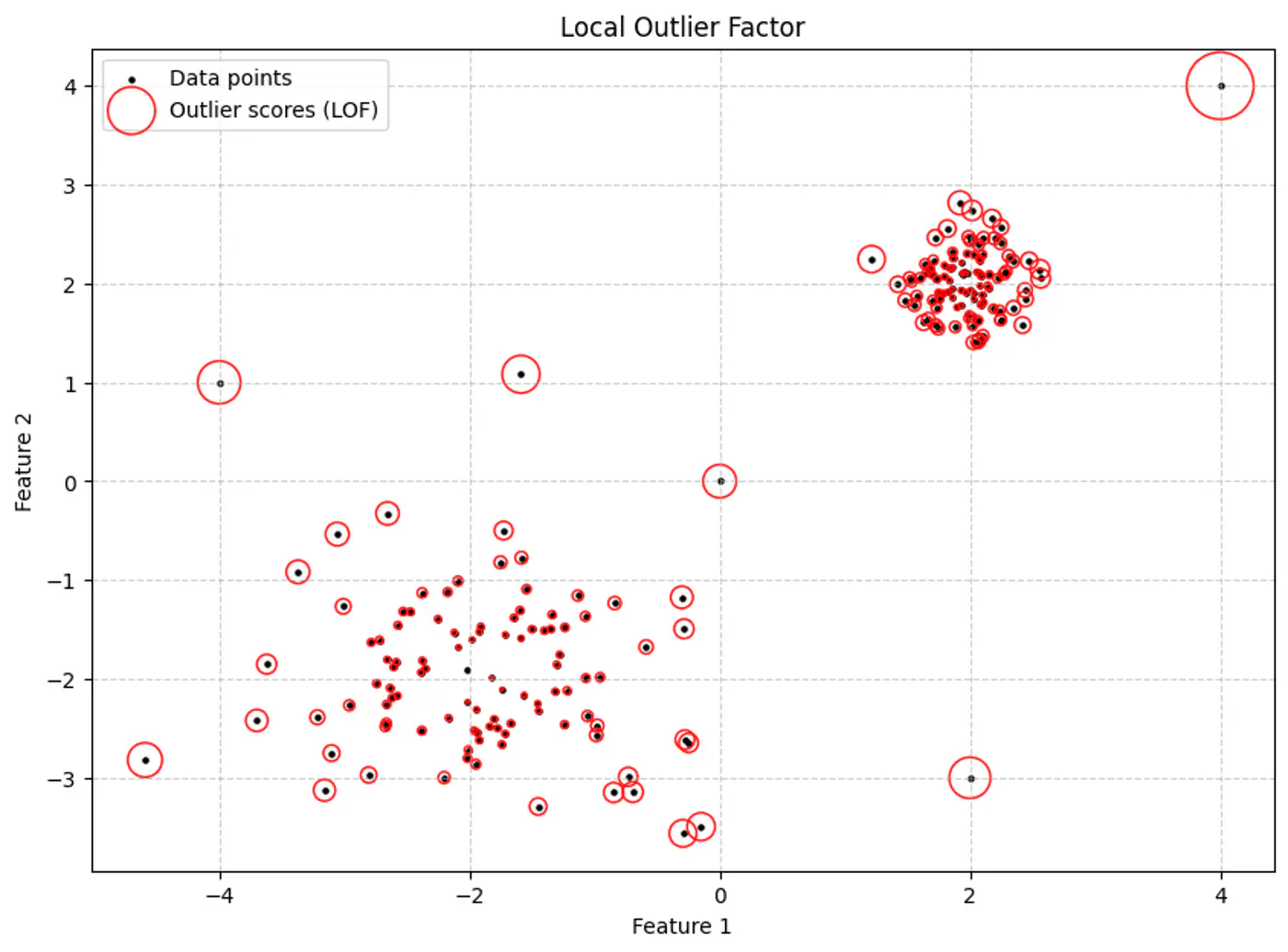
Distance Based: KNN, points far from their neighbors as potential anomalies.
Density Based: DBSCAN, points in low density regions are considered outliers.
Clustering Based: K-Means, points far from cluster centroids that do not fit any cluster are anomalies.
Detect anomalies in multivariate Gaussian data, such as, biometric data (height/weight) where features
are normally distributed and correlated.
Assumption: The data can be modeled by a Gaussian distribution.
Intuition 💡
In a normal distribution, most data points cluster around the mean, and the probability density decreases
as we move farther away from the center.
Issue with Euclidean Distance 🐲
🌍 Euclidean distance measures the simple straight-line distance from the center of the cloud.
👉If the data is spherical, this works fine.
🦕 However, real-world data is often stretched or skewed (e.g., taller people are generally heavier),
due to correlations between variables, forming an elliptical shape.
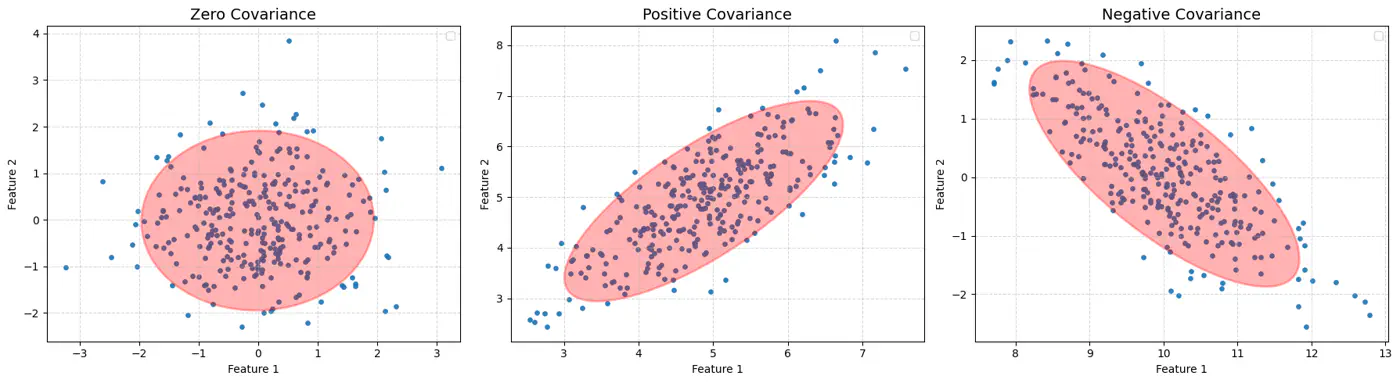
Mahalanobis Distance (Solution)
⭐️Mahalanobis distance essentially re-scales the data so that the elliptical distribution appears spherical,
and then measures the Euclidean distance in that transformed space.
👉This way, it measures how many standard deviations(\(\sigma\)) away a point is from the mean, considering the data’s spread and correlation (covariance).
MCD algorithm is used to find the covariance matrix \(\Sigma\) with minimum determinant, so that the
volume of the ellipsoid is minimized.
Initialization: Select several random subsets of size h < n (default h = \(\frac{n+d+1}{2}\), d = # dimensions),
representing ‘robust’ majority of the data.
Calculate preliminary mean (\(\mu\)) and covariance (\(\Sigma\)) for each random subset.
Concentration Step: Iterative core of the algorithm designed to ‘tighten’ the ellipsoid.
Calculate Distances: Compute the Mahalanobis distance of all ’n’ points in the dataset from the current
subset’s mean (\(\mu\)) and covariance (\(\Sigma\)).
Select New Subset: Identify the ‘h’ points with the smallest Mahalanobis distances.
These are the points most centrally located relative to the current ellipsoid.
Update Estimates: Calculate a new and based only on these ‘h’ most central points.
Repeat 🔁: The steps repeat until the determinant stops shrinking.
Note: Select the best subset that achieved the absolute minimum determinant.
Limitations
Assumptions
Gaussian data.
Unimodal data (single center).
Cost 💰of covariance matrix \(\Sigma^{-1}\) inversion is O(d^3).
⭐️Only one class of data (normal, non-outlier) is available for training, making standard supervised learning
models impossible.
e.g. Only normal observations are available for fraud detection, cyber attack, fault detection etc.
Intuition
Problem 🦀
🦂 The core problem is to build a model that can distinguish between ‘normal’ and ‘anomalous’ data
when we only have examples of the ‘normal’ class during training.
🦖 We need to find a decision boundary that is as compact as possible while still encompassing the bulk of the
training data.
Solution 🦉
💡Instead of finding a hyperplane that separates two different classes, we find a hyperplane that best separates the
normal data points from the origin (0,0) in the feature space 🚀.
Goal 🎯
🦍 Define a boundary for a single class in high-dimensional space where data might be non-linearly distributed
(e.g.‘U’ shape).
🦧 Use the Kernel Trick to project data into a higher-dimensional space and find a hyperplane
that separates the data from the origin with the maximum margin.
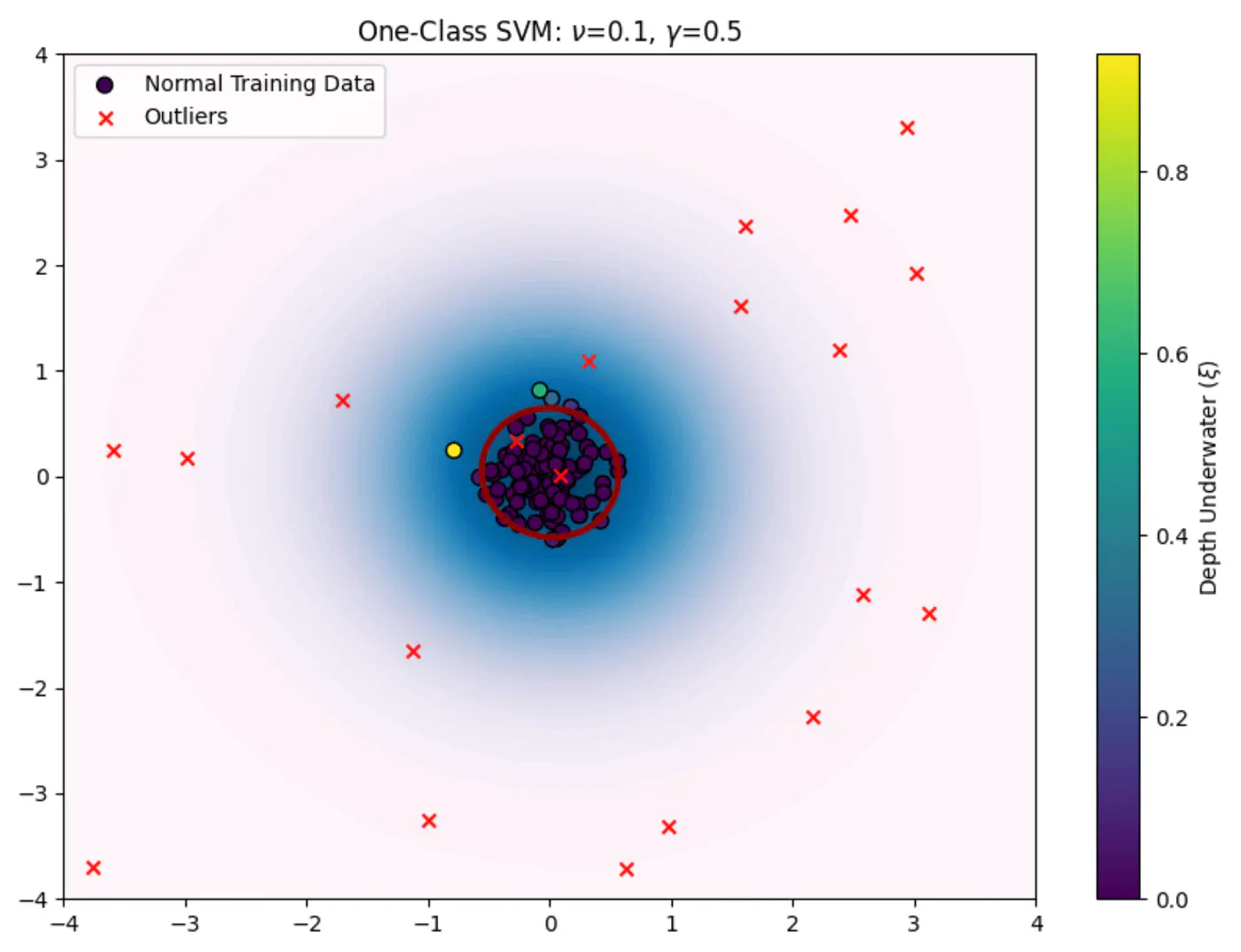
One Class SVM
⭐️OC-SVM, as introduced by Bernhard Schölkopf et al., uses a hyperplane ‘H’ defined by a weight vector \(\mathbf{w}\)
and a bias term \(\rho\).
\(\phi (\mathbf{x}_{i})\): RBF kernel function \(K(x, y) = \exp(-\gamma \|x-y\|^2)\) that maps the data into a higher-dimensional feature space, making it easier to separate from the origin.
\(\mathbf{w}\): normal vector to the separating hyperplane.
\(\rho\): scalar bias term that determines the offset of the hyperplane from the origin.
\(\xi_i\): Slack variables that allow some data points to fall on the ‘wrong’ side of the hyperplane (inside the anomalous region) to prevent overfitting.
N: total number of training points.
\(\nu\): hyper-parameter between 0 and 1. It acts as an upper bound on the fraction of outliers (training data points outside the boundary) and a lower bound on the fraction of support vectors.
Working 🦇
\(\frac{1}{2}\|\mathbf{w}\|^{2}\): aims to maximize the margin/compactness of the region.
\(\frac{1}{\nu N}\sum _{i=1}^{N}\xi _{i}-\rho\): penalizes points (outliers) that violate the boundary constraints.
After solving the optimization problem using standard quadratic programming techniques,
we obtain the optimal \(\mathbf{w}^{*}\) and \(\rho ^{*}\).
For a new data point \(x_{new}\), decision function is:
⭐️Geographic fraud detection: A $100 transaction might be ‘normal’ in New York but an ‘outlier’ in a small rural village.
Intuition 💡
‘Local context matters.’
Global distance metrics fail when density is non-uniform.
🦄 An outlier is a point that is ‘unusual’ relative to its immediate neighbors,
regardless of how far it is from the center of the entire dataset.
Problem 🦀
💡Traditional distance-based outlier detection methods, such as, KNN, often struggle with datasets where data
is clustered at varying densities.
A point in a sparse region might be considered an outlier by a global method, even if it is a normal part of that sparse cluster.
Conversely, a point very close to a dense cluster might be an outlier relative to that specific neighborhood.
Solution 🦉
👉Calculate the relative density of a point compared to its immediate neighborhood.
e.g. If the neighbors are in a dense crowd and the point is not, it is an outlier.
Goal 🎯
📌Compare the density of a point to the density of its neighbors.
Local Outlier Factor (LOF)
Local Outlier Factor (LOF) is a density-based algorithm designed to detect anomalies by measuring the
local deviation of a data point relative to its neighbors.
👉Size of the red circle represents the LOF score.
LOF Score Calculation 🔢
K-Distance (\(k\text{-dist}(p)\)):
The distance from point ‘p’ to its k-th nearest neighbor.
\(\text{dist}(p,o)\): actual Euclidean distance between ‘p’ and ‘o’.
This acts as ‘smoothing’ factor.
If point ‘p’ is very close to ‘o’ (inside o’s k-neighborhood), round up distance to \(k\text{-dist}(o)\).
Local Reachability Density (\(\text{lrd}_{k}(p)\)):
The inverse of the average reachability distance from ‘p’ to its k-neighbors (\(N_{k}(p)\)).
\[\text{lrd}_{k}(p)=\left[\frac{1}{|N_{k}(p)|}\sum _{o\in N_{k}(p)}\text{reach-dist}_{k}(p,o)\right]^{-1}\]
High LRD: Neighbors are very close; the point is in a dense region.
Low LRD: Neighbors are far away; the point is in a sparse region.
Local Outlier Factor (\(\text{LOF}_{k}(p)\)):
The ratio of the average ‘lrd’ of p’s neighbors to p’s own ‘lrd’.
\[\text{LOF}_{k}(p)=\frac{1}{|N_{k}(p)|}\sum _{o\in N_{k}(p)}\frac{\text{lrd}_{k}(o)}{\text{lrd}_{k}(p)}\]
LOF Score 🔢 Interpretation
LOF ≈ 1: Point ‘p’ has similar density to its neighbors (inlier).
LOF > 1: Point p’s density is much lower than its neighbors’ density (outlier).
Credit card fraud detection in datasets with millions of rows and hundreds of features.
Note: Supervised learning requires balanced, labeled datasets (normal vs. anomaly), which are rarely available in real-world scenarios like fraud or cyber-attacks.
Intuition 💡
🦥 ‘Flip the logic.’
🦄 ‘Anomalies’ are few and different, so they are much easier to isolate from the rest of the data than normal points.
Problem 🦀
🐦🔥 ‘Curse of dimensionality.’
🐎 Distance based (K-NN), and density based (LOF) algorithms require calculation of distance between all pair of points.
🐙 As the number of dimensions and data points grows, these calculations become exponentially more expensive 💰
and less effective.
Solution 🦉
Use a tree-based 🌲 approach with better time ⏰ complexity O(nlogn), making it highly scalable for massive datasets
and robust in high-dimensional spaces without needing expensive distance metrics.
Goal 🎯
‘Randomly partition the data.’
🦄 If a point is an outlier, it will take fewer partitions (splits) to isolate it into a leaf 🍃 node
compared to a point that is buried deep within a dense cluster of normal data.
Isolation Forest (iForest) 🌲🌳
🌳Isolation Forest uses an ensemble of ‘Isolation Trees’ (iTrees) 🌲.
👉iTree (Isolation Tree) 🌲 is a proper binary tree structure specifically designed to separate individual data points through random recursive partitioning.
Algorithm ⚙️
Sub-sampling:
Select a random subset of data (typically 256 instances) to build an iTree.
Tree Construction: Randomly select a feature.
Randomly select a split value between the minimum and maximum values of that feature.
Divide the data into two branches based on this split.
Repeat recursively until the point is isolated or a height limit is reached.
Forest Creation:
Repeat 🔁 the process to create ‘N’ trees (typically 100).
Inference:
Pass a new data point through all trees, calculate the average path length, and compute the anomaly score.
Scoring Function 📟
⭐️🦄 Assign an anomaly score based on the path length h(x) required to isolate a point ‘x’.
Path Length (h(x)): The number of edges ‘x’ traverses from the root node to a leaf node.
Average Path Length (c(n)): Since iTrees are structurally similar to Binary Search Trees (BST),
the average path length for a dataset of size ’n’ is given by:
\[c(n)=2H(n-1)-\frac{2(n-1)}{n}\]
where, H(i) is the harmonic number, estimated as \(\ln (i)+0.5772156649\) (Euler’s constant).
🦄 Anomaly Score
To normalize the score between 0 and 1, we define it as:
\[s(x,n)=2^{-\frac{E(h(x))}{c(n)}}\]
👉E(H(x)): is the average path length of across a forest of trees 🌲.
\(s\rightarrow 1\): Point is an anomaly; Path length is very short.
\(s\approx 0.5\): Point is normal, path length approximately equal to c(n).
\(s\rightarrow 0\): Point is normal; deeply buried point, path length is much larger than c(n).
Drawbacks
Axis-Parallel Splits:
Standard iTrees 🌲 split only on one feature at a time, so:
We do not get a smooth decision boundary.
Anything off-axis has a higher probability of being marked as an outlier.
Note: Extended Isolation Forestfixes this by using random slopes.
Score Sensitivity: The threshold for what constitutes an ‘anomaly’ often requires manual tuning or domain knowledge.
⭐️Estimate the parameters of a model from a set of observed data that contains a significant number of outliers.
Intuition 💡
👉Ordinary Least Squares use all data points to find a fit.
However, a single outlier can ‘pull’ the resulting line significantly, leading to a poor representative model.
💡If we pick a very small random subset of points, there is a higher probability that this small subset contains only
good data (inliers) compared to a large set.
Problem 🦀
Ordinary Least Squares (OLS) minimizes the Sum of Errors.
A huge outlier has an exponentially large impact on the final line.
Solution 🦉
💡Instead of using all points, iteratively pick the smallest possible random subset to fit a model,
then check (votes) how many other points in the dataset ‘agree’ with that model.
This gives the name to our algorithm:
Random: Random subsets.
Sampling: Small subsets.
Consensus: Agreement with other points.
RANSAC Algorithm ⚙️
Random Sampling:
Randomly select a Minimal Sample Set (MSS) of ’n’ points from the input data ‘D’.
e.g. n=2 for a line, or n=3 for a plane in 3D.
Model Fitting:
Compute the model parameters using only these ’n’ points.
Test:
For all other points in ‘D’, calculate the error relative to the model.
👉 Points with error < \(\tau\)(threshold) are added to the ‘Consensus Set’.
Evaluate:
If the consensus set is larger than the previous best, save this model and set.
Repeat 🔁:
Iterate ‘k’ times.
Refine (Optional):
Once the best model is found, re-estimate it using all points in the final consensus set (usually via Least Squares) for a more precise fit.
👉Example:
How Many Iterations ‘k’ ?
👉To ensure the algorithm finds a ‘clean’ sample set (no outliers) with a desired probability(often 99%),
we use the following formula:
\[k=\frac{\log (1-P)}{\log (1-w^{n})}\]
k: Number of iterations required.
P: Probability that at least one random sample contains only inliers.
w: Ratio of inliers in the dataset (number of inliers / total points).
Feature Extraction: Create a smaller set of meaningful features from a larger one.
Data Visualization: Project high-dimensional data down to 2 or 3 dimensions.
Assumption: Linear relationship between features.
Intuition 💡
💡‘Information = Variance’
☁️ Imagine a cloud of points in 2D space. 👀 Look for the direction (axis) along which the data is most ‘spread out’.
🚀 By projecting data onto this axis, we retain the maximum amount of information (variance).
👉Example 1: Var(Feature 1) < Var(Feature 1)
👉Example 2: Red line shows the direction of maximum variance
Principal Component Analysis
🧭 Finds the direction of maximum variance in the data.
Note: Some loss of information will always be there in dimensionality reduction,
because there will be some variability in data along the direction that is dropped, and that will be lost.
Goal 🎯
Fundamental goal of PCA is to find the new set of orthogonal axes, called the principal components,
onto which the data can be projected, such that, the variance of the projected data is maximum.
PCA as Optimization Problem 🦀
PCA seeks a direction 🧭, represented by a unit vector \(\hat{u}\) onto which data can be projected to maximize variance.
The projection of a mean centered data point \(x_i\) onto \(u\) is \(u^Tx_i\).
The variance of these projections can be expressed as \(u^{T}\Sigma u\), where \(\Sigma\) is the data’s covariance matrix.
Why Variance of Projection is \(u^{T}\Sigma u\)?
Data: Let \(X = \{x_{1},x_{2},\dots ,x_{n}\}\) is the mean centered (\(\bar{x} = 0\)) dataset.
Projection of point \(x_i\) on \(u\) is \(z_i = u^Tx_i\)
👉 To prevent infinite variance, PCA constrains \(u\) to be a unit vector (\(\|u\|=1\)).
\[\text{maximize\ }u^{T}\Sigma u, \quad \text{subject\ to\ }u^{T}u=1\]
Note: This constraint forces the optimization algorithm to focus purely on the direction that maximizes variance,
rather than allowing it to artificially inflate the variance by increasing the length of the vector.
Constrained Optimization Solution 🦉
⏲️ Lagrangian function: \(L(u,\lambda )=u^{T}\Sigma u-\lambda (u^{T}u-1)\) 🔦 To find \(u\) that maximizes above constrained optimization:
\[\frac{\partial L}{\partial u} = 0\]\[\implies 2\Sigma u - 2\lambda u = 0 \implies \Sigma u = \lambda u\]\[\because \frac{\partial }{\partial x}x^{T}Ax=2Ax \text{ for symmetric } A\]
💎 This is the standard Eigenvalue Equation. 🧭 So, the optimal directions \(u\) are the eigenvectors of the covariance matrix \(\Sigma\).
👉 To see which eigenvector maximizes variance, substitute the result back into the variance equation:
🧭 Since the variance equals the eigenvalue \(\lambda\), the direction \(u\) that maximizes variance is the eigenvector associated with the largest eigenvalue.
PCA Algorithm ⚙️
Center the data: \(X = X - \mu\)
Compute the Covariance Matrix: \(\Sigma = \frac{1}{n-1} X^T X\)
Compute Eigenvectors and Eigenvalues of \(\Sigma\) .
Sorteigenvalues in descending order and select the top ‘k’ eigenvectors.
Project the original data onto the subspace: \(Z = X W_k\) where, \(W_{k}=[u_{1},u_{2},\dots ,u_{k}]\) , matrix
formed by ‘k’ eigenvectors corresponding to ‘k’ largest eigenvalues.
⭐️ Visualizing complex datasets, such as MNIST handwritten digits, text embeddings, or biological data,
where clusters are expected to form naturally.
Intuition 💡
👉 PCA preserves variance, not neighborhoods. 🔬 t-SNE focuses on the ‘neighborhood’ (local structure).
💡Tries to keep points that are close together in high-dimensional space close together in low-dimensional space.
t-SNE
⭐️ Non-linear dimensionality reduction technique to visualize high-dimensional data (like images, gene expressions,
text embeddings) in a lower-dimensional space (typically 2D or 3D) by preserving local structures, making clusters
and patterns visible.
Problem 🦀
👉 Map high-dimensional points to low-dimensional points , such that the pairwise similarities are preserved, while solving the ‘crowding problem’ (where points collapse into a single cluster).
👉 Crowding Problem
Solution 🦉
📌 Convert Euclidean distances into conditional probabilities representing similarities. ⚖️ Minimize the divergence between the probability distributions of the high-dimensional (Gaussian)
and low-dimensional (t-distribution) spaces.
Note: Probabilistic approach to defining neighbors is the core ‘stochastic’ element of the algorithm’s name.
High Dimensional Space 🚀(Gaussian)
💡The similarity of datapoint \(x_j\) to datapoint \(x_i\) is the conditional probability \(p_{j|i}\),
that \(x_i\) would pick \(x_j\) as its neighbor.
Note: If neighbors are picked in proportion to their probability density under a Gaussian centered at \(x_i\).
Note: Heavier tail spreads out dissimilar points more effectively, allowing moderately distant points to be
mapped further apart, preventing clusters from collapsing and ensuring visual separation and cluster distinctness.
Optimization 🕸️
👉 Measure the difference between the distributions ‘p’ and ‘q’ using the Kullback-Leibler (KL) divergence,
which we aim to minimize:
C : t-SNE cost function (sum of all KL divergences).
\(y_i, y_j\): coordinates of data points and in the low-dimensional space (typically 2D or 3D).
\(p_{ij}\): high-dimensional similarity (joint probability) between points \(x_i\) and \(x_j\), calculated using
a Gaussian distribution.
\(q_{ij}\): low-dimensional similarity (joint probability) between points \(y_i\) and \(y_j\), calculated using a Student’s t-distribution with one degree of freedom.
\((1+||y_{i}-y_{j}||^{2})^{-1}\): term comes from the heavy-tailed Student’s t-distribution, which helps mitigate the ‘crowding problem’ by allowing points that are moderately far apart to have a small attractive force.
Interpretation 🦒
💡 The gradient can be understood as a force acting on each point \(y_i\) in the low-dimensional map:
Attractive forces: If \(p_{ij}\) is large ⬆️ and \(q_{ij}\) is small ⬇️ (meaning two points were close in
the high-dimensional space but are far in the low-dimensional space),
the term \((p_{ij}-q_{ij})\) is positive, resulting in a strong attractive force pulling \(y_i\) and \(y_j\) closer.
Repulsive forces: If \(p_{ij}\) is small ⬇️ and \(q_{ij}\) is large ⬆️ (meaning two points were far in the high-dimensional space
but are close in the low-dimensional space), the term \((p_{ij}-q_{ij})\) is negative, resulting in a repulsive force
pushing \(y_i\) and \(y_j\) apart.
🐢Visualizing massive datasets where t-SNE is too slow.
⭐️ Creating robust low-dimensional inputs for subsequent machine learning models.
Intuition 💡
⭐️ Using a world map 🗺️ (2D)instead of globe 🌍 for spherical(3D) earth 🌏.
👉It preserves the neighborhood relationships of countries (e.g., India is next to China), and to a good degree, the global structure.
UMAP
⭐️ Non-linear dimensionality reduction technique to visualize high-dimensional data (like images, gene expressions)
in a lower-dimensional space (typically 2D or 3D), preserving its underlying structure and relationships. 👉 Constructs a high-dimensional graph of data points and then optimizes a lower-dimensional layout to closely match this graph, making complex datasets understandable by revealing patterns, clusters, and anomalies.
Note: Similar to t-SNE but often faster and better at maintaining global structure.
Problem 🦀
👉 Create a low-dimensional representation that preserves the topological connectivity and manifold structure of
the high-dimensional data efficiently.
Solution 🦉
💡 Create a weighted graph (fuzzy simplicial set) representing the data’s topology and then find a low-dimensional
graph that is as structurally similar as possible.
Note: Fuzzy means instead of using binary 0/1, we use weights in the range [0,1] for each edge.
High Dimensional Graph (Manifold Approximation)
UMAP determines local connectivity based on a user-defined number of neighbors (n_neighbors).
Normalizes distances locally using the distance to the nearest neighbor (\(\rho_i\)) and a scaling factor (\(\sigma_i\)) adjusted to enforce local connectivity constraints.
The weight \(W_{ij}\) (fuzzy similarity) in high-dimensional space is:
\[W_{ij}=\exp \left(-\frac{\max (0,\|x_{i}-x_{j}\|-\rho _{i})}{\sigma _{i}}\right)\]
Note: This ensures that the closest point always gets a weight of 1, preserving local structure.
Low Dimensional Space (Optimization)
👉In the low-dimensional space (e.g., 2D), UMAP uses a simple curve (similar to the t-distribution used in t-SNE)
for edge weights:
\[Z_{ij}=(1+a\|y_{i}-y_{j}\|^{2b})^{-1}\]
Note: The parameters ‘a’ and ‘b’ are typically fixed based on the ‘min_dist’ user parameter
(e.g. min_dist = 0.1, then a≈1,577, b≈0.895).
Optimization
⭐️ Unlike t-SNE’s KL divergence, UMAP minimizes the cross-entropy between the high-dimensional weights \(W_{ij}\)
and the low-dimensional weights \(Z_{ij}\).
Attractive Force: \(W_{ij}\) high; make \(Z_{ij}\) high to make the log \(\frac{W_{ij}}{Z_{ij}} \)term small.
Repulsive Force: \(W_{ij}\) low; make \(Z_{ij}\) low to make the \(log\frac{1-W_{ij}}{1-Z_{ij}}\) term small.
Note: This push and pull of 2 ‘forces’ will make the data in low dimensions settle into a position that is overall a good representation of the original data in higher dimensions.
Stochastic Gradient Descent
👉 Optimization uses stochastic gradient descent (SGD) to minimize this cross-entropy,
balancing attractive forces (edges present in high-dimension, \(W_{ij} \approx 1\))
and repulsive forces (edges absent in high-dimension, \(W_{ij} \approx 0\)).
Messy and Incomplete. We need to pre-process the data to make it:
Clean
Consistent
Mathematically valid
Computationally stable
👉 So that, the machine learning algorithm can safely consume the data.
Missing Values
Missing Completely At Random (MCAR)
The missingness occurs entirely by chance, such as due to a technical glitch during data collection or
a random human error in data entry.
Missing At Random (MAR)
The probability of missingness depends on the observed data and not on the missing value itself.
e.g. In some survey, the age of many females are missing, because they may not like to disclose the information.
Missing Not At Random (MNAR)
The probability of missingness is directly related to the unobserved missing value itself.
e.g. Individuals with very high incomes 💰may intentionally refuse to report their salary due to privacy concerns,
making the missing data directly dependent on the high income 💰value itself.
Handle Missing Values (Imputation)
Simple Imputation:
Mean: Normally distributed numerical features.
Median: Skewed numerical features.
Mode: Categorical features, most frequent.
KNN Imputation:
Replace the missing value with mean/median/mode of ‘k’ nearest (similar) neighbors of the missing value.
Predictive Imputation:
Use another ML model to estimate missing values.
Multivariate Imputation by Chained Equations (MICE):
Iteratively models each variable with missing values as a function of other variables using
flexible regression models (linear regression, logistic regression, etc.) in a ‘chained’ or sequential process.
Creates multiple datasets, using slightly different random starting points.
Handle Outliers 🦄
🦄 Outliers are extreme or unusual data points, can mislead models, causing inaccurate predictions.
Remove invalid or corrupted data.
Replace (Impute): Median or capped value to reduce impact.
Transform: Apply log or square root to reduce skew.
👉 For example: Log and Square Root Transformed Data
Scaling and Normalization
💡 If one feature ranges from 0-1 and another from 0-1000, larger feature will dominate the model.
Standardization (Z-score) :
μ=0, σ=1; less sensitive to outliers.
\(x_{std} = (x − μ) / σ\)
Min-Max Normalization:
Maps data to specific range, typically [0,1]; sensitive to outliers.
\(x_{minmax} = (x − min) / (max − min)\)
Robust Scaling:
Transforms features using median and IQR; resilient to outliers.
⭐️ Occurs when a model is trained using data that would not be available during real-world predictions,
leading to good training performance, but poor real‑world 🌎 performance. It is essentially the model ‘cheating’ by inadvertently accessing information about the target variable.
👉Any information from the validation/test set must NOT influence training, directly or indirectly. ❓So, how do we prevent this leakage of information or data leakage from training to validation or test set ?
Train-Test Contamination
❌ Wrong: Applying preprocessing (like global StandardScaler, Mean_Imputation, Target_Encoding etc.) on the entire dataset before splitting.
✅ Right: Compute mean, variance, etc. only on the training data and use the same for validation and test data.
Preventing Leakage in Cross-Validation:
❌ Wrong: Perform preprocessing (e.g., scaling, normalization, missing value imputation) on the entire dataset before passing it to cross_val_score.
✅ Right: Use sklearn.pipeline.Pipeline; Pipeline ensures that the ‘validation fold’ remains unseen until the transformation is applied using the training fold’s parameters.
Temporal Leakage
This happens in Time Series ⏰ data.
❌ Wrong: Use standard random CV; it allows the model to ‘peek into the future’.
✅ Right: Use Time-Series Nested Cross-Validation (Forward Chaining) instead of random shuffling.
Target Leakage
❌ Wrong: Include features that are only available after the event we are trying to predict and are proxy for the target.
e.g. Including number_of_late_payments in a model to predict whether a person applying for a bank loan will default ?
✅ Right: Do not include such features during training.
Group Leakage:
❌ Wrong: If you have multiple rows that are correlated (same user).
For the same patient or user, you put some rows in Train and others in Test.
✅ Right: Use GroupKFold to ensure all data from a specific group stays together in one fold.
Can we explain why the model made a certain prediction ?
👉 Because without this capability the machine learning is like a black box to us.
👉 We should be able to answer which features had most influence on output.
⭐️ Let’s understand ‘Feature Importance’ and why the ML model output’s interpretability is important ?
Feature Importance
\[\hat{y_i} = w_0 + w_1x_{i_1} + w_2x_{i_2} + \dots + w_dx_{i_d}\]\[w_1 > w_2 : f_1 \text{ is more important feature than } f_2\]\[
\begin{align*}
w_j &> 0: f_j \text { is directly proportional to target variable} \\
w_j &= 0: f_j \text { has no relation to target variable} \\
w_j &< 0: f_j \text { is inversely proportional to target variable} \\
\end{align*}
\]
Note: Weights 🏋️♀️ represent the importance of feature with standardized data.
Why Model Interpretability Matters ?
💡 Overall model behavior + Why this prediction?
Trust: Stakeholders must trust predictions.
Model Debuggability: Detect leakage, spurious correlations.
Feature engineering: Feedback loop.
Regulatory compliance: Data privacy, GDPR.
Trust
⭐️ Stakeholders Must Trust Predictions.
Users, executives, and clients are more likely to trust and adopt an AI system if they understand its reasoning.
This transparency is fundamental, especially in high-stakes applications like healthcare, finance, or law,
where decisions can have a significant impact.
Model Debuggability
⭐️ By examining which features influence predictions, developers can identify if the model is using
misleading or spurious correlations, or if there is data leakage
(where information not available in a real-world scenario is used during training).
Feature Engineering
⭐️ Insights gained from an interpretable model can provide a valuable feedback loop for domain experts and engineers.
Regulatory Compliance
⭐️ In many industries, regulations mandate the ability to explaindecisions made by automated systems.
For instance, the General Data Protection Regulation (GDPR) in Europe includes a “right to explanation”
for individuals affected by algorithmic decisions.
Interpretability ensures that organizations can meet these legal and ethical requirements.
⭐️In a production ML environment, retraining is the ‘maintenance engine’ ⚙️ that keeps our models from becoming obsolete.
❌ Don’t ask: When do we retrain?
✅ Ask: “How do we automate the decision to retrain while balancing compute cost 💰, model risk, and data freshness?”
Periodic Retraining (Fixed Interval) ⏳
👉 The model is retrained on a regular schedule (e.g., daily, weekly, or monthly).
Best for:
Stable environments where data changes slowly. (e.g. long-term demand forecast or a credit scoring model).
Pros:
Highly predictable; easy to schedule compute resources; simple to implement via a cron job or Airflow DAG.
Cons:
Inefficient. You might retrain when not needed (wasting money 💵) or fail to retrain during a sudden market shift (losing accuracy).
Trigger-Based Retraining (Reactive) 🔫
👉 Retraining is initiated only when a specific performance or data metriccrosses a pre-defined threshold.
Metric Triggers:
Performance Decay: A drop in Precision, Recall, or RMSE (requires ground-truth labels).
Drift Detection: A high PSI (Population Stability Index) or K-S test score indicating covariate shift.
Pros:
Cost-effective; reacts to the ‘reality’ of the data rather than the calendar.
Cons:
Requires a robust monitoring stack 📺. If the ‘trigger’ logic is buggy, the model may never update.
Continual Learning (Online/Incremental) 🛜
👉 Instead of retraining from scratch on a massive batch, the model is updated incrementally as new data
‘streams’ into the system.
Mechanism: Using ‘Warm Starts’ where the model weights from the previous version are used as the starting point
for the next few gradient descent steps.
Best for:
Recommendation engines (Netflix/TikTok) or High-Frequency Trading 💰where patterns change by the minute.
Pros:
Extreme ‘freshness’; low latency between data arrival and model update.
Cons:
High risk of ‘Catastrophic Forgetting’ (the model forgets old patterns) and high infrastructure complexity.
⭐️In a production ML environment, retraining is only half the battle, we must also safely deploy the new version.
Types of deployment (most common):
Shadow ❏ Deployment
A/B Testing 🧪
Canary 🦜 Deployment
Shadow ❏ Deployment
👉 Safest way to deploy our model or any software update.
Deploy the candidate model in parallel with the existing model.
For each incoming request, route it to both models to make predictions, but only serve the existing model’s prediction to the user.
Log the predictions from the new model for analysis purposes.
Note: When the new model’s predictions are satisfactory, we replace the existing model with the new model.
A/B Testing 🧪
👉A/B testing is a way to compare two variants of a model.
Deploy the candidate model in parallel with the existing model.
A percentage of traffic🚦is routed to the candidate for predictions; the rest is routed to the existing model for predictions.
Monitor 📺 and analyze the predictions, from both models to determine whether the difference in the two models’ performance is statistically significant.
Note: Say we run a two-sample test and get the result that model A is better than model B with the p-value of p = 0.05 or 5%.
Canary 🦜 Deployment
👉 Mitigates deployment risk by incrementally shifting traffic 🚦from a model version to a new version, allowing for real-world validation on a subset of users before a full-scale rollout.
Deploy the candidate model in parallel with the existing model.
A percentage of traffic🚦is routed to the candidate for predictions.
If its performance is satisfactory, increase the traffic to the candidate model.If not, abort the canary and route all the traffic🚦 back to the existing model.
Stop when either the canary serves all the traffic🚦 (the candidate model has replaced the existing model) or when the canary is aborted.
Note: Canary releases can be used to implement A/B testing due to the similarities in their setups. However, we can do canary analysis without A/B testing.
How would you evaluate a model for an imbalanced classification problem? Which metrics would you report and why?
We should evaluate an imbalanced classification model using metrics that that focus on performance for each class, especially the minority class.
Why ? Say, we have a dataset with high imbalance, i.e, 99% of data belongs to positive class and only 1% of data belongs to the negative class. In such a case, standard metrics, such as, accuracy is misleading, because a model can achieve 99% accuracy by simply predicting positive class all the time.
So, what to do ? First, of all, start with the confusion matrix. (focus on minority class) It provides the raw counts of True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN).
This is the foundation for all other metrics.
Confusion Matrix:
Predicted Positive
Predicted Negative
Actual Positive
True Positive (TP)
False Negative (FN)
Actual Negative
False Positive (FP)
True Negative (TN)
Precision: Of all instances the model predicted as positive, how many were actually positive?
\( Precision = \frac{TP}{TP + FP} \)
Use Case: The cost of a False Positive is high (e.g., marking a legitimate email as spam).
Recall (Sensitivity): Of all actual positive instances, how many did the model find?
\( Recall = \frac{TP}{TP + FN} \)
Use Case: The cost of a False Negative is high (e.g., missing a cancer diagnosis or fraud transaction).
Why report F1-Score?: To balance precision and recall. A model with 1.0 precision and 0.0 recall will have an F1-score of 0.
Precision-Recall (PR) AUC: Plots Precision against Recall for different classification thresholds. Better than ROC curve because it uses Precision instead of False Positive Rate (FPR), which can be misleading for imbalanced data.
Why might ROC-AUC be misleading for imbalanced classes?
ROC curve plots TPR vs FPR, \(FPR = \frac{FP}{FP + TN}\), so for an imbalanced data, FPR can be misleading. So for imbalanced data, we better use Precision-Recall curve that uses Precision instead of FPR and hence is more reliable. Let’s look at the fraud detection example below, N = 10,000 transactions, Fraud = 100, NOT fraud = 9900:
The FPR is very low due to the class imbalance, and hence Precision gives us a better view of the model’s performance.
Describe how to avoid data leakage when performing feature engineering and cross-validation.
👉Any information from the validation/test set must NOT influence training, directly or indirectly. So, how do we prevent this leakage of information or data leakage from training to validation or test set ?
Train-Test Contamination:
❌ Wrong: Applying preprocessing (like global StandardScaler, Mean_Imputation, Target_Encoding etc.) on the entire dataset before splitting.
✅ Right: Compute mean, variance, etc. only on the training data and use the same for validation and test data.
Preventing Leakage in Cross-Validation:
❌ Wrong: Perform preprocessing (e.g., scaling, normalization, missing value imputation) on the entire dataset before passing it to cross_val_score.
✅ Right: Use sklearn.pipeline.Pipeline; Pipeline ensures that the ‘validation fold’ remains unseen until the transformation is applied using the training fold’s parameters.
Time Series Data:
❌ Wrong: Use standard random CV; it allows the model to ‘peek into the future’.
✅ Right: Use Time-Series Nested Cross-Validation (Forward Chaining) instead of random shuffling.
Target Leakage:
❌ Wrong: Include features that are only available after the event we are trying to predict and are proxy for the target.
e.g. Including number_of_late_payments in a model to predict whether a person applying for a bank loan will default ?
✅ Right: Do not include such features during training.
Group Leakage:
❌ Wrong: If you have multiple rows that are correlated (same user).
For the same patient or user, you put some rows in Train and others in Test.
✅ Right: Use GroupKFold to ensure all data from a specific group stays together in one fold.
Explain bias-variance tradeoff and write the bias and variance decomposition for squared error.
Bias-Variance Decomposition: For Mean Squared Error (MSE) = \(\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y_i})^2\)
Total Error = Bias^2 + Variance + Irreducible Error
Bias = Systematic Error
Bias measures how far the average prediction of a model is from the true value.
Variance = Sensitivity to Data
Variance measures how much the predictions of a model vary for different training datasets.
Irreducible Error = Sensor noise, Human randomness
Inherent uncertainty in the data generation process itself and cannot be reduced by any model.
Bias-Variance Trade-Off:
High Bias (Underfitting): A model with high bias is too simple to capture the underlying patterns in the data
e.g., fitting a straight line to curved data.
High Variance (Overfitting): A model with high variance is too complex and learns the noise in the training data rather than the true relationship
e.g., a high-degree polynomial curve that perfectly fits training data points but performs poorly on new data.
🎯 The goal is to find a balance; a ‘sweet spot’ that minimizes the total error.
🦉 A good model ‘generalizes’ well, i.e., neither too simple (low bias) nor too complex (low variance).
How does L1 (Lasso) differ from L2 (Ridge) mathematically, and when does Lasso produce sparse solutions?
L1 regularization produces sparse solutions when regularization coefficient \(\lambda_1\) is high.
Because the gradient of L1 penalty (absolute function) is a constant value, i.e, \(\pm 1\), this means a constant reduction in weight at each step, making it gradually reach to 0 in finite steps.
Whereas, the derivative of L2 penalty is proportional to the weight (\(2w_j\)) and as the weight reaches close to 0, the gradient also becomes very small, this means that the weight will become very close to 0, but not exactly equal to 0.
What is heteroscedasticity and how does it affect OLS? How would you test for it?
💡 Heteroscedasticity = Variance NOT Constant
Note: Linear regressionassumes that the data has homoscedasticity (constant variance).
Ordinary Least Squares (OLS) is an unweighted estimator. It treats every data point as equally ‘informative’.
Under Homoscedasticity: Every point has the same amount of noise, so giving them equal weight is logical.
Under Heteroscedasticity: Some points have very low variance (high certainty) and some have very high variance (lots of noise).
👉 By treating all the points equally, OLS is ‘wasting’ the precision of the low-variance points and being ‘skewed’ by the high-variance points. This is why OLS is no longer efficient; does not produce the smallest possible standard errors. Which means:
t-tests become unreliable.
p-values become misleading.
Confidence intervals are wrong.
👉 OLS is NO longer B.L.U.E. (Best Linear Unbiased Estimator).
While the coefficients remain unbiased, they are no longer the ‘best’ because there is another estimator (like Weighted Least Squares) that could provide a lower variance.
👉 How to Test for Heteroscedasticity ?
Visual (Residual Plot):
Heteroscedasticity: The points form a ‘fan’ or ‘funnel’ shape, widening or narrowing as values increase.
Homoscedasticity: The points look like a random ‘cloud’ with consistent thickness.
Breusch–Pagan Test
White Test
Goldfeld–Quandt Test
Explain the difference between likelihood and probability; explain how MAP differs from MLE with example.
Probability vs. Likelihood: Difference lies in which variable is fixed and which is varying.
Probability(Forward View):
Quantifies the chance of observing a specific outcome given a known, fixed parameters \(\theta\).
Likelihood(Backward/Inverse View):
Inverse concept used for inference (working backward from results to causes).
It is a function of the parameters \(\theta\) and measures how ‘likely’ a specific set of parameters makes the observed (fixed) data appear.
MLE vs. MAP: Both help us answer the question: Which parameter \(\theta\) best explains the data we just saw?
Maximum Likelihood Estimation (MLE):
MLE believes the data should speak for itself.
It asks: ‘Which value of \(\theta\) makes the observed data most probable?’
It ignores any outside context or common sense.
Maximum A Posteriori (MAP):
MAP believes the data is important, but so is prior knowledge.
It asks: ‘Given the data AND what we already know about the problem at hand, which value of \(\theta\) is most likely?’
The relationship between them is rooted in Bayes’ Theorem:
Note: The goal of a decision tree algorithm is to find the split that maximizes information gain, meaning it removes the most uncertainty from the data.
👉 To understand how a Decision Tree selects the ‘best’ root node, let’s use the example below:
Because the world around us is very uncertain, and Probability acts as - the fundamental language
to understand, express and deal with this uncertainty.
Toss a fair coin, \(P(H) = P(T) = 1/2\)
Roll a die, \(P(1) = P(2) = P(3) = P(4) = P(5) = P(6) = 1/6\)
Set of all possible outcomes of an experiment. Symbol: \(\Omega\) \(P(\Omega) = 1\)
Example
Toss a fair coin, sample space: \(\Omega = \{H,T\}\)
Roll a die, sample space: \(\Omega = \{1,2,3,4,5,6\}\)
Choose a real number \(x\) from the interval \([2,3]\), sample space: \(\Omega = [2,3]\); sample size = \(\infin\) Note: There can be infinitely many points between 2 and 3, e.g: 2.21, 2.211, 2.2111, 2.21111, …
Randomly put a point in a rectangular region; sample size = \(\infin\) Note: There can be infinitely many points in any rectangular region.
Event
An outcome of an experiment. A subset of all possible outcomes. A,B,…⊆Ω
Example
Toss a fair coin, set of possible outcomes: \(\{H,T\}\)
Roll a die, set of possible outcomes: \(\{1,2,3,4,5,6\}\)
Roll a die, event \(A = \{1,2\} => P(A) = 2/6 = 1/3\)
Email classifier, set of possible outcomes: \(\{spam,not ~spam\}\).
Discrete
Number of potential outcomes from an experiment is countable, distinct, or can be listed in a sequence,
even if infinite i.e countably infinite.
Example
Toss a fair coin, possible outcomes: \(\Omega = \{H,T\}\)
Roll a die, possible outcomes: \(\Omega = \{1,2,3,4,5,6\}\)
Choose a real number \(x\) from the interval \([2,3]\) with decimal precision, sample space: \(\Omega = [2,3]\). Note: There are 99 real numbers between 2 and 3 with 2 decimal precision i.e from 2.01 to 2.99.
Number of cars passing a specific traffic signal in 1 hour.
Continuous
Potential outcomes from an experiment can take any value within a given range or interval,
representing an uncountably infinite set of possibilities.
Example
A line segment between 2 and 3 - forms a continuum.
Randomly put a point in a rectangular region.
graph TD
A[Sample Space] --> |Discrete| B(Finite)
A --> C(Infinite)
C --> |Discrete| D(Countable)
C --> |Continuous| E(Uncountable)
Two or more events that cannot happen at the same time. No overlapping or common outcomes. If one event occurs, then the other event does NOT occur.
Example
Roll a die, sample space: \(\Omega = \{1,2,3,4,5,6\}\) Odd outcome = \(A = \{1,3,5\}\) Even outcome = \(B = \{2,4,6\}\) are mutually exclusive.
\(P(A \cap B) = 0\) Since, \(P(A \cup B) = P(A) + P(B) - (P(A \cap B)\) Therefore, \(P(A \cup B) = P(A) + P(B)\)
Note: If we know that event \(A\) has occurred, then we can say for sure that the event \(B\) did NOT occur.
Independent Events
Two events are independent if the occurrence of one event does NOT impact
the outcome of the other event.
Example
Roll a die twice , sample space: \(\Omega = \{1,2,3,4,5,6\}\) Odd number in 1st throw = \(A = \{1,3,5\}\) Odd number in 2nd throw = \(B = \{1,3,5\}\) Note: A and B are independent because whether we get an odd number in 1st roll has NO impact of getting
an odd number in second roll.
\(P(A \cap B) = P(A)*P(B)\)
Note: If we know that event \(A\) has occurred, then that gives us NO new information about the event \(B\).
Does \(P=0\) mean that the event is impossible or improbable ?
No, it means that the event is highly unlikely to occur.
Let’s understand this answer with an example.
What is the probability of choosing a real number, say 2.5, from the interval \([2,3]\) ?
Probability of choosing exactly one point on the number line or a real number, say 2.5, from the interval \([2,3]\) is almost = 0, because there are infinitely many points between 2 and 3.
Also, we can NOT say that choosing exactly 2.5 is impossible, because it exists there on the number line. But, for all practical purposes, \(P(2.5) = 0\).
Therefore, we say that \(P=0\) means “Highly Unlikely” and NOT “Impossible”.
Extending this line of reasoning, we can say that probability of NOT choosing 2.5, \(P(!2.5) = 1\). Theoretically yes, because there are infinitely many points between 2 and 3. But, we cannot say for sure that we cannot choose 2.5 exactly. There is some probability of choosing 2.5, but it is very small.
Therefore, we say that \(P=1\) means “Almost Sure” and NOT “Certain”.
Note
Now, lets also see another example where \(P=0\) means Impossible and \(P=1\) means Certain.
What is the probability of getting a 7 when we roll a 6 faced die ?
Here, in this case we can say that \(P(7)=0\) and that means Impossible.
Similarly, we can say that \(P(get ~any ~number ~between ~1 ~and ~6)=1\) and \(P=1 => \) Certain.
It is the probability of an event occurring, given that another event has already occurred. Allows us to update probability when additional information is revealed.
\[P(A \mid B) = \frac{P(A \cap B)}{P(B)}\]
Chain Rule
\(P(A \cap B) = P(B)*P(A \mid B)\) or \(P(A \cap B) = P(A)*P(B \mid A)\)
Example
Roll a die, sample space: \(\Omega = \{1,2,3,4,5,6\}\) Event A = Get a 5 = \(\{5\} => P(A) = 1/6\) Event B = Get an odd number = \(\{1, 3, 5\} => P(B) = 3/6 = 1/2\)
\[
\begin{aligned}
\because (A \cap B) = \{5\} & \implies P(A \cap B) = 1/6 \\
P(A \mid B) &= \frac{P(A \cap B)}{P(B)} \\
&= \frac{1/6}{1/2} \\
\implies P(A \mid B)&= 1/3
\end{aligned}
\]
It is a formula that uses conditional probability. It allows us to update our belief about an event’s probability based on new evidence. We know from conditional probability and chain rule that:
$$
\begin{aligned}
P(A \cap B) = P(B)*P(A \mid B) \\
P(A \cap B) = P(A)*P(B \mid A) \\
P(A \mid B) = \frac{P(A \cap B)}{P(B)}
\end{aligned}
$$
Combining all the above equations gives us the Bayes’ Theorem:
Roll a die, sample space: \(\Omega = \{1,2,3,4,5,6\}\) Event A = Get a 5 = \(\{5\} => P(A) = 1/6\) Event B = Get an odd number = \(\{1, 3, 5\} => P(B) = 3/6 = 1/2\) Task: Find the probability of getting a 5 given that you rolled an odd number.
\(P(B \mid A) = 1\) = Probability of getting an odd number given that we have rolled a 5.
Now, let’s understand another concept called Law of Total Probability. Here, we can say that the sample space \(\Omega\) is divided into 2 parts - \(A\) and \(A ^ \complement \)
So, the probability of an event \(B\) is given by:
\[
B = B \cap A + B \cap A ^ \complement \\
P(B) = P(B \cap A) + P(B \cap A ^ \complement ) \\
By ~Chain ~Rule: P(B) = P(A)*P(B \mid A) + P(A ^ \complement )*P(B \mid A ^ \complement )
\]
What if the sample space is divided into ’n’ such partitions ?
Law of Total Probability
Overall probability of an event B, considering all the different, mutually exclusive ways it can occur. If A₁, A₂, …, Aₙ are a set of events that partition the sample space, such that they are -
Mututally exclusive : \(A_i \cap A_j = \emptyset\) for all \(i, j\)
Exhaustive: \(A₁ \cup A₂ ... \cup Aₙ = \Omega\) for all \(i \neq j\)
\[
P(B) = \sum_{i=1}^{n} P(A_i)*P(B \mid A_i)
\]
where \(n\) is the number of mutually exclusive partitions of the sample space \(\Omega\) .
Now, we can also generalize the Bayes’ Theorem using the Law of Total Probability.
Two events are independent if the occurrence of one event does not affect the probability of the other event. There are 3 types of independence of events:
Mutual Independence
Pair-Wise Independence
Conditional Independence
Mutual Independence
Joint probability of two events is equal to the product of the individual probabilities of the two events. \(P(A \cap B) = P(A)*P(B)\)
Joint probability: The probability of two or more events occurring simultaneously. \(P(A \cap B)\) or \(P(A, B)\)
Example
Toss a coin and roll a die - \(A\) = Get a heads; \(P(A)=1/2\) \(B\) = Get an odd number; \(P(B)=1/2\)
Every pair of events in the set is independent. Pair-wise independence != Mutual independence.
Example
Toss 3 coins; For 2 tosses, sample space: \(\Omega = \{HH,HT, TH, TT\}\) \(A\) = First and Second toss outcomes are same i.e \(\{HH, TT\}\); \(P(A)= 2/4 = 1/2\) \(B\) = Second and Third toss outcomes are same i.e \(\{HH, TT\}\); \(P(B)= 2/4 = 1/2\) \(C\) = Third and First toss outcomes are same i.e \(\{HH, TT\}\); \(P(C)= 2/4 = 1/2\)
Now, pair-wise independence of the above events A & B is - \(P(A \cap B)\) \(P(A \cap B)\) => Outcomes of first and second toss are same & outcomes of second and third toss are same. => Outcomes of all the three tosses are same.
Total number of outcomes = 8 Desired outcomes = \(\{HHH, TTT\}\) = 2 => \(P(A \cap B) = 2/8 = 1/4 = P(A) * P(B) = 1/2 * 1/2 = 1/4\)
Therefore, \(A\) and \(B\) are pair-wise independent. Similarly, we can also prove that \(A\) and \(C\) and \(B\) and \(C\) are also pair-wise independent.
Now, let’s check for mutual independence of the above events A, B & C. \(P(A \cap B \cap C) = P(A)*P(B)*P(C)\) \(P(A \cap B \cap C)\) = Outcomes of all the three tosses are same i.e \(\{HHH, TTT\}\) Total number of outcomes = 8 Desired outcomes = \(\{HHH, TTT\}\) = 2 So, \(P(A \cap B \cap C)\) = 2/8 = 1/4 But, \(P(A)*P(B)*P(C) = 1/2*1/2*1/2 = 1/8\) Therefore \(P(A \cap B \cap C)\) ≠ \(P(A)*P(B)*P(C)\) => \(A, B, C\) are NOT mutually independent but only pair wise independent.
Conditional Independence
Two events A & B are conditionally independent given a third event C, if they are independent given that C has occurred. Occurrence of C changes the context, causing the events A & B to become independent of each other.
A random variable is a function that maps the outcomes of a sample space to a real number. Random Variable X is represented as, \(X: \Omega \to \mathbb{R} \) 👉 It maps abstract outcomes of a random experiment to concrete numerical values required for mathematical analysis.
Example
Toss a coin 2 times, sample space: \(\Omega = \{HH,HT, TH, TT\}\) The above random experiment of coin tosses can be mapped to a random variable \(X: \Omega \to \mathbb{R} \) \(X: \Omega = \{HH,HT, TH, TT\} \to \mathbb{R}) \) Say, if we count the number of heads, then \[
\begin{aligned}
X(0) = \{TT\} = 1 \\
X(1) = \{HT, TH\} = 2 \\
X(2) = \{HH\} = 1 \\
\end{aligned}
\]
Similar, output will be observed for number of tails.
Depending upon the nature of output, random variables are of 2 types - Discrete and Continuous.
Discrete Random Variable
A random variable whose possible outcomes are finite or countably infinite. Typically obtained by counting. Discrete random variable cannot take any value between 2 consecutive values.
Example
👉 The number of heads in 2 coin tosses can be 0, 1 or 2 but NOT 1.5.
Continuous Random Variable
A random variable that can take any value between a given range/interval. Possible outcomes are infinite.
Example
A person’s height in a given range of say 150cm-200cm. Height can take any value, not just round values, e.g: 150.1cm, 167.95cm, 180.123cm etc.
Now, that we have understood that how random variable can be used to map outcomes of abstract random experiment to real
values for mathematical analysis, we will understand its applications.
How to calculate the probability of a random variable?
Probability of a random variable is given by something called - Cumulative Distribution Function (CDF).
Cumulative Distribution Function(CDF)
It gives the cumulative probability of a random variable \(X\). CDF = \(F(X) = P(X \leq x)\) i.e Probability a random variable \(X\) will take for a value \(<=x\).
Non-Decreasing: For any 2 values \(x_1\) and \(x_2\) such that \(x_1 \leq x_2\), corresponding CDF must satisfy - \(F(x_1) \leq F(x_2)\) Note: Cumulative function can never decrease as x increases.
Bounded: Range of CDF is always between 0 and 1, because CDF represents total probability,
which cannot be negative or greater than 1.
\(\lim_{x \to -\infty} F(X) = 0\); as \(x \to -\infty\), event \((X \le x)\) becomes an impossible event i.e \(P(X \le x) =0\) \(\lim_{x \to \infty} F(X) = 1\); as \(x \to \infty\), event \((X \le x)\) includes all possible outcomes of the event,
making sure that \(P(X \le x) =1\)
Right Continuous: Function’s value at a point is same as the limit of the function, as we approach that point from right hand side (RHS). Note: Reason for only right continuity is because how the cumulative distribution function is defined, as we may have a jump
on the left side of the point.
\(\lim_{h \to o^+} F(X+h) = F(X)\)
For example: In the above coin toss CDF example, if we approach X=1 from right, say 1.001, 1.01 etc,
the value of \(F(X) = P(X \leq x) = F(1) = 3/4\). But, if we approach \(X=1\) from left, say 0.99, 0.999 etc, the value of \(F(X) = 1/4\),
as these values do NOT yet include the value of the probability at \(X=1\).
Discrete Case
For a discrete random variable, the CDF is a step function (i.e with jumps). Value of the probability of a random variable X, at any given value x, is calculated by summing up all the probabilities
for values \(\le x\).
\( CDF = F_X(x) = \sum_{x_i \le x} P(X=x_i) \), where \(P(X=x_i)\) is the Probability Mass Function (PMF) at \(x_i\)
In the above coin toss example - Height of the jump at ‘x’ = Probability at that value ‘x’. e.g: Jump at (x=1) = 1/2 = Probability at (x=1).
Continuous Case
For a continuous random variable, the CDF is a continuous function. CDF for continuous random variable is calculated by integrating the probability density function (PDF)
from \(-\infty\) to the given value \(x\).
\( CDF = F_X(x) = \int_{-\infty}^{x} f(x) \,dx \), where \(f(x)\) is the Probability Density Function (PDF) of random variable.
Note: We can also say that PDF is the derivative of CDF for continuous random variable.
It gives the exact value of a probability for a discrete random variable at a specific value \(x\). It assigns a “non-zero” mass or probability to a specific countable outcome. Note: Called ‘mass’ because probability is concentrated at a single discrete point. \(PMF = P(X=x)\) e.g: Bernoulli, Binomial, Multinomial, Poisson etc.
Commonly visualised as a bar chart. Note: PMF = Jump at a given point in CDF.
It models a single event with two possible outcomes, success (1) or failure (0), with a fixed probability of success,
‘p’. p = Probability of success 1-p = Probability of failure Mean = p Variance = p(1-p) Note: A single trial that adheres to these conditions is called a Bernoulli trial. \(PMF, P(x) = p^x(1-p)^{1-x}\), where \(x \in \{0,1\}\)
Example
Toss a coin, we get heads or tails.
Result of a test, pass or fail.
Machine learning, binary classification model.
Binomial Distribution
It extends the Bernoulli distribution by modeling the number of successes that occur over a fixed number of
independent trials. n = Number of trials k = Number of successes p = Probability of success Mean = np Variance = np(1-p)
\(PMF, P(x=k) = \binom{n}{k}p^k(1-p)^{n-k}\), where \(k \in \{0,1,2,3,...,n\}\) \(\binom{n}{k} = \frac{n!}{k!(n-k)!}\) i.e number of ways to achieve ‘k’ successes in ‘n’ independent trials.
Note: Bernoulli is a special case of Binomial distribution where n = 1. Also read about Multinomial distribution i.e where number of possible outcomes is > 2.
Example
Counting number of heads(success) in ’n’ coin tosses.
Assumptions
Trials are independent.
Probability of success remains constant for every trial.
What is the probability of getting exactly 2 heads in 3 coin tosses?
Total number of outcomes in 3 coin tosses = 2^3 = 8 Desired outcomes i.e 2 heads in 3 coin tosses = \(\{HHT, HTH, THH\}\) = 3 Probability of getting exactly 2 heads in 3 coin tosses = \(\frac{3}{8}\) = 0.375 Now lets solve the question using the binomial distribution formula.
It expresses the probability of an event happening a certain number of times ‘k’ within a fixed interval of time. Given that:
Events occur with a known constant average rate.
Occurrence of an event is independent of the time since the last event.
Parameters: \(\lambda\): Expected number of events per interval \(k\) = Number of events in the same interval Mean = \(\lambda\) Variance = \(\lambda\)
PMF = Probability of occurrence of ‘k’ events in the same interval
\[PMF = \lambda^ke^{-\lambda}/k!\]
Note: Useful to count data where total population size is large but the probability of an individual event is small.
Example
Model the number of customers arrival at a service center per hour.
Number of website clicks in a given time period.
PMF of Poisson Distribution
A company receives, on an average, 5 customer emails per hour. What is the probability of receiving exactly 3 emails
in the next hour?
Expected (average) number of emails per hour, \(\lambda\) = 5 Probability of receiving exactly k=3 emails in the next hour =
This is a function used for continuous random variables to describe the likelihood of the variable taking on a value
within a specific range or interval. Since, at any given point the probability of a continuous random variable is zero,
we find the probability within a given range. Note: Called ‘density’ because probability is spread continuously over a range of values
rather than being concentrated at a single point as in PMF. e.g: Uniform, Gaussian, Exponential, etc.
Note: PDF is a continuous function \(f(x)\). It is also the derivative of Cumulative Distribution Function (CDF) \(F_X(x)\)
\(PDF = f(x) = F'(X) = \frac{dF_X(x)}{dx} \)
Key properties of PDF
Non-Negative: Function must be non-negative everywhere i.e \(f(x) \ge 0 \forall x\).
Sum = 1: Total area under curve must be equal to 1. \( \int_{-\infty}^{\infty} f(x) \,dx = 1\)
Probability of a continuous random variable in the range [a,b] is given by - \( P(a \le x \le b) = \int_{a}^{b} f(x) \,dx\)
We use a general term Probability Distribution Function for both PMF(discrete) and PDF(continuous)
because both describe how the probability is distributed across a random variable’s entire domain.
Example
Consider a line segment/interval from \(\Omega = [0,2] \) Random variable \(X(\omega) = \omega\) i.e \(X(1) = 1 ~and~ X(1.1) = 1.1 \)
Note: If we know the PDF of a continuous random variable, then we can find the probability of any given region/interval
by calculating the area under the curve.
All the outcomes within the given range are equally likely to occur. Also known as ‘fair’ distribution. Note: This is a natural starting point to understand randomness in general.
\[ X \sim U(a,b) \]$$
\begin{aligned}
PDF = f(x) =
\begin{cases}
\frac{1}{b-a} & \text{if } x \in [a,b] \\
0 & \text{~otherwise }
\end{cases}
\end{aligned}
$$
Mean = Median = \( \frac{a+b}{2} ~if~ x \in [a,b] \) Variance = \( \frac{(b-a)^2}{12} \)
Standard uniform distribution: \( X \sim U(0,1) \)
It is a continuous probability distribution characterized by a symmetrical, bell-shaped curve with
most data clustered around the central average, with frequency of values decreasing as they move away from the center.
Most outcomes are average; extremely low or extremely high values are rare.
Characterised by mean and standard deviation/variance.
Peak at mean = median, symmetric around mean. Note: Most important and widely used distribution.
\[ X \sim N(\mu, \sigma^2) \]
$$
\begin{aligned}
PDF = f(x) =
\dfrac{1}{\sqrt{2\pi}\sigma}e^{-\dfrac{(x-\mu)^2}{2\sigma^2}} \\
\end{aligned}
$$ Mean = \(\mu\) Variance = \(\sigma^2\)
Standard normal distribution:
\[ Z \sim N(0,1) ~i.e~ \mu = 0, \sigma^2 = 1 \]
Any normal distribution can be standardized using Z-score transformation:
$$
\begin{aligned}
Z = \dfrac{X-\mu}{\sigma}
\end{aligned}
$$
Example
Human height, IQ scores, blood-pressure etc.
Measurement of errors in scientific experiments.
PDF of Gaussian Distribution
CDF of Gaussian Distribution
68-95-99 Rule
68.27% of the data lie within 1 standard deviation of the mean i.e \(\mu \pm \sigma\)
95.45% of the data lie within 2 standard deviations of the mean i.e \(\mu \pm 2\sigma\)
99.73% of the data lie within 3 standard deviations of the mean i.e \(\mu \pm 3\sigma\)
It is used to model the amount of time until a specific event occurs. Given that:
Events occur with a known constant average rate.
Occurrence of an event is independent of the time since the last event.
Parameters: Rate parameter: \(\lambda\): Average number of events per unit time Scale parameter: \(\mu ~or~ \beta \): Mean time between events Mean = \(\frac{1}{\lambda}\) Variance = \(\frac{1}{\lambda^2}\) \[ \lambda = \dfrac{1}{\beta} = \dfrac{1}{\mu}\]
At a bank, a teller spends 4 minutes, on an average, with every customer. What is the probability that a randomly
selected customer will be served in less than 3 minutes?
Mean time to serve 1 customer = \(\mu\) = 4 minutes So, \(\lambda\) = average number of customers served per unit time = \(1/\mu\) = 1/4 = 0.25 minutes Probability to serve a customer in less than 3 minutes can be found using CDF -
So, probability of a customer being served in less than 3 minutes is 53%(approx).
At a bank, a teller spends 4 minutes, on an average, with every customer. What is the probability that a randomly
selected customer will be served in greater than 2 minutes?
Probability of waiting for an additional period of time for an event to occur is independent of
how long you have already waited. e.g: Lifetime of electronic items follow exponential distribution.
Probability of a computer part failing in the next 1 hour is the same regardless of whether
it has been working for 1 day or 1 year or 5 years.
Note: Memoryless property makes exponential distribution particularly useful for -
Modeling systems that do not experience ‘wear and tear’; where failure is due to a constant random rate
rather than degradation over time.
Also, useful for ‘reliability analysis’ of electronic systems where a ‘random failure’ model is more appropriate than
a ‘wear out’ model.
Suppose, we know that an electronic item has lasted for time \(x>t\) days, then what is the probability that it will last
for an additional time of ’s’ days ?
Task: We want to find the probability of the electronic item lasting for \(x > t+s \) days, given that it has already lasted for \(x>t\) days. This is a ‘conditional probability’. Since,
\[ P(A \mid B) = \dfrac{P(A \cap B)}{P(B)} \]
We want to find: \( P(X > t+s \mid X > t) = ~? \)
\[
P(X > t+s \mid X > t) = \dfrac{P(X > t+s ~and~ X > t)}{P(X > t)} \\
\text{Since, t+s > t, we can only consider t+s} \\
= \dfrac{P(X > t+s)}{P(X > t)} \\
= \dfrac{e^{-\lambda(t+s)}}{e^{-\lambda(t)}} \\
= e^{-\lambda(t) -\lambda(s) + \lambda(t)} \\
= e^{-\lambda(s)} \\
=> \text{Independent of time 't'}
\]
Hence, probability that the electronic item will survive for an additional time ’s’ days is independent of the time ’t’ days it has already survived.
Relation of Exponential Distribution and Poisson Distribution
Poisson distribution models the number of events occurring in a fixed interval of time,
given a constant average rate \(\lambda \). Exponential distribution models the time interval between those successive events.
2 faces of the same coin.
\(\lambda_{poisson}\) is identical to rate parameter \(\lambda_{exponential}\).
Note: If the number of events in a given interval follow a Poisson distribution, then the waiting time between
those events will necessarily follow an Exponential distribution.
Lets see the proof for the above statement.
Poisson Case: The probability of observing exactly ‘k’ events in a time interval of length ’t’ with an average rate of \( \lambda \) events per unit time is given by -
The event that waiting time until next event > t, is same as observing ‘0’ events in that interval. => We can use the PMF of Poisson distribution with k=0.
Exponential Case: Now, lets consider exponential distribution that models the waiting time ‘T’ until next event. The event that waiting time ‘T’ > t, is same as observing ‘0’ events in that interval.
\[ CDF = P(X>t) = e^{-\lambda t} \]
Observation: Exponential distribution is a direct consequence of Poisson distribution probability of ‘0’ events.
Consider a machine that fails, on an average, every 20 hours. What is the probability of having NO failures in
the next 10 hours?
Using Poisson: Average failure rate, \(\lambda\) = 1/20 = 0.05 Time interval, t = 10 hours Number of events, k = 0 Average number of events in interval, (\(\lambda t\)) = (1/20) * 10 = 0.5 Probability of having NO failures in the next 10 hours = ?
Using Exponential: What is the probability that wait time until next failure > 10 hours? Waiting time, T > t = 10 hours. Average number of failures per hour, \(\lambda\) = 1/20 per hour
Let’s play a game where we flip a fair coin. If we get a head, then you win Rs. 100, and if its a tail, then you lose Rs. 50. What is the expected value of the amount that you will win per toss?
Possible outcomes are: \(x_1 = 100 ,~ x_2 = -50 \) Probability of each outcome is \(P(X = 100) = 0.5,~ P(X = -50) = 0.5 \)
Therefore, the expected value of the amount that you will win per toss is Rs. 25 in the long run.
What is the expected value of a continuous uniform random variable distributed over the interval [a,b]?
$$
\text{PDF of continuous uniform random variable } = \\
f_X(x) =
\begin{cases}
\dfrac{1}{b-a}, & x \in [a,b] \\
0, & \text{otherwise.}
\end{cases}
$$\[
\text{Expected value of continuous uniform random variable } = \\
E[X] = \int_{-\infty}^{\infty} x.f(x) dx \\
= \int_{-\infty}^{a} x.f(x) dx + \int_{a}^{b} x.f(x) dx + \int_{b}^{\infty} x.f(x) dx\\[0.5em]
\text{Since, the PDF is defined only in the range [a,b] } \\[0.5em]
= 0 + \int_{a}^{b} x.f(x) dx + 0 \\
= \int_{a}^{b} x.f(x) dx \\
= \dfrac{1}{b-a} \int_{a}^{b} x dx \\[0.5em]
= \dfrac{1}{b-a} (\frac{x^2}{2})_{a}^{b} \\[0.5em]
= \dfrac{1}{b-a} * (\frac{b^2 - a^2}{2}) \\[0.5em]
= \dfrac{1}{b-a} * \{\frac{(b+a)(b-a)}{2}\}\\
= \dfrac{b+a}{2}
\]
Variance
It is the average of the squared differences from the mean.
Measures the spread or variability in the data distribution.
If the variance is low, then the data is clustered around the mean i.e less variability; and if the variance is high, then the data is widely spread out i.e high variability.
Variance in terms of expected value, where \(E[X] = \mu\), is given by:
It is the measure of how 2 variables X & Y vary together. It gives the direction of the relationship between the variables.
\[
\begin{aligned}
\text{Cov}(X, Y) &> 0 &&\Rightarrow \text{ } X \text{ and } Y \text{ increase or decrease together} \\[0.5em]
\text{Cov}(X, Y) &= 0 &&\Rightarrow \text{ } \text{No linear relationship} \\[0.5em]
\text{Cov}(X, Y) &< 0 &&\Rightarrow \text{ } \text{If } X \text{ increases, } Y \text{ decreases (and vice versa)}
\end{aligned}
\]
Note: For both direction as well as magnitude, we use Correlation. Let’s use expectation to compute the co-variance of two random variables X & Y:
\[
\begin{aligned}
Cov(X,Y) &= E[(X-E[X])(Y-E[Y])] \\
&\text{where, E[X] = mean of X and E[Y] = mean of Y} \\
& = E[XY - YE[X] -XE[Y] + E[X]E[Y] \\
&= E[XY] - E[Y]E[X] - \cancel{E[X]E[Y]} + \cancel{E[X]E[Y]} \\
Cov(X,Y) &= E[XY] - E[X]E[Y] \\
\end{aligned}
\]
Note:
In a multivariate setting, relationship between all the pairs of random variables are summarized in
a square symmetrix matrix called ‘Co-Variance Matrix’ \(\Sigma\).
Covariance of a random variable with self gives the variance, hence the diagonals of covariance matrix are variances.
They are statistical measures that describe the characteristics of a probability distribution,
such as its central tendency, spread/variability, and asymmetry. Note: We will discuss ‘raw’ and ‘central’ moments.
It is a function that simplifies computation of moments, such as, the mean, variance, skewness, and kurtosis,
by providing a compact way to derive any moment of a random variable through differentiation.
Provides an alternative to PDFs and CDFs of random variables.
A powerful property of the MGF is that its \(n^{th}\) derivative, when evaluated at \((t=0)\) =
the \(n^{th}\) moment of the random variable.
\[
\text{MGF of random variable X is the expected value of } e^{tX} \\
MGF = M_X(t) = E[e^{tX}]
\]
Not all probability distributions have MGFs; sometimes, integrals may not converge and moment may not exist.
Important: Differentiating \(M_X(t)\) with respect to \(t\), \(i\) times, and setting \((t =0)\) gives us
the \(i^{th}\) moment of the random variable.
It describes the probability of 2 or more random variables occurring simultaneously.
The random variables can be from different distributions, such as, discrete and continuous.
Joint CDF:
\[
F_{X,Y}(a,b) = P(X \le a, Y \le b),~ -\infty < a, b < \infty
\]
Discrete Case:
\[
F_{X,Y}(a,b) = P(X \le a, Y \le b) = \sum_{x_i \le a} \sum_{y_j \le b} P(X = x_i, Y = y_j)
\]
Continuous Case:
\[
F_{X,Y}(a,b) = P(X \le a, Y \le b) = \int_{-\infty}^{a} \int_{-\infty}^{b} f_{X,Y}(x,y) dy dx
\]
Joint PMF:
\[
P_{X,Y}(x,y) = P(X = x, Y = y)
\]
Key Properties:
\(P(X = x, Y = y) \ge 0 ~ \forall (x,y) \)
\( \sum_{i} \sum_{j} P(X = x_i, Y = y_j) = 1 \)
Joint PDF:
\[
f_{X,Y}(x,y) = \frac{\partial^2 F_{X,Y}(x,y)}{\partial x \partial y} \\
f_{X,Y}(x,y) = \iint_{A \in \mathbb{R}^2} f_{X,Y}(x,y) dy dx
\]
Key Properties:
\(f_{X,Y}(x,y) \ge 0 ~ \forall (x,y) \)
\( \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f_{X,Y}(x,y) dy dx = 1 \)
Example
If we consider 2 random variables, say, height(X) and weight(Y), then the joint distribution will tell us
the probability of finding a person having a particular height and weight.
There are 2 bags; bag_1 has 2 red balls & 3 blue balls, bag_2 has 3 red balls & 2 blue balls. A ball is picked at random from each bag, such that both draws are independent of each other. Let’s use this example to understand joint probability.
Let A & B be discrete random variables associated with the outcome of the ball drawn from first and second bags
respectively.
A = Red
A = Blue
B = Red
2/5*3/5 = 6/25
3/5*3/5 = 9/25
B = Blue
2/5*2/5 = 4/25
3/5*2/5 = 6/25
Since, the draws are independent, joint probability = P(A) * P(B) Each of the 4 cells in above table shows the probability of combination of results from 2 draws or joint probability.
It describes the probability distribution of an individual random variable in a joint distribution,
without considering the outcomes of other random variables.
If we have the joint distribution, then we can get the marginal distribution of each random variable from it.
Marginal probability equals summing the joint probability across other random variables.
Marginal CDF: We know that Joint CDF =
\[
F_{X,Y}(a,b) = P(X \le a, Y \le b),~ -\infty < a, b < \infty
\]
Marginal CDF =
\[
F_X(a, \infty) = P(X \le a, Y < \infty) = P(X \le a)
\]
Discrete Case:
\[
F_X(a) = P(X \le a, Y \le \infty) = \sum_{x_i \le a} \sum_{y_j \in \mathbb{R}} P(X = x_i, Y = y_j)
\]
Continuous Case:
\[
F_X(a) = P(X \le a, Y \le \infty) = \int_{-\infty}^{a} \int_{-\infty}^{\infty} f_{X,Y}(x,y)dydx = \int_{-\infty}^{\infty} f_{X,Y}(x,y)dy
\]
Law of Total Probability We know that Joint Probability Distribution =
\[
P_{X,Y}(x,y) = P(X = x, Y = y)
\]
The events \((Y=y)\) partition the sample space, such that:
Let’s re-visit the ball drawing example. There are 2 bags; bag_1 has 2 red balls & 3 blue balls, bag_2 has 3 red balls & 2 blue balls. A ball is picked at random from each bag, such that both draws are independent of each other. Let’s use this example to understand marginal probability.
Let A & B be discrete random variables associated with the outcome of the ball drawn from first and second bags
respectively.
A = Red
A = Blue
P(B) (Marginal)
B = Red
2/5*3/5 = 6/25
3/5*3/5 = 9/25
6/25 + 9/25 = 15/25 = 3/5
B = Blue
2/5*2/5 = 4/25
3/5*2/5 = 6/25
4/25 + 6/25 = 10/25 = 2/5
P(A) (Marginal)
6/25 + 4/25 = 10/25 = 2/5
9/25 + 6/25 = 15/25 = 3/5
We can see from the table above - P(A=Red) is the sum of joint distribution over all possible values of B i.e Red & Blue.
Generative machine learning models, such as, GANs, learn the conditional distribution of pixels, given the style of
input image.
Let’s re-visit the ball drawing example. Note: We only have information about the joint and marginal probabilities. What is the conditional probability of drawing a red ball in the first draw, given that a blue ball is drawn in second draw?
Let A & B be discrete random variables associated with the outcome of the ball drawn from first and second bags
respectively. A = Red ball in first draw B = Blue ball in second draw.
There are 2 parts in I.I.D, “Independent” and “Identically Distributed”. Let’s revisit and understand the independence of random variables first.
Independence of Random Variables
It means that the knowing the outcome of one random variable does not impact the probability of the other random variable. Two random variables X & Y are independent if:
Random variable X is said to be identically distributed if each sample comes from the same probability distribution,
such as, Gaussian, Bernoulli, Uniform, etc with the same properties i.e mean, variance, etc are same. Similarly, random variables X & Y are said to be identically distributed if they belong to the same probability distribution.
Independent & Identically Distributed(I.I.D)
I.I.D assumption for samples(data points) in a dataset means that the samples are:
Independent, i.e, each sample is independent of the other.
Identically distributed, i.e, each sample is drawn from the same probability distribution.
Example
We take the heights of a random sample of people to estimate the average height of the population of a city.
Here ‘independent’ assumption means that the height of each person in the sample is independent of the other person. Usually, heights of members of the same family may be highly correlated. However, for practical purposes, we can assume that all the heights are independent of one another.
And, for ‘identically distributed’ - we can assume that all the heights are from the same Gaussian distribution with some mean and variance.
A sequence of random variables \(X_1, X_1, \dots, X_n\) is said to converge in probability
to a known random variable \(X\), if for every number \(\epsilon >0 \), the following is true:
where, \(X_n\): is the estimator or sample based random variable. \(X\): is the known or limiting or target random variable. \(\epsilon\): is the tolerance level or margin of error.
Toss a fair coin: Estimator: \[
X_n = \begin{cases}
\frac{n}{n+1} & \text{, if Head } \\
\\
\frac{1}{n} & \text{, if Tail} \\
\end{cases}
\] Known random variable (Bernoulli): \[
X = \begin{cases}
1 & \text{, if Head } \\
\\
0 & \text{, if Tail} \\
\end{cases}
\]
\[
X_n - X = \begin{cases}
\frac{n}{n+1} - 1 = \frac{-1}{n+1} & \text{, if Head } \\
\\
\frac{1}{n} - 0 = \frac{1}{n} & \text{, if Tail} \\
\end{cases}
\]\[
|X_n - X| = \begin{cases}
\frac{1}{n+1} & \text{, if Head } \\
\\
\frac{1}{n} & \text{, if Tail} \\
\end{cases}
\]
Note: Task is to check whether the sequence of randome variables \(X_1, X_2, \dots, X_n\) converges in probability
to a known random variable \(X\) as \(n\rightarrow\infty\).
So, we can conclude that, if \(n > \frac{1}{\epsilon}\), then:
\[
\lim_{n\rightarrow\infty} P(|X_n - X| \ge \epsilon) = 0, \forall ~ \epsilon >0 \\[10pt]
\text{Converges in Probability } \\[10pt]
\implies X_n \xrightarrow{Probability} X
\]
Almost Sure Convergence
A sequence of random variables \(X_1, X_2, \dots, X_n\) is said to almost surely converge to a known random variable \(X\), for \(n \ge 1\), if the following is true:
\[
P(\lim_{n\rightarrow\infty} X_n = X) = 1 \\[10pt]
\text{Almost Sure or With Probability = 1 } \\[10pt]
\implies X_n \xrightarrow{Almost ~ Sure} X
\]
where, \(X_n\): is the estimator or sample based random variable. \(X\): is the known or limiting or target random variable.
If, \(X_n \xrightarrow{Almost ~ Sure} X \), \( \implies X_n \xrightarrow{Probability} X \) But, converse is NOT true.
*Note: Almost Sure convergence is hardest to satisfy amongst all convergence, such as, convergence in probability,
convergence in distribution, etc.
This law states that given a sequence of independent and identically distributed (IID) samples \(X_1, X_1, \dots, X_n\)
from a random variable with finite mean, the sample mean (\(\bar{X_n}\)) converges in probability to
the expected value \(E[X]\) or population mean (\( \mu \)).
Note: Does NOT guarantee that sample mean will be close to population mean, but instead says that - the probability of sample mean being far away from the population mean is low.
Toss a coin large number of times \('n'\), as \(n \rightarrow \infty\), the proportion of heads will probably be very
close to \(0.5\). However, it does NOT rule out the possibility of a rare sequence, e.g., getting 10 consecutive heads. But, the probability of such a rare event is extremely low.
Strong Law of Large Numbers (SLLN)
This law states that given a sequence of independent and identically distributed (IID) samples \(X_1, X_1, \dots, X_n\)
from a random variable with finite mean, the sample mean (\(\bar{X_n}\)) converges almost surely to
the expected value \(E[X]\) or population mean (\( \mu \)).
\[
P(\lim_{n\rightarrow\infty} \bar{X_n} = E[X]) = 1, \text{ as } n \rightarrow \infty \\[10pt]
\frac{1}{n} \sum_{i=1}^{n} X_i \xrightarrow{Almost ~ Sure} E[X], \text{ as } n \rightarrow \infty
\]
Note:
It guarantees that the sequence of sample averages itself converges to population mean, with exception of set of
outcomes that has probability = 0.
Almost certain guarantee; Much stronger statement than Weak Law of Large Numbers.
Toss a coin large number of times \('n'\), as \(n \rightarrow \infty\), the proportion of heads will converge
to \(0.5\), with probability = 1. This means that a sequence where the proportion of heads never settles down to 0.5, is a probability = 0 event.
Application
Almost sure convergence ensures ML model’s reliability by guaranteeing that the average error on a large dataset will
converge to the true error. Thus, providing confidence that model will perform consistently and accurately on unseen data.
A restaurant, on an average, expects to serve 50 customers per hour. What is the probability that the restaurant will serve more than 200 customers in the next hour?
Note: It gives a tighter upper bound than Markov’s Inequality.
Consider a test where the average score is 70/100 marks. What is the probability that a randomly selected student gets a score of 90 marks or more? Given the standard deviation of the test score is 10 marks.
Given, the standard deviation of the test score \(\sigma\) = 10 marks. => Variance = \(\sigma^2\) = 100
Hence, Chebyshev’s Inequality gives a far tighter upper bound of 25% than Markov’s Inequality of 78%(approx).
Chernoff Bound
It is an upper bound on the probability that a random variable deviates from its expected value. It’s an exponentially decreasing bound on the “tail” of a random variable’s distribution,
which can be calculated using its moment generating function.
It is used for sum or average of independent random variables (not necessarily identically distributed).
It provides exponentially tighter bounds, better than Chebyshev’s Inequality’s quadratic decay.
It uses all moments to capture the full shape of the distribution, using the moment generating function(MGF).
\[
P(X \ge c) \le e^{-tc}E[e^{tX}] , \forall t>0\\[10pt]
\text{ where } E[e^{tX}] \text{ is the Moment Generating Function of } X
\]
It is a measure of the amount of information gained when a specific, individual event occurs, and is defined based on
the probability of that event. It is defined as the negative logarithm of the probability of the event.
It is also called ‘Surprisal’.
\[
S(x) = -log(P(x)))
\]
Note: Logarithm(for base > 1) is a monotonically increasing function, so as x increases, log(x) also increases.
So, if probability P(x) increases, then surprise factor S(x) decreases.
Common events have a high probability of occurrence, hence a low surprise factor.
Rare events have a low probability of occurrence, hence a high surprise factor.
Units:
The unit of surprise factor with log base 2 is bits.
with base ’e’ or natural log its nats (natural units of information).
Entropy
It conveys how much ‘information’ we expect to gain from a random event.
Entropy is the average or expected value of surprise factor of a random variable.
More uniform the distribution ⇒ greater average surprise factor, since all possible outcomes are equally likely.
It is a measure of the average ‘information gain’ or ‘surprise’ when using an imperfect model \(Q\) to encode events
from a true model \(P\).
It measures how surprised we are on an average, if the true distribution is \(P\), but we predict using another distribution
\(Q\).
\[
H(P,Q) = E[-log(Q(x)] = -\sum_{i=1}^n P(x_i)log(Q(x_i)) \\[10pt]
\text{ where true distribution of X} \sim P \text{ but the predictions are made using another distribution } Q
\]
A model is trained to classify images as ‘cat’ or ‘dog’. Say, for an input image the true label is ‘cat’,
so the true distribution: \(P = [1.0 ~(cat), 0.0 ~(dog)]\). Let’s calculate the cross-entropy for the outputs of 2 models A & B.
Model A: \(Q_A = [0.8 ~(cat), 0.2 ~(dog)]\) Cross Entropy = \(H(P, Q_A) = -\sum_{i=1}^n P(x_i)log(Q_A(x_i)) \) \(= -[1*log_2(0.8) + 0*log_2(0.2)] \approx 0.32 ~bits\) Note: This is very low cross-entropy, since the predicted value is very close to actual, i.e low surprise.
Model B: \(Q_B = [0.2 ~(cat), 0.8 ~(dog)]\) Cross Entropy = \(H(P, Q_B) = -\sum_{i=1}^n P(x_i)log(Q_B(x_i)) \) \(= -[1*log_2(0.2) + 0*log_2(0.8)] \approx 2.32 ~bits\) Note: Here the cross-entropy is very high, since the predicted value is quite far from the actual truth, i.e high surprise.
It measures the information lost when one probability distribution \(Q\) is used to approximate another distribution \(P\). It quantifies the ‘extra cost’ in bits needed to encode data using the approximate distribution \(Q\) instead of
the true distribution \(P\).
If \(P = Q\) ,i.e, P and Q are the same distributions, then KL Divergence = 0.
KL divergence is NOT symmetrical ,i.e, \(D_{KL}(P \parallel Q) ⍯ (D_{KL}(Q \parallel P)\).
Using the same cat, dog classification problem example as mentioned above. A model is trained to classify images as ‘cat’ or ‘dog’. Say, for an input image the true label is ‘cat’,
so the true distribution: \(P = [1.0 ~(cat), 0.0 ~(dog)]\). Let’s calculate the KL divergence for the outputs of the 2 models A & B. Let’s calculate entropy first, and we can reuse the cross-entropy values calculated above already. Entropy: \(H(P) = -\sum_{x \in X} P(x)log(P(x)) = -[1*log_2(1) + 0*log_2(0)] = 0 ~bits\) Note: \(0*log_2(0) = 0\), is an approximation hack, since \(log(0)\) is undefined.
Model A: \( D_{KL}(P \parallel Q) = H(P, Q) - H(P) = 0.32 - 0 = 0.32 ~bits \) Model A incurs an additional 0.32 bits of surprise due to its imperfect prediction.
Model B: \( D_{KL}(P \parallel Q) = H(P, Q) - H(P) = 2.32 - 0 = 2.32 ~bits \) Model B has much more ‘information loss’ or incurs higher ‘penalty’ of 2.32 bits as its prediction was from from the truth.
It is a smoothed and symmetric version of the Kullback-Leibler (KL) divergence and is calculated by averaging the KL divergences between each of the two distributions and their combined average distribution.
Symmetrical and smoothed version of KL divergence.
Always finite; KL divergence can be infinite if \( P ⍯ 0 ~and~ Q = 0 \).
Makes JS divergence more stable for ML models where some predicted probabilities may be exactly 0.
Let’s continue the cat and dog image classification example discussed above. A model is trained to classify images as ‘cat’ or ‘dog’. Say, for an input image the true label is ‘cat’,
so the true distribution: \(P = [1.0 ~(cat), 0.0 ~(dog)]\).
Step 1: Calculate the average distribution M.
\[
M = \frac{P + Q}{2} = \frac{1}{2} [[1.0, 0.0] + [0.8, 0.2]] \\[10pt]
=> M = [0.9, 0.1]
\]
It is the process of finding the best-fitting finite set of parameters \(\Theta\) for a model that assumes a
specific probability distribution for the data. It involves using the dataset to estimate the parameters (like the mean and standard deviation of a normal distribution)
that define the model.
\(P(X \mid \Theta) \) : Probability of seeing data \(X: (X_1, X_2, \dots, X_n) \), given the parameters \(\Theta\) of the
underlying probability distribution from which the data is assumed to be generated.
Goal of estimation: We observed data, \( D = \{X_1, X_2, \dots, X_n\} \), and we want to infer the the unknow parameters \(\Theta\)
of the underlying probability distribution, assuming that the data is generated I.I.D. Read more for I.I.D
Note: Most of the time, from experience, we know the underlying probability distribution of data,
such as, Bernoulli, Gaussian, etc.
2 Approaches
There are 2 philosophical approaches to estimate the parameters of a parametric model:
Frequentist:
Parameters \(\Theta\) is fixed, but unknown, only data is random.
It views probability as the long-run frequency of events in repeated trials; e.g toss a coin ’n’ times.
It is favoured when the sample size is large.
For example, Maximum Likelihood Estimation(MLE), Method of Moments, etc.
Bayesian:
Parameters \(\Theta\) itself is unknown, so we model it as a random variable with a probability distribution.
It views probability as a degree of belief that can be updated with new evidence, i.e. data. Thus, integrating prior knowledge with data to express the uncertainty about the parameters.
It is favoured when the sample size is small, as it uses prior belief about the data distribution too.
For example, Maximum A Posteriori Estimation(MAP), Minimum Mean Square Error Estimation(MMSE), etc..
It is the most popular frequentist approach to estimate the parameters of a model. This method helps us find the parameters \(\Theta\) that make the data most probable.
Likelihood Function: Say, we have data, \(D = X_1, X_2, \dots, X_n\) are I.I.D discrete random variable with PMF = \(P_{\Theta}(.)\) Then, the likelihood function is the probability of observing the data, \(D = \{X_1, X_2, \dots, X_n\}\),
given the parameters \(\Theta\).
In order to find the parameter \(\Theta_{ML}\) that maximises the likelihood function, we need to take the first derivative of the likelihood function with respect to \(\Theta\) and equate it to zero. But, taking derivative of a product is challenging, so we will take the logarithm on both sides. Note: Log is a monotonically increasing function, i.e, as x increases, log(x) increases too.
Let us denote the log-likelihood function as \(\bar{L}\).
In order to find the parameter \(\theta_{ML}\), we need to take the first derivative of the log-likelihood function
with respect to \(\theta\) and equate it to zero. Read more about Derivative
Say, e.g., we have 10 observations for the Bernoulli random variable as: 1,0,1,1,0,1,1,0,1,0. Then, the parameter \(\Theta_{ML} = \frac{6}{10} = 0.6\) i.e proportion of 1’s.
Given \(X_1, X_2, \dots, X_n\) are I.I.D. Gaussian \( \sim N(\mu, \sigma^2) \) \(x_1, x_2, \dots, x_n\) are the realisations/observations of the random variable.
Estimate the parameters \(\mu\) and \(\sigma\) of the Gaussian distribution using Maximum Likelihood Estimation.
Instead of finding \(\mu\) and \(\sigma\) that maximises the log-likelihood function, we can find \(\mu\) and \(\sigma\) that minimises the negative of the log-likelihood function.
Now, lets differentiate the log likelihood function wrt \(\mu\) and \(\sigma\) separately to get \(\mu_{ML}, \sigma_{ML}\).
Lets, calculate \(\mu_{ML}\) first by taking the derivative of the log-likelihood function wrt \(\mu\) and equating it to 0. Read more about Derivative
Bayesian statistics model parameters by updating initial beliefs (prior probabilities) with observed data to form
a final belief (posterior probability) using Bayes’ Theorem. Instead of a single point estimate, it provides a probability distribution over possible parameter values,
which allows to quantify uncertainty and yields more robust models, especially with limited data.
\(P(\Theta)\): Prior: Initial distribution of \(\Theta\) before seeing the data. \(P(X \mid \Theta)\): Likelihood: Conditional distribution of data \(X\), given the parameter \(\Theta\). \(P(\Theta \mid X)\): Posterior: Conditional distribution of parameter \(\Theta\), given the data \(X\). \(P(X)\): Evidence: Probability of seeing the data \(X\).
\(X_1, X_2, \dots, X_n\) are I.I.D. Bernoulli random variable. \(x_1, x_2, \dots, x_n\) are the realisations, \(\Theta \in [0, 1] \). Estimate the parameter \(\Theta\) using Bayesian statistics.
Let, \(n_1 = \) number of 1’s in the dataset. Prior: \(P(\Theta)\) : \(\Theta \sim U(0, 1) \), i.e, parameter \(\Theta\) comes from a continuos uniform
distribution in the range [0,1]. \(f_{\Theta}(\theta) = 1, \theta \in [0, 1] \)
Note: The most difficult part is to calculate the denominator \(f_{X}(x)\). So, either we try NOT to compute it all together, or we try to map it to some known functions to make calculations easier.
We know that we can get the marginal probability by integrating the joint probability over another variable.
Suppose, in the above example, we are told that the parameter \(\Theta\) is closer to 1 than 0. How will we incorporate this useful information (apriori knowledge) into our parameter estimation?
Note: If we do NOT have enough data, then we should NOT ignore our initial belief. However, if we have enough data, then the data will override our initial belief and the posterior will be dominated by data.
Plot: Prior, Posterior & MLE
Note: Bayesian approach gives us a probability distribution of parameter \(\Theta\).
What if we want to have a single point estimate of the parameter \(\Theta\) instead of a probability distribution?
We can use Bayesian Point Estimators, after getting the posterior distribution, to summarize it with a single value for
practical use, such as,
Given a Gaussian distribution, \( X \sim N(\Theta, 1) \) with a prior belief that \(\mu\) is equally likely to be 0 or 1. Estimate the unknown parameter \(\mu\) using MAP.
Given that : \(\Theta\) is discrete, with probability 0.5 for both 0 and 1. => The Gaussian distribution is equally likely to be centered at 0 or 1. Variance: \(\sigma^2 = 1\)
Here computing \(f_{X}(x)\) is difficult. So, instead of differentiating above equation wrt \(\Theta\), and equating to 0, we will calculate the above expression for \(\theta=0\) and \(\theta=1\) and compare the values. This way we can get rid of the common value \(f_{X}(x)\) in both expressions that is not dependent on \(\Theta\).
So, we can say that \(\theta = 1\) only if : the value of the above expression for \(\theta = 1\) > the value of the above expression for \(\theta = 0\)
From equation 3 and 4:
Note: If the prior is uniform then \(\Theta_{MAP} = \Theta_{MLE}\), because uniform prior does NOT give any information
about the initial bias, and all possibilities are equally likely.
What if, in the above example, we know that the initial belief is not uniform but biased towards 0? Prior:
Now, let’s compare the log-posterior for both the cases i.e \(\theta=0\) and \(\theta=1\) as we did earlier. But, note that this time the probabilities for \(\theta=0\) and \(\theta=1\) are different.
So, we can say that \(\theta = 1\) only if : the value of the above expression for \(\theta = 1\) > the value of the above expression for \(\theta = 0\)
From equation 3 and 4 above:
MAP estimator is good for classification like problems, such as Yes/No, True/False, etc. e.g: Patient has a certain disease or not. But, what if we want to minimize average magnitude of errors, over time, say predicting a stock’s price? Just getting to know whether the prediction was right or wrong is not sufficient here. We also want to know that the prediction was wrong by how much, so that we can minimize the loss over time.
We can use Minimum Mean Square Error (MMSE) Estimator to do this.
Minimum Mean Square Error (MMSE) Estimation
Minimizes the expected value of squared error. Mean of the posterior distribution is the conditional expectation of parameter \(\Theta\), given the data.
Posterior mean minimizes the the mean squared error.
Similarly, for the second case where the prior is biased towards 1. Case 2: Prior is biased towards 1 for parameter \(\Theta\) of Bernoulli distribution Prior:
A single number that describes the central, typical, or representative value of a dataset, e.g, mean, median, and mode. The mean is the average, the median is the middle value in a sorted list, and the mode is the most frequently occurring value.
A single representative value can be used to compare different groups or distributions.
Mean
The artihmetic average of a set of numbers i.e sum all values and divide by the number of values. \(mean = \frac{1}{n}\sum_{i=1}^{n}x_i\)
Most common measure of central tendency.
Represents the ‘balancing point’ of data.
Sample mean is denoted by \(\bar{x}\), and population mean by \(\mu\).
Pros:
Uses all datapoints in its calculation, providing a comprehensive measure.
Cons:
Highly sensitive to outliers i.e exteme values.
Example
mean\((1,2,3,4,5) = \frac{1+2+3+4+5}{5} = 3 \)
With outlier: mean\((1,2,3,4,100) = \frac{1+2+3+4+100}{5} = \frac{110}{5} = 22\) Note: Just a single extreme value of 100 has pushed the mean from 3 to 22.
Median
The middle value of a sorted list of numbers. It divides the dataset into 2 equal halves. Calculation:
Arrange the data points in ascending order.
If the number of data points is even, the median is the average of the two middle values.
If the number of data points is odd, the median is the middle value i.e \((\frac{n+1}{2})^{th}\) element.
Pros:
Not impacted by outliers, making it a more robust/reliable measure, especially for skewed distributions.
Cons:
Does NOT use all the datapoints in its calculation.
Example
median\((1,2,3,4,5) = 3\)
median\((1,2,3,4,5,6) = \frac{3+4}{2} = 3.5\)
With outlier: median\((1,2,3,4,100) = 3\) Note: No impact of outlier.
Mode
The most frequently occurring value in a dataset.
Dataset can have 1 mode i.e unimodal, 2 modes i.e bimodal, and more than 2 modes i.e multimodal.
If NO value repeats, then NO mode.
Pros:
Only measure of central tendency that can be used for categorical/nominal data, such as, gender, blood group, level of education, etc.
It can reveal important peaks in data distribution.
Cons:
A dataset can have multiple modes, or no mode at all, which can make mode less informative.
It measures the spread or variability of a dataset. Quantifies how spread out or scattered the data points are. E.g: Range, Variance, Standard Deviation, Median Absoulute Deviation(MAD), Skewness, Kurtosis, etc.
Range
The difference between the largest and smallest values in a dataset. Simplest measure of dispersion \(range = max - min\)
Pros:
Easy to calculate and understand.
Cons:
Only considers the the 2 extreme values of dataset and ignores the distribution of data in between.
Highly sensitive to outliers.
Example
range\((1,2,3,4,5) = 5 - 1 = 4\)
Variance
The average of the squared distance of each value from the mean. Measures the spread of data points.
Highly sensitive to outliers, as squaring amplifies the weight of extreme data points.
Less intuitive to understand, as the units are square of original units.
Standard Deviation
The square root of the variance, measures average distance of data points from the mean.
Low standard deviation indicates that the data points are clustered around the mean, whereas high standard deviation means that the data points are spread out over a wide range.
\(s = sample ~ standard ~ deviation \) \(\sigma = population ~ standard ~ deviation \)
It measures the asymmetry of a data distribution. Tells us whether the data is concentrated on one side of mean and is there a long tail stretching on the other side.
Positive Skew:
Tail is longer on the right side of the mean.
Bulk of data is on the left side of the mean, but there are a few very high values pulling the mean towards the right.
Mean > Median > Mode.
Negative Skew:
Tail is longer on the left side of the mean.
Bulk of data is on the right side of the mean, but there are a few very high values pulling the mean towards the left.
Mean < Median < Mode.
Zero Skew:
Perfectly symmetrical like a normal distribution.
Mean = Median = Mode.
Example
Consider the salary of employees in a company. Most employees earn a very modest salary, but a few executives earn
extremely high salaries. This dataset will be positively skewed with the mean salary > median salary. Median salary would be a better representation of the typical salary of employees.
Kurtosis
It measures the “tailedness” of a data distribution. It describes how much the data is concentrated in tails (fat or thin) versus the center.
It can tell us about the frequency of outliers in the data.
Thick tails => More outliers.
Excess Kurtosis: Excess kurtosis is calculated by subtracting 3 from standard kurtosis in order to compare with normal distribution. Normal distribution has kurtosis = 3.
Mesokurtic:
Excess kurtosis = 0 i.e normal kurtosis.
Tails are neither too thick nor too thin.
Leptokurtic:
High kurtosis, i.e, excess kurtosis > 0 (+ve).
Heavy or thick tails => High probability of outliers.
Sharp peak => High concentration of data around mean.
E.g: Student’s t-distribution, Laplace distribution, etc.
High risk stock portfolios.
Platykurtic:
Low kurtosis, i.e, excess kurtosis < 0 (-ve).
Thin tails => Low probability of outliers.
Low peak => more uniform distribution of values.
E.g: Uniform distribution, Bernoulli(P=0.5) distribution, etc.
It helps us understand the relative position of a data point i.e where a specific value lies within a dataset. E.g: Percentile, Quartile, Inter Quartile Range(IQR), etc.
Percentile
It indicates the percentage of scores in a dataset that are equal to or below a specific value. Here, the complete dataset is divided into 100 equal parts.
\(k^{th}\) percentile => at least \(k\) percent of the data points are equal to or below the value.
It is a relative comparison, i.e, compares a score with the entire group’s performance.
Quartiles are basis for box plots.
Example
90th percentile => score is higher than 90% of of all other test takers.
Quartile
They are special percentiles that divide the complete dataset into 4 equal parts.
Q1 => 25th percentile, value below which 25% of the data falls. Q2 => 50th percentile, value below which 50% of the data falls; median. Q3 => 75th percentile, value below which 75% of the data falls.
IQR = Q3-Q1 = 9-3 = 6 Lower fence = Q1 - 1.5 * IQR = 3 - 9 = -6 Upper fence = Q3 + 1.5 * IQR = 9 + 9 = 18 So, any data point that is less than -6 or greater than 18 is considered as a potential outlier. As in this example, 100 can be considered as an outlier.
Even though the above metrics give us a good idea of the data distribution,
but still we should always plot the data and visually inspect the data distribution. As these metrics may not provide the complete picture.
A mathematician called Francis John Anscombe has illustrated this point beautifully in his Anscombe’s Quartet.
Anscombe’s quartet: It comprises four datasets that have nearly identical simple descriptive statistics, yet have very different distributions and appear very different when plotted.
\(n\) = size of sample \(\bar{x}\) = sample mean of \(X\) \(\bar{y}\) = sample mean of \(Y\)
Note: We have a term (n-1) instead of n in the denominator to make it an unbiased estimate, called Bessel’s Correction.
If both \((x_i - \bar{x})\) and \((y_i - \bar{y})\) have the same sign, then the product is positive(+ve). If both \((x_i - \bar{x})\) and \((y_i - \bar{y})\) have opposite signs, then the product is negative(-ve). The final value of covariance depends on the sum of the above individual products.
\(
\begin{aligned}
\text{Cov}(X, Y) &> 0 &&\Rightarrow \text{ } X \text{ and } Y \text{ increase or decrease together} \\
\text{Cov}(X, Y) &= 0 &&\Rightarrow \text{ } \text{No linear relationship} \\
\text{Cov}(X, Y) &< 0 &&\Rightarrow \text{ } \text{If } X \text{ increases, } Y \text{ decreases (and vice versa)}
\end{aligned}
\)
Limitation: Covariance is scale-dependent, i.e, units of X and Y impact its magnitude. This makes it hard to make comparisons of covariance across different datasets. E.g: Covariance between age and height will NOT be same as the covariance between years of experience and salary.
Note:It only measures the direction of the relationship, but does NOT give any information about the strength of the relationship.
Example
\(X = [1, 2, 3] \) and \(Y = [2, 4, 6] \) Let’s calculate the covariance: \(\text{Cov}(X, Y) = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})\) \(\bar{x} = 2\) and \(\bar{y} = 4\) \(\text{Cov}(X, Y) = \frac{1}{3-1}[(1-2)(2-4) + (2-2)(4-4) + (3-2)(6-4)]= 0\) \( = \frac{1}{2}[2+0+2]= 2\) => Cov(X,Y) > 0 i.e if X increases, Y increases and vice versa.
It measures both the strength and direction of the linear relationship between two variables \(X\) and \(Y\). It is a standardized version of covariance that gives a dimensionless measure of linear relationship.
There are 2 popular ways to calculate correlation coefficient:
Pearson Correlation Coefficient (r)
Spearman Rank Correlation Coefficient (\(\rho\))
Pearson Correlation Coefficient (r)
It is a standardized version of covariance and most widely used measure of correlation. Assumption: Data is normally distributed.
\(\sigma_{x}\) and \(\sigma_{y}\) are the standard deviations of \(X\) and \(Y\).
Range of \(r\) is between -1 and 1. \(r = 1\) => perfect +ve linear relationship between X and Y \(r = -1\) => perfect -ve linear relationship between X and Y \(r = 0\) => NO linear relationship between X and Y.
Note: A correlation coefficient of 0.9 means that there is a strong linear relationship between X and Y,
irrespective of their units.
Let’s calculate the standard deviation of \(X\) and \(Y\): \(\sigma_{x} = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2} \) \(= \sqrt{\frac{1}{3-1}[(1-2)^2 + (2-2)^2 + (3-2)^2]}\) \(= \sqrt{\frac{1+0+1}{2}} =\sqrt{\frac{2}{2}} = 1 \)
Similarly, we can calculate the standard deviation of \(Y\): \(\sigma_{y} = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(y_i - \bar{y})^2} \) \(= \sqrt{\frac{1}{3-1}[(2-4)^2 + (4-4)^2 + (6-4)^2]}\) \(= \sqrt{\frac{4+0+4}{2}} =\sqrt{\frac{8}{2}} = 2 \)
Now, we can calulate the pearson correlation coefficient (r): \(r_{xy} = \frac{Cov(X, Y)}{\sigma_{x} \sigma_{y}}\) => \(r_{xy} = \frac{2}{1* 2}\) => \(r_{xy} = 1\) Therefore, we can say that there is a strong +ve linear relationship between X and Y.
Spearman Rank Correlation Coefficient (\(\rho\))
It is a measure of the strength and direction of the monotonic relationship between two ranked variables \(X\) and \(Y\). It captures monotonic relationship, meaning the variables move in the same or opposite direction, but not necessarily a linear relationship.
It is used when Pearson’s correlation is not suitable, such as, ordinal data, or when the continuous data does not
meet the assumptions of linear methods, such as, Pearson’s correlation.
Non-parametric measure of correlation that uses ranks instead of raw data.
Quantifies how well the ranks of one variable predict the ranks of the other variable.
Compute the correlation of ranks awarded to a group of 5 students by 2 different teacherrs.
Student
Teacher A Rank
Teacher B Rank
\(d_i\)
\(d_i^2\)
S1
1
2
-1
1
S2
2
1
1
1
S3
3
3
0
0
S4
4
5
-1
1
S5
5
4
1
1
\(\sum_{i}d_i^2 = 4 \) \( n = 5 \) \(\rho_{xy} = 1 - \frac{6\sum_{i}d_i^2}{n(n^2-1)}\) => \(\rho_{xy} = 1 - \frac{6*4}{5(5^2-1)}\) => \(\rho_{xy} = 1 - \frac{24}{5*24}\) => \(\rho_{xy} = 1 - \frac{1}{5}\) => \(\rho_{xy} = 0.8\) Therefore, we can say that there is a strong +ve correlation between the ranks given by teacher A and teacher B.
\(X = [1, 2, 3] \) and \(Y = [1, 8, 27] \) Here, Spearman’s rank correlation coefficient \(\rho\) will be perfect 1 as there is a monotonic relationship i.e
as X increases, Y increases and vice versa. But, the Pearson’s correlation coefficient (r) will be slightly less than 1 i.e r = 0.9662.
Correlation is very useful in feature selection for training machine learning models.
If 2 features are highly correlated => they provide redundant information.
One of the features can be removed without significant loss of information.
Keeping both can cause issues, such as, multicollinearity.
If a feature is highly correlated with the target variable => this feature is a strong predictor, so keep it.
A feature with very low or near zero correlation with the target variable may be considered for removal,
as they have little predictive power.
Correlation Vs Causation
Causation means that one variable directly causes the change in another variable, i.e, direct cause->effect relationship. Whereas, correlation means that two variables move together.
Correlation does NOT imply Causation.
Correlation simply shows an association between two variables that could be coincidental or due to some third, unobserved, factor.
E.g: Election results and stock market - there may be some correlation between the two, but establishing clear causal links is difficult.
Before we understand the Central Limit Theorem, let’s understand a few related concepts.
Population Mean
It is the true average of the entire group. It describe the central tendency of the entire population.
\( \mu = \frac{1}{N}\sum_{i=1}^{N}x_i \) N: Number of data points
Sample Mean
It is the average of a smaller representative subset (a sample) of the entire population. It provides an estimate of the population mean.
\( \bar{x} = \frac{1}{n}\sum_{i=1}^{n}x_i \) n: size of sample
Law of Large Numbers
This law states that as the number of I.I.D samples from a population increases, the sample mean converges to the true the population mean. In other words, a long-run average of a repeated random variable approaches the expected value.
Central Limit Theorem
This law states that for a sequence of of I.I.D random variables \( X_1, X_2, \dots, X_n \), with finite mean and variance, the distribution of the sample mean \( \bar{X} \) approaches a normal distribution
as \( n \rightarrow \infty \), regardless of its original population distribution. The distribution of the sample mean is : \( \bar{X} \sim N(\mu, \sigma^2/n)\)
Let, \( X_1, X_2, \dots, X_n \) are I.I.D random variables.
Population mean = \(E[X_i] = \mu < \infty\)
Population Variance = \(Var[X_i] = \sigma^2 < \infty \)
Since, standard deviation = \(\sigma = \sqrt{Variance}\) Therefore, Standard Deviation\([\bar{X_n}] = \sqrt{\frac{\sigma^2}{n}} = \frac{\sigma}{\sqrt{n}}\) The standard deviation of the sample means is also known as “Standard Error”.
Note: We can also standardize the sample mean, i.e, mean centering and variance scaling. Standardisation helps us to use the Z-tables of normal distribution.
We know that, a standardized random variable \(Y_i = \frac{X_i - \mu}{\sigma}\) Similarly, standardized sample mean:
\[
Z_n = \frac{\bar{X_n} - \mu}{\sqrt{Var[\bar{X_n}]}} = \frac{ \frac{1}{n}\sum_{i=1}^{n}X_i - \mu}{\frac{\sigma}{\sqrt{n}}} \\
= \frac{\sum_{i=1}^{n}X_i - n\mu}{\sigma\sqrt{n}} \xrightarrow{Distribution} N(0,1) , \text{ as } n \rightarrow \infty \\
Z_n \text{ converges in distribution to } N(0,1), \text{ as } n \rightarrow \infty
\]
Note: For practical purposes, \(n \ge 30\) is considered as a sufficient sample size for the CLT to hold.
Example
Let’s collect the data for height of people in a city to find the average height of people in the city.
Sample size (n) = 100
And then repeat this data collection process 1000 times.
For each of these 1000 (k) samples, calculate the sample mean \(X_1, X_2, \dots, X_{1000(k)} \)
Now, when we plot these 1000(k) sample means, the resulting distribution will be very close to a normal/Gaussian distribution. \(\bar{X_n} \sim N(\mu, \sigma^2/n)\), for large n, typically \(n \ge 30\).
Note:
‘k’ = a large number of repetitions allows us to observe the distribution of sample means after plotting.
’n’ = number of samples in each repetition is fixed for any given calculation of sample mean \(\bar{X_n}\).
Why variance must be finite?
The variance must be finite, else, the sample mean will NOT converge to a normal distribution. If a distribution has a heavy tail, then the expected value calculation diverges. e.g:
Cauchy distribution has infinite mean and infinite variance.
Pareto distribution (with low alpha) has infinite variance, such as distribution of wealth.
It is a range of values that is likely to contain the true population mean, based on a sample. Instead of giving a point estimate, it gives a range of values with confidence level.
For normal distribution, confidence interval :
\[ CI = \bar{X} \pm Z\frac{\sigma}{\sqrt{n}} \]
\(\bar{X}\): Sample mean \(Z\): Z-score corresponding to confidence level \(n\): Sample size \( \sigma \): Population Standard Deviation
Applications:
A/B testing, i.e., compare 2 or more versions of a product.
ML model performance evaluation, i.e, instead of giving a single performance score of say 85%, it is better to provide a 95% confidence interval, such as, [82.5%, 87.8%].
Meaning of Confidence Interval
95% confidence interval does NOT mean there is a 95% chance that the true mean lies in the specific calculated interval.
It just means that if we repeat the sampling process many times, then 95% of of those calculated intervals will capture
or contain the true population mean \(\mu\).
Also, we cannot say there is 95% probability that the true mean is within that specific range because true population
mean is a fixed constant, NOT a random variable.
Example
Let’s suppose we want to measure the average weight of a certain species of dog. We want to estimate the true population
mean \(\mu\) using confidence interval. Note: True average weight = 30 kg, but this is NOT known to us.
Sample Number
Sample Mean
95% Confidence Interval
Did it capture \(\mu\) ?
1
29.8 kg
(28.5, 31.1)
Yes
2
30.4 kg
(29.1, 31.7)
Yes
3
31.5 kg
(30.2, 32.8)
No
4
28.1 kg
(26.7, 29.3)
No
-
-
-
-
-
-
-
-
-
-
-
-
100
29.9 kg
(28.6, 31.2)
Yes
We generated 100 confidence intervals(CI) each based on different samples.
95% CI guarantees that, in long run, 95 out of 100 CIs will include the true average weight, i.e, \(\mu=30kg\),
and may be will miss 5 out of 100 times.
Suggest which company is offering a better salary? Below is the details of the salaries based on a survey of 50 employees.
Company
Average Salary(INR)
Standard Deviation
A
36 lpa
7 lpa
B
40 lpa
14 lpa
For comparison, let’s calculate the 95% confidence interval for the average salaries of both companies A and B. We know that: \( CI = \bar{X} \pm Z\frac{\sigma}{\sqrt{n}} \) Margin of Error(MoE) \( = Z\frac{\sigma}{\sqrt{n}} \) Z-Score for 95% CI = 1.96
\(MoE_A = 1.96*\frac{7}{\sqrt{50}} \approx 1.94 \) => 95% CI for A = \(36 \pm 1.94 \) = [34.06, 37.94]
\(MoE_B = 1.96*\frac{14}{\sqrt{50}} \approx 3.88\) => 95% CI for B = \(40 \pm 3.88 \) = [36.12, 43.88]
We can see that initially company B’s salary looked obviously better, but after calculating the 95% CI, we can see that there is a significant overlap in the salaries of two companies, i.e [36.12, 37.94].
An idea that is suggested as a possible explanation for a phenomenon, but has not been found to be true.
Why do we need Hypothesis Testing?
Hypothesis Testing is used to determine whether a claim or theory about a population is supported by a sample data, by assessing whether observed difference or patterns are likely due to chance or represent a true effect.
It allows companies to test marketing campaigns or new strategies on a small scale before committing to larger investments.
Based on the results of hypothesis testing, we can make reliable inferences about the whole group based on a representative sample.
It helps us determine whether an observed result is statistically significant finding, or if it could have just happened by random chance.
Hypothesis Testing
It is a statistical inference framework used to make decisions about a population parameter, such as, the mean, variance,
distribution, correlation, etc., based on a sample of data.
It provides a formal method to evaluate competing claims.
Null Hypothesis (\(H_0\)): Status quo or no-effect or no difference statement; almost always contains a statement of equality.
Alternative Hypothesis (\(H_1 ~or~ H_a\)): The statement representing an effect, a difference, or a relationship. It must be true if the null hypothesis is rejected.
Types of Hypothesis Testing
Test of Means:
1-Sample Mean Test: Compare sample mean to a known population mean.
2-Sample Mean Test: Compare means of 2 populations.
Paired Mean Test: Compare means when data is paired, e.g., before vs. after test.
We can structure any hypothesis test in 6 steps as follows:
Step 1: Define the null and alternative hypotheses. Step 2: Select a relevant statistical test for the task with associated test statistic. Step 3: Calculate the test statistic under null hypothesis. Step 4: Select a significance level (\(\alpha\)), i.e, the maximum acceptable false positive rate; typically - 5% or 1%. Step 5: Compute the p-value from the observed value of test-statistic. Step 6: Make a decision to either accept or reject the null hypothesis, based on the significance level (\(\alpha\)).
Perform a hypothesis test to compare the mean recovery time of 2 medicines.
Say, the data, D: <patient_id, med_1/med_2, recovery_time(in days)> We need some metric to compare the recovery times of 2 medicines. We can use the mean recovery time as the metric, because we know that we can use following techniques for comparison:
2-Sample T-Test; if \(n < 30\) and population standard deviation \(\sigma\) is unknown.
2-Sample Z-Test; if \(n \ge 30\) and population standard deviation \(\sigma\) is known.
Note: Let’s assume the sample size \(n < 30\), because medical tests usually have small sample sizes. => We will use the 2-Sample T-Test; we will continue using T-Test throughout the discussion.
Step 1: Define the null and alternative hypotheses. Null Hypothesis \(H_0\): The mean recovery time of 2 medicines is the same i.e \(Mean_{m1} = Mean_{m2}\) or \(m_{m1} = m_{m2}\). Alternate Hypothesis \(H_a\): \(m_{m1} < m_{m2}\) (1-Sided T-Test) or \(m_{m1} ⍯ m_{m2}\) (2-Sided T-Test).
Step 2: Select a relevant statistical test for the task with associated test statistic. Let’s do a 2 sample T-Test, i.e, \(m_{m1} < m_{m2}\)
Step 3: Calculate the test statistic under null hypothesis. Test Statistic: For 2 sample T-Test:
Note: If the 2 means are very close then \(t_{obs} \approx 0\).
Step 4: Suppose significance level (\(\alpha\)) = 5% or 0.05.
Step 5: Compute the p-value from the observed value of test-statistic. P-Value:
\[p_{value} = \mathbb{P}(t \geq t_{obs} | H_0)\]
p-value = area under curve = probability of observing test statistic \( \ge t_{obs} \) if the null hypothesis is true.
Step 6: Accept or reject the null hypothesis, based on the significance level (\(\alpha\)). If \(p_{value} < \alpha\), we reject the null hypothesis and accept the alternative hypothesis and vice versa. Note: In the above example \(p_{value} < \alpha\), so we reject the null hypothesis.
Since, the denominator in above equation is always positive. => \(t_{obs} < 0\) Therefore, we need to do a left sided/tailed test.
So, we want \(t_{obs}\) to be very negative to confidently conclude that alternate hypothesis is true.
Right Sided/Tailed Test: \(H_a\): Mean recovery time of medicine 1 > medicine 2, i.e, \(m_{m_1} > m_{m_2}\) => \(m_{m_1} - m_{m_2} > 0\) Similarly, here we need to do a right sided/tailed test.
2 Sided/Tailed Test: \(H_a\): Mean recovery time of medicine 1 ⍯ medicine 2, i.e, \(m_{m_1} ⍯ ~ m_{m_2}\) => \(m_{m_1} - m_{m_2} < 0\) or \(m_{m_1} - m_{m_2} > 0\) If \(H_a\) is true then \(t_{obs}\) is a large -ve value or a large +ve value.
Since, t-distribution is symmetric, we can divide the significance level \(\alpha\) into 2 equal parts. i.e \(\alpha = 2.5\%\) on each side.
So, we want \(t_{obs}\) to be very negative or very positive to confidently conclude that the alternate hypothesis is true.
We accept \(H_a\) if \(t_{obs} < t^1_{\alpha/2}\) or \(t_{obs} > t^2_{\alpha/2}\).
Note: For critical applications ‘\(\alpha\)’ can be very small i.e. 0.1% or 0.01%, e.g medicine.
if \(t_{obs} < t_{\alpha} => p_{value} \ge \alpha\); therefore, failed to reject null hypothesis.
Power of Test
It is the probability that a hypothesis test will correctly reject a false null hypothesis (\(H_{0}\))
when the alternative hypothesis (\(H_{a}\)) is true.
Power of test = \(1 - \beta\)
Probability of correctly accepting alternate hypothesis (\(H_{a}\))
\(\alpha\): Probability of wrongly accepting alternate hypothesis \(H_{a}\)
\(\beta\): Probability of wrongly rejecting alternate hypothesis \(H_{a}\)
Does having a large sample size make a hypothesis test more powerful?
Yes, having a large sample size makes a hypothesis test more powerful.
As n increases, sample mean \(\bar{x}\) approaches the population mean \(\mu\).
Also, as n increases, t-distribution approaches normal distribution.
P-value only measures whether the observed change is statistically significant.
Effect Size
It is a standardized objective measure that complements p-value by clarifying whether a statistically significant
finding has any real world relevance. It quantifies the magnitude of relationship between two variables.
Larger effect size => more impactful effect.
Standardized (mean centered + variance scaled) measure allows us to compare the imporance of effect across various
studies or groups, even with different sample sizes.
\(\bar{X}\): Sample mean \(s_p\): Pooled Standard deviation \(n\): Sample size \(s\): Standard deviation
Note: Theoretically, Cohen’s d value can range from negative infinity to positive infinity. but for practical purposes, we use the following value: small effect (\(d=0.2\)), medium effect (\(d=0.5\)), and large effect (\(d\ge 0.8\)).
More overlap => less effect i.e low Cohen’s d value.
Example
A study on drug trials finds that patients taking a new drug had statistically significant improvement (p-value<0.05), compared to a placebo group.
Small effect size: Cohen’s d = 0.1 => drug had minimal effect.
Large effect size: Cohen’s d = 0.8 => drug produced substantial improvement.
It is a statistical test that is used to determine whether the sample mean is equal to a hypothesized value or is there a significant difference between the sample means of 2 groups.
It is a parametric test, since it assumes data to be approximately normally distributed.
Appropriate when:
sample size n < 30.
population standard deviation \(\sigma\) is unknown.
It is based on Student’s t-distribution.
Student's t-distribution
It is a continuous probability distribution that is a symmetrical, bell-shaped curve similar
to the normal distribution but with heavier tails.
Shape of the curve or mass in tail is controlled by degrees of freedom.
There are 3 types of T-Test:
1-Sample T-Test: Test if sample mean differs from hypothesized value.
2-Sample T-Test: Test whether there is a significant difference between the means of two independent groups.
Paired T-Test: Test whether 2 related samples differ, e.g., before and after.
Degrees of Freedom (\(\nu\))
It represents the number of independent pieces of information available in the sample to estimate the variability in the data. Generally speaking, it represents the number of independent values that are free to vary in a dataset when
estimating a parameter. e.g.: If we have k observations and their sum = 50. The sum of (k-1) terms can be anything, but the kth term is fixed at 50 - (sum of other (k-1) terms). So, we have only (k-1) terms that can change independently, therefore, the DOF(\(\nu\)) = k-1.
It is used to test whether the sample mean is equal to a known/hypothesized value. Test statistic (t):
\[
t = \frac{\bar{x} - \mu}{s/\sqrt{n}}
\]
where, \(\bar{x}\): sample mean \(\mu\): hypothesized value \(s\): sample standard deviation \(n\): sample size \(\nu = n-1 \): degrees of freedom
A developer claims that the new algorithm improves API response time by 100 ms, on an average. Tester ran the test 20 times and found the average API repsonse time to be 115 ms, with a standard deviation of 25 ms. Is the developer’s claim valid?
Let’s verify developer’s claim using the tester’s test results using 1 sample t-test. Null hypothesis: \(H_0\) = The average API response time is 100 ms, i.e, \(\bar{x} = \mu\). Alternative hypothesis: \(H_a\) = The average API response time > 100 ms, i.e, \(\bar{x} > \mu\) => right tailed test. Hypothesized mean \(\mu\) = 100 ms Sample mean \(\bar{x}\) = 115 ms Sample standard deviation \(s\) = 25 ms Sample size \(n\) = 20 Degrees of freedom \(\nu\) = 19
Let significance level \(\alpha\) = 5% =0.05. Critical value \(t_{0.05}\) = 1.729 Important: Find the value of \(t_{\alpha}\) in T-table
Since \(t_{obs}\) > \(t_{0.05}\), we reject the null hypothesis. And, accept the alternative hypothesis that the API response time is significantly > 100 ms. Hence, the developer’s claim is NOT valid.
\(\bar{x}\): sample mean \(s\): sample standard deviation \(n\): sample size \(\nu\): degrees of freedom
The AI team wants to validate whether the new ML model accuracy is better than the existing model’s accuracy. Below is the data for the existing model and the new model.
New Model (A)
Existing Model (B)
Sample size (n)
24
18
Sample mean (\(\bar{x}\))
91%
88%
Sample std. dev. (s)
4%
3%
Given that the variance of accuracy scores of new and existing models are almost same.
Now, let’s follow our hypothesis testing framework. Null hypothesis: \(H_0\): The accuracy of new model is same as the accuracy of existing model. Alternative hypothesis: \(H_a\): The new model’s accuracy is better/greater than the existing model’s accuracy => right tailed test
Let’s solve this using 2 sample T-Test, since the sample size n < 30. Since the variance of 2 sample are almost equal then we can use the pooled variance method.
Next let’s compute the test statistic, under null hypothesis.
DOF \(\nu\) = \(24+18-2\) = 42 - 2 = 40 Let significance level \(\alpha\) = 5% =0.05. Critical value \(t_{0.05}\) = 1.684 Important: Find the value of \(t_{\alpha}\) in T-table
Since \(t_{obs}\) > \(t_{0.05}\), we reject the null hypothesis. And, accept the alternative hypothesis that the new model has better accuracy than the existing model.
It is used to test whether the sample mean \(\bar{x}\) is significantly different from a known population mean \(\mu\).
Test Statistic:
\[
Z = \frac{\bar{x} - \mu}{\sigma / \sqrt{n}}
\]
\(\bar{x}\): sample mean \(\mu\): hypothesized population mean \(\sigma\): population standard deviation \(n\): sample size \(\sigma / \sqrt{n}\): standard error of mean
Note: Test statistic Z follows a standard normal distribution \(Z \sim \mathcal{N}(0, 1)\).
2-Sample Z-Test
It is used to test whether the sample means \(\bar{x_1}\) and \(\bar{x_2}\) of 2 independent samples are significantly different from each other. Test Statistic:
\[
Z = \frac{\bar{x_1} - \bar{x_2}}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}}
\]
\(\bar{x_1}\): sample mean of first sample \(\bar{x_2}\): sample mean of second sample \(\sigma_1\): population standard deviation of first sample \(\sigma_2\): population standard deviation of second sample \(n_1\): sample size of first sample \(n_2\): sample size of second sample
Note: Test statistic Z follows a standard normal distribution \(Z \sim \mathcal{N}(0, 1)\).
Average time to run a ML model is 120 seconds with a known standard deviation of 15 seconds. After applying a new optimisation, and n=100 runs, yields a sample mean of 117 seconds. Does the optimisation significantly reduce the runtime of the model? Consider the significance level of 5%.
Null Hypothesis: \(\mu = 120\) seconds, i.e, no change. Alternative Hypothesis: \(\mu < 120\) seconds => left tailed test.
We will use 1-sample Z-Test to test the hypothesis. Test Statistic:
Since, significance level \(\alpha\) = 5% =0.05. Critical value \(Z_{0.05}\) = -1.645 Important: Find the value of \(Z_{\alpha}\) in Z-Score Table
Our \(t_{obs}\) is much more extreme than the the critical value \(Z_{0.05}\), => p-value < 5%. Hence, we reject the null hypothesis. Therefore, there is a statistically significant evidence that the new optimisation reduces the runtime of the model.
It is a statistical hypothesis test used to determine if there is a significant difference between the proportion
of a characteristic in two independent samples or to compare a sample proportion to a known population value
It is used when dealing with categorical data, such as, success/failure, male/female, yes/no etc.
It is of 2 types:
1-Sample Z-Test of Proportion: Used to test whether the observed proportion in a sample differs from hypothesized proportion.
2-Sample Z-Test of Proportion: Used to compare whether the 2 independent samples differ in their proportions.
The categorical data,i.e success/failure, is discrete that can be modeled as Bernoulli distribution. Let’s understand how this Bernoulli random variable can be approximated as a Gaussian distribution for a very large sample size,
using Central Limit Theorem. Read more about Central Limit Theorem
Note:We will not prove the complete thing, but we will understand the concept in enough depth for clarity.
Sampling Distribution of a Proportion
\(Y \sim Bernoulli(p)\) \(X \sim Binomial(n,p)\) E[X] = mean = np Var[X] = variance = np(1-p) X = total number of successes p = true probability of success n = number of trials Proportion of Success in sample = Sample Proportion = \(\hat{p} = \frac{X}{n}\) e.g.: If n=100 people were surveyed, and 40 said yes, then \(\hat{p} = \frac{40}{100} = 0.4\)
By Central Limit Theorem, we can state that for very large ’n’ Binomial distribution’s mean and variance can be used as an
approximation for Gaussian/Normal distribution:
\[
X \sim Binomial(n,p) \xrightarrow{n \rightarrow \infty} X \approx N(np, np(1-p)) \\[10pt]
\]
Mean = \(\mu_{\hat{p}} = p\) = True proportion of success in the entire population Standard Error = \(SE_{\hat{p}} = \sqrt{Var[\frac{X}{n}]} = \sqrt{\frac{p(1-p)}{n}}\) = Standard Deviation of the sample proportion
Note: Large Sample Condition - Approximation is only valid when the expected number of successes and failures are both > 10 (sometimes 5). \(np \ge 10 ~and~ n(1-p) \ge 10\)
1-Sample Z-Test of Proportion
It is used to test whether the observed proportion in a sample differs from hypothesized proportion. \(\hat{p} = \frac{X}{n}\): Proportion of success observed in a sample \(p_0\): Specific propotion value under the null hypothesis \(SE_0\): Standard error of sample proportion under the null hypothesis Z-Statistic: Measures how many standard errors is the observed sample proportion \(\hat{p}\) away from \(p_0\) Test Statistic:
A company wants to compare its 2 different website designs A & B. Below is the table that shows the data:
Design
# of visitors(n)
# of signups(x)
conversion rate(\(\hat{p} = \frac{x}{n}\))
A
1000
80
0.08
B
1200
114
0.095
Is the design B better, i.e, design B increases conversion rate or proportion of visitors who sign up? Consider the significance level of 5%.
Null Hypothesis: \(\hat{p_A} = \hat{p_B}\), i.e, no difference in conversion rates of 2 designs A & B. Alternative Hypothesis: \(\hat{p_B} > \hat{p_A}\) i.e conversion rate of B > A => right tailed test.
Check large sample condition for both samples A & B. \(n\hat{p_A} = 80 > 10 ~and~ n(1-\hat{p_A}) = 920 > 10\) Similarly, we can show for B too.
Since, \(t_{obs} < Z_{0.05}\) => p-value > 5%. Hence, we fail to reject the null hypothesis. Therefore, the observed conversion rate of design B is due to random chance; thus, B is not a better design.
A random variable Q is said to follow a chi-square distribution with ’n’ degrees of freedom,i.e \(\chi^2(n)\), if it is the sum of squares of ’n’ independent random variables that follow a standard normal distribution, i.e, \(N(0,1)\).
Shape depends on the degrees of freedom; as \(\nu\) increases, the distribution becomes more symmetric and
approaches a normal distribution.
Degrees of Freedom (\(\nu\))
It represents the number of independent pieces of information available in the sample to estimate the variability in the data. Generally speaking, it represents the number of independent values that are free to vary in a dataset when
estimating a parameter. e.g.: If we have k observations and their sum = 50. The sum of (k-1) terms can be anything, but the kth term is fixed at 50 - (sum of other (k-1) terms). So, we have only (k-1) terms that can change independently, therefore, the DOF(\(\nu\)) = k-1.
Central Limit Theorem states that the sampling distribution of sample means approaches a normal distribution as
the sample size increases, regardless of the distribution of the population. More broadly, we can also say that sum/count of independent random variables approaches a normal distribution as
the sample size increases. Since, sample mean \(\bar{x} = \frac{sum}{n} \).
Note: We are dealing with categorical data, where there is a count associated with each category. In the context of categorical data, the counts \(O_i\) are governed by multinomial distribution (a generalisation of binomial distribution). Multinomial distribution is defined for multiple classes or categories, ‘k’, and multiple trials ’n’. For \(i^{th}\) category: Probability of \(i^{th}\) category = \(p_i\) Mean = Expected count/frequency = \(E_i = np_i \) Variance = \(Var_i = np_i(1-p_i) \)
By Central Limit Theorem, for very large n, i.e, as \(n \rightarrow \infty\), the multinomial distribution can be approximated as a normal distribution. The multinomial distribution of count/frequency can be approximated as : \(O_i \approx N(np_i, np_i(1-p_i))\)
Standardized count (mean centered and variance scaled):
\[
Z_i = \frac{O_i - E_i}{\sqrt{Var_i}} \\[10pt]
=> Z_i = \frac{O_i - np_i}{\sqrt{np_i(1-p_i)}} \xrightarrow{distribution} N(0,1), \text{ as } n \rightarrow \infty \\[10pt]
\xrightarrow{distribution} \text { : means converges in distribution }
\]
Under Null Hypothesis: In Pearson’s proof of the chi-square test, the statistic is divided by the expected value (\(E_{i}\)) instead of the variance (\(Var_{i}\)),
because for count data that can be modeled using a Poisson distribution
(or a multinomial distribution where cell counts are approximately Poisson for large samples),
the variance is equal to the expected value (mean).
Therefore, \(Z_i \approx (O_{i}-E_{i})/\sqrt{E_{i}}\) Note that the denominator is \(\sqrt{E_{i}}\) NOT \(\sqrt{Var_{i}}\).
\(O_{i}\): Observed count for \(i^{th}\) category \(E_{i}\): Expected count for \(i^{th}\) category
Important: \(E_{i}\): Expected count should be large i.e >= 5 (typically) for a good enough approximation.
Chi-Square (\(\chi^2\)) Test Statistic
It is formed by squaring the approximately standard normal counts above, and summing them up. For \(k\) categories, the test statistic is:
Note: All the hypothesis tests get their name from the underlying distribution of the test statistic.
Chi-Square (\(\chi^2\)) Test
It is used to analyze categorical data to determine whether there is a significant difference between observed and expected counts. It is a non-parametric test for categorical data, i.e, does NOT make any assumption about the underlying distribution
of the data, such as, normally distributed with known mean and variance; only uses observed and expected count/frequencies. Note: Requires a large sample size.
Test of Goodness of Fit
It is used to compare the observed frequency distribution of a single categorical variable to a hypothesized or expected
probability distribution. It can be used to determine whether a sample taken from a population follows a particular distribution,
e.g., uniform, normal, etc.
\(O_{i}\): Observed count for \(i^{th}\) category \(E_{i}\): Expected count for \(i^{th}\) category, under null hypothesis \(H_0\) \(k\): Number of categories \(\nu\): Degrees of freedom = k - 1- m \(m\): Number of parameters estimated from sample data to determine the expected probability Note: Typical m=0, since, NO parameters are estimated.
Other Goodness of Fit Tests
Kolmogorov-Smirnov (KS) Test: Compares empirical CDF with theoretical CDF of distribution.
Anderson-Darling (AD) Test: Refinement of KS Test.
Shapiro-Wilk (SW) Test: Specialised for normal distribution; good for small samples.
In a coin toss experiment, we tossed a coin 100 times, and got 62 heads and 38 tails. Find whether it is a fair coin (discrete uniform distribution test)? Significance level = 5%
We need to find whether the coin is fair i.e we need to do a goodness of fit test for discrete uniform distribution.
Null Hypothesis \(H_0\): Coin is fair. Alternative Hypothesis \(H_a\): Coin is biased towards head.
\(O_{H}\): Observed count head = 62 \(O_{T}\): Observed count head = 38 \(E_{i}\): Expected count for \(i^{th}\) category, under null hypothesis \(H_0\) = 50 i.e fair coin \(k\): Number of categories = 2 \(\nu\): Degrees of freedom = k - 1- m = 2 - 1 - 0 = 1 Test Statistic:
It is used to determine whether an association exists between two categorical variables,
using a contingency(dependency) table. It is a non-parametric test, i.e, does NOT make any assumption about the underlying distribution of the data.
\(O_{ij}\): Observed count for \(cell_{i,j}\) \(E_{ij}\): Expected count for \(cell_{i,j}\), under null hypothesis \(H_0\) \(R\): Number of rows \(C\): Number of columns \(\nu\): Degrees of freedom = (R-1)*(C-1)
Let’s understand the above test statistic in more detail. We know that, if 2 random variables A & B are independent, then, \(P(A \cap B) = P(A, B) = P(A)*P(B)\) i.e Joint Probability = Product of marginal probabilities.
Null Hypothesis \(H_0\): \(A\) and \(B\) are independent. Alternative Hypothesis \(H_a\): \(A\) and \(B\) are dependent or associated. N = Sample size \(P(A_i) \approx \frac{Row ~~ Total_i}{N}\)
\(P(B_j) \approx \frac{Col ~~ Total_j}{N}\)
\(E_{ij}\) : Expected count for \(cell_{i,j}\) = \( N*P(A_i)*P(B_j)\)
=> \(E_{ij}\) = \(\frac{Row ~~ Total_i * Col ~~ Total_j}{N}\)
\(O_{ij}\): Observed count for \(cell_{i,j}\)
A survey of 100 students was conducted to understand whether there is any relation between gender and beverage preference. Below is the table that shows the number of students who prefer each beverage.
Gender
Tea
Coffee
Male
20
30
50
Female
10
40
50
30
70
Significance level = 5%
Null Hypothesis \(H_0\): Gender and beverage preference are independent. Alternative Hypothesis \(H_a\): Gender and beverage preference are dependent.
We know that Expected count for cell(i,j) = \(E_{ij}\) = \(\frac{Row ~~ Total_i * Col ~~ Total_j}{N}\)
They are quantitative measures used to evaluate how well a machine learning model performs on unseen data. E.g.: For regression models, we have - MSE, RMSE, MAE, R^2 metric, etc. Here, we will discuss various performance metrics for classification models.
Confusion Matrix
It is a table that summarizes model’s predictions against the actual class labels, detailing where the model
succeeded and where it failed. It is used for binary or multi-class classification problems.
Predicted Positive
Predicted Negative
Actual Positive
True Positive (TP)
False Negative (FN)
Actual Negative
False Positive (FP)
True Negative (TN)
Type-1 Error: It is the number of false positives. e.g.: Model predicted that a patient has diabetes, but the patient actually does NOT have diabetes; “false alarm”.
Type-2 Error: It is the number of false negatives.
e.g.: Model predicted that a patient does NOT have diabetes, but the patient actually has diabetes; “a miss”.
Many metrics are derived from the confusion matrix.
Precision: It answers the question: “Of all the instances that the model predicted as positive, how many were actually positive?” It measures exactness or quality of the positive predictions.
\[
Precision = \frac{TP}{TP + FP}
\]
Recall: It answers the question: “Of all the actual positive instances, how many did the model correctly identify?” It measures completeness or coverage of the positive predictions.
\[
Recall = \frac{TP}{TP + FN}
\]
F1 Score: It is the harmonic mean of precision and recall. It is used when we need a balance between precision and recall; also helpful when we have imbalanced data. Harmonic mean penalizes extreme values more heavily, encouraging both metrics to be high.
Trade-Off: Precision Focus:: Critical when cost of false positives is high. e.g: Identify a potential terrorist. A false positive, i.e, wrongly flagging an innocent person as a potential terrorist is very harmful.
Recall Focus:: Critical when cost of false negatives is high. e.g.: Medical diagnosis of a serious disease. A false negative, i.e, falsely missing a serious disease can cost someone’s life.
Analyze the performance of an access control system. Below is the data for 1000 access attempts.
It is a graphical plot that shows the discriminating ability of a binary classifier system, as its
discrimination threshold is varied. Y-axis: True Positive Rate (TPR), Recall, Sensitivity \(TPR = \frac{TP}{TP + FN}\)
Note: A binary classifier model outputs a probability score between 0 and 1. and a threshold (default=0.5) is applied to the probability score to get the final class label. \(p \ge 0.5\) => Positive Class \(p < 0.5\) => Negative Class
Algorithm:
Sort the data by the probability score in descending order.
Set each probability score as the threshold for classification and calculate the TPR and FPR for each threshold.
Plot each pair of (TPR, FPR) for all ’n’ data points to get the final ROC curve.
e.g.:
Patient_Id
True Label \(y_i\)
Predicted Probability Score \(\hat{y_i}\)
1
1
0.95
2
0
0.85
3
1
0.72
4
1
0.63
5
0
0.59
6
1
0.45
7
1
0.37
8
0
0.20
9
0
0.12
10
0
0.05
Set the threshold \(\tau_1\) = 0.95, calculate \({TPR}_1, {FPR}_1\) Set the threshold \(\tau_2\) = 0.85, calculate \({TPR}_2, {FPR}_2\) Set the threshold \(\tau_3\) = 0.72, calculate \({TPR}_3, {FPR}_3\) … … Set the threshold \(\tau_n\) = 0.05, calculate \({TPR}_n, {FPR}_n\)
Now, we have ’n’ pairs of (TPR, FPR) for all ’n’ data points. Plot the points on a graph to get the final ROC curve.
AU ROC = AUC = Area under the ROC curve = Area under the curve
Note:
If AUC < 0.5, then invert the labels of the classes.
ROC does NOT perform well on imbalanced data.
Either balance the data or
Use Precision-Recall curve.
What is the AUC of a random binary classifier model?
AUC of a random binary classifier model = 0.5 Since, labels are randomly generated as 0/1 for binary classification, so 50% labels from each class. Because random number generators generate numbers uniformly in the given range.
Why ROC can be misleading for imbalanced data ?
Let’s understand this with the below fraud detection example. Below is a dataset from a fraud detection system for N = 10,000 transactions. Fraud = 100, NOT fraud = 9900
If we check the location of above (TPR, FPR) pair on the ROC curve, then we can see that it is
very close to the top-left corner. This means that the model is very good at detecting fraudulent transactions, but that is NOT the case. This is happening because of the imbalanced data, i.e, count of NOT fraud transactions is 99 times
of fraudulent transactions.
We can see that the model has poor precision,i.e, only 26.7% of flagged transactions are actual frauds. Unacceptable precision for a good fraud detection system.
It is used to evaluate the performance of a binary classifier model across various thresholds. It is similar to the ROC curve, but it uses Precision instead of TPR on the Y-axis. Plots Precision (Y-axis) against Recall (X-axis) for different classification thresholds. Note: It is useful when the data is imbalanced.
If we check the location of above (Precision, Recall) point on PRC curve, we will find that it is located near the
bottom right corner, i.e, the model performance is poor.
Vector is a fundamental concept used to describe the real world, which has magnitude and direction,
e.g., force, velocity, electromagnetism, etc. It is used to describe the surrounding space, e.g, lines, planes, 3D space, etc. And, In machine learning, vectors are used to represent data, both the input features and the output of a model.
Vector
It is a collection of scalars(numbers) that has both magnitude and direction. Geometrically, it is a line segment in space characterized by its length(magnitude) and direction. By convention, we represent vectors as column vectors. e.g.:
\(\vec{x} = \mathbf{x} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix}_{\text{n×1}}\) i.e ’n’ rows and 1 column.
Important: In machine learning, we will use bold notation \(\mathbf{v}\) to represent vectors, instead
of arrow notation \(\mathbf{v}\).
Transpose
Swap the rows and columns, i.e, a column vector becomes a row vector after transpose. e.g:
\(\mathbf{v} = \begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_d \end{bmatrix}_{\text{d×1}}\)
The length (or magnitude or norm) of a vector \(\mathbf{v}\) is the distance from the origin to the point represented by \(\mathbf{v}\) in n-dimensional space.
The direction of a vector tells us where the vector points in space, independent of its length.
Direction of vector:
\[\mathbf{v} = \frac{\vec{v}} {\|\mathbf{v}\|} \]
Vector Space
It is a collection of vectors that can be added together and scaled by numbers (scalars), such that,
the results are still in the same space. Vector space or linear space is a non-empty set of vectors equipped with 2 operations:
Vector addition: for any 2 vectors \(a, b\), \(a + b\) is also in the same vector space.
Scalar multiplication: for a vector \(\mathbf{v}\), \(\alpha\mathbf{v}\) is also in the same vector space;
where \(\alpha\) is a scalar. Note: These operations must satisfy certain rules (called axioms), such as,
associativity, commutativity, distributivity, existence of a zero vector, and additive inverses.
e.g.: Set of all points in 2D is a vector space.
Vector Operations
Addition: We can only add vectors of the same dimension.
2.Inner (Dot) Product: Inner(dot) product \(\mathbf{u} \cdot \mathbf{v}\) of 2 vectors gives a scalar output. The two vectors must be of the same dimensions.
2.Outer (Tensor) Product: Outer (tensor) product \(\mathbf{u} \otimes \mathbf{v}\) of 2 vectors gives a matrix output. The two vectors must be of the same dimensions.
because, \(\mathbf{w} = 2\mathbf{v}\), and we have a non-zero solution for the below equation: \(\alpha_1 \mathbf{u} + \alpha_2 \mathbf{v} + \alpha_3 \mathbf{w} = 0\); \(\alpha_1 = 0, \alpha_2 = -2, \alpha_3 = 1\) is a valid non-zero solution.
Note:
A common method to check linear independence is to arrange the column vectors in a matrix form and
calculate its determinant, if determinant ≠ 0, then the vectors are linearly independent.
If number of vectors > number of dimensions, then the vectors are linearly dependent. Since, the \((n+1)^{th}\) vector can be expressed as a linear combination of the other ’n’ vectors in n-dimensional space.
In machine learning, if a feature can be expressed in terms of other features, then it is linearly dependent, and the feature is NOT bringing any new information. e.g.: In 2 dimensions, 3 vectors \(\mathbf{x_1}, \mathbf{x_2}, \mathbf{x_3} \) are linearly dependent.
Span
Span of a set of vectors is the geometric shape by all possible linear combinations of those vectors, such as,
line, plane, or higher dimensional volume. e.g.:
Span of a single vector (1,0) is the entire X-axis.
Span of 2 vectors (1,0) and (0,1) is the entire X-Y (2D) plane, as any vector in 2D plane can be expressed as a
linear combination of the 2 vectors - (1,0) and (0,1).
Basis
It is the minimal set of linearly independent vectors that spans or defines the entire vector space,
providing a unique co-ordinate system for every vector within the space. Every vector in the vector space can be represented as a unique linear combination of the basis vectors. e.g.:
X-axis(1,0) and Y-axis(0,1) are the basis vectors of 2D space or form the co-ordinate system.
\(\mathbf{u} = (3,1)\) and \(\mathbf{v} = (-1, 2) \) are the basis of skewed or parallelogram co-ordinate system.
Note: Basis = Dimensions
Orthogonal Vectors
Two vectors are orthogonal if their dot product is 0. A set of vectors \(\mathbf{x_1}, \mathbf{x_2}, \cdots ,\mathbf{x_n} \) are said to be orthogonal if: \(\mathbf{x_i} \cdot \mathbf{x_j} = 0 \forall i⍯j\), for every pair, i.e, every pair must be orthogonal. e.g.:
\(\mathbf{u} = (1,0)\) and \(\mathbf{v} = (0,1) \) are orthogonal vectors.
\(\mathbf{u} = (1,0)\) and \(\mathbf{v} = (1,1) \) are NOT orthogonal vectors.
Note:
Orthogonal vectors are linearly independent, but the inverse may NOT be true, i.e, linear independence does NOT imply that vectors are orthogonal.
e.g.: Vectors \(\mathbf{u} = (2,0)\) and \(\mathbf{v} = (1,3) \) are linearly independent but NOT orthogonal. Since, \(\mathbf{u} \cdot \mathbf{v} = 2*1 + 3*0 = 2 ⍯ 0\).
Orthogonality is the most extreme case of linear independence, i.e \(90^{\degree}\) apart or perpendicular.
Orthonormal Vectors
Orthonormal vectors are vectors that are orthogonal and have unit length. A set of vectors \(\mathbf{x_1}, \mathbf{x_2}, \cdots ,\mathbf{x_n} \) are said to be orthonormal if: \(\mathbf{x_i} \cdot \mathbf{x_j} = 0 \forall i⍯j\) and \(\|\mathbf{x_i}\| = 1\), i.e, unit vector.
e.g.:
\(\mathbf{u} = (1,0)\) and \(\mathbf{v} = (0,1) \) are orthonormal vectors.
\(\mathbf{u} = (1,0)\) and \(\mathbf{v} = (0,2) \) are NOT orthonormal vectors.
Orthonormal Basis
It is a set of vectors that functions as a basis for a space while also being orthonormal, meaning each vector is a unit vector (has a length of 1) and all vectors are mutually perpendicular (orthogonal) to each other. A set of vectors \(\mathbf{x_1}, \mathbf{x_2}, \cdots ,\mathbf{x_n} \) are said to be orthonormal basis of a vector space
\(\mathbb{R}^{n \times 1}\), if every vector:
\(\mathbf{u} = (1,0)\) and \(\mathbf{v} = (0,1) \) form an orthonormal basis for 2-D space.
\(\mathbf{u} = (\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})\) and \(\mathbf{v} = (-\frac{1}{\sqrt{2}},-\frac{1}{\sqrt{2}}) \)
also form an orthonormal basis for 2-D space.
Note: In a n-dimensional space, there are only \(n\) possible orthonormal bases.
Multiplication: We can multiply two matrices only if their inner dimensions are equal. \( \mathbf{C}_{m x n} = \mathbf{A}_{m x d} ~ \mathbf{B}_{d x n} \)
\( c_{ij} \) = Dot product of \(i^{th}\) row of A and \(j^{th}\) row of B. \( c_{ij} = \sum_{k=1}^{d} A_{ik} * B_{kj} \) => \( c_{11} = a_{11} * b_{11} + a_{12} * b_{21} + \cdots + a_{1d} * b_{d1} \)
Note: Diagonal elements of a skew symmetric matrix are zero, since the number should be equal to its negative.
Identity Matrix: It is a square matrix with all the diagonal values equal to 1, rest of the elements are equal to zero. e.g.: \( \mathbf{I} =
\begin{bmatrix}
1 & 0 & \cdots & 0 \\
0 & 1 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & 1
\end{bmatrix}
_{\text{n x n}}
\)
Trace: It is the sum of the elements on the main diagonal of a square matrix. Note: Main diagonal is NOT defined for a rectangular matrix. \( \text{trace}(A) = \sum_{i=1}^{n} a_{ii} = a_{11} + a_{22} + \cdots + a_{nn}\)
If \( \mathbf{A} \in \mathbb{R}^{m \times n} \), and \( \mathbf{B} \in \mathbb{R}^{n \times m} \), then \( \text{trace}(AB)_{m \times m} = \text{trace}(BA)_{n \times n} \)
Determinant: It is a scalar value that reveals crucial properties about the matrix and its linear transformation.
If determinant = 0 => singular matrix, i.e linearly dependent rows or columns.
Determinant is also equal to the scaling factor of the linear transformation.
\(a_{1j} \) = element in the first row and j-th column \(M_{1j} \) = submatrix of the matrix excluding the first row and j-th column
If n = 2, then,
\( |A| = a_{11} \, a_{22} - a_{12} \, a_{21} \)
Singular Matrix: A square matrix with linearly dependent rows or columns, i.e, determinant = 0. A singular matrix collapses space, say, a 3D space, into a 2D space or a higher dimensional space
to a lower dimensional space, making the transformation impossible to reverse. Hence, a singular matrix is NOT invertible; i.e, inverse does NOT exist. Singular matrix is also NOT invertible, because the inverse has division by determinant, and its determinant is zero. Also called rank deficient matrix, because the rank < number of dimensions of the matrix,
due to the presence of linearly dependent rows or columns.
\( det(\beta A) = \beta^n det(A) \), where n is the number of dimensions of A and \(\beta\) is a scalar.
Inverse: It is a square matrix that when multiplied by the original matrix, gives the identity matrix. \( \mathbf{A} \mathbf{A}^{-1} = \mathbf{A}^{-1} \mathbf{A} = \mathbf{I} \)
\[
A^{-1} = \frac{1}{|A|} \, \text{adj}(A)
\]
Steps to compute inverse of a matrix:
Calculate the determinant of the matrix.
\( |A| = \det(A) \)
For each element \(a_{ij}\), compute its minor \(M_{ij}\). \(M_{ij}\) is the determinant of the submatrix of the matrix excluding the i-th row and j-th column.
Form the co-factor matrix \(C_{ij}\), using the minor. \( C_{ij} = (-1)^{\,i+j}\,M_{ij} \)
Take the transpose of the cofactor matrix to get the adjugate matrix. \( \mathrm{adj}(A) = \mathrm{C}^\mathrm{T} \)
Compute the inverse: \( A^{-1} = \frac{1}{|A|}\,\mathrm{adj}(A) = \frac{1}{|A|}\,\mathrm{C}^\mathrm{T}\)
Equating the terms, we get: \( a_{11}^2 + a_{12}^2 = 1 \) => row 1 is a unit vector \( a_{21}^2 + a_{22}^2 = 1 \) => row 2 is a unit vector \( a_{11}a_{21} + a_{12}a_{22} = 0 \) => row 1 and row 2 are orthogonal to each other, since dot product = 0 \( a_{21}a_{11} + a_{21}a_{12} = 0 \) => row 1 and row 2 are orthogonal to each other, since dot product = 0
Therefore, the rows and columns of an orthogonal matrix are orthonormal.
Why multiplication of a vector with an orthogonal matrix does NOT change its size?
Let, \(\mathbf{Q}\) is an orthogonal matrix, and \(\mathbf{v}\) is a vector. Let’s calculate the length of \( \mathbf{Q} \mathbf{v} \)
\[
\text{ length of } \mathbf{Qv} = \|\mathbf{Qv}\| \\
= (\mathbf{Qv})^T\mathbf{Qv} = \mathbf{v}^T\mathbf{Q}^T\mathbf{Qv} \\
\text{ but } \mathbf{Q}^T\mathbf{Q} = \mathbf{I} \quad \text{ since, Q is orthogonal }\\
= \mathbf{v}^T\mathbf{v} = \|\mathbf{v}\| \quad \text{ = length of vector }\\
\]
Therefore, linear transformation of a vector by an orthogonal matrix does NOT change its length.
Solve the following system of equations: \( 2x + y = 5 \) \( x + 2y = 4 \)
Lets solve the system of equations using matrix: \(\begin{bmatrix}
2 & 1 \\
\\
1 & 2
\end{bmatrix}
\)
\(
\begin{bmatrix}
x \\
\\
y
\end{bmatrix}
= \begin{bmatrix}
5 \\
\\
4
\end{bmatrix}
\)
The above equation can be written as: \(\mathbf{AX} = \mathbf{B} \) => \( \mathbf{X} = \mathbf{A}^{-1} \mathbf{B} \)
Eigen is a German word that means “Characteristic” or “Proper”. It tells us about the characteristic properties of a matrix.
Linear Transformation
A linear transformation defined by a matrix, denoted as \(T(x)=A\mathbf{x}\), is a function that maps a vector \(\mathbf{x}\)
to a new vector by multiplying it by a matrix \(A\). Multiplying a vector by a matrix can change the direction or magnitude or both of the vector.
A special non-zero vector whose direction remains unchanged after transformation by a matrix is applied. It might get scaled up or down but does not change its direction. Result of linear transformation, i.e, multiplying the vector by a matrix, is just a scalar multiple of the original vector.
Eigen Value (\(\lambda\))
It is the scaling factor of the eigen vector, i.e, a scalar multiple \(\lambda\) of the original vector, when the vector
is multiplied by a matrix. \(|\lambda| > 1 \): Vector stretched \(0 < |\lambda| < 1 \): Vector shrunk \(|\lambda| = 1 \): Same size \(\lambda < 0 \): Vector’s direction is reversed
Characteristic Equation
Since, for an eigen vector, result of linear transformation, i.e, multiplying the vector by a matrix,
is just a scalar multiple of the original vector, =>
\(det(\mathbf{A} - \lambda \mathbf{I})) = 0 \), will give us a polynomial equation in \(\lambda\) of degree \(n\), we need to solve this polynomial equation to get the \(n\) eigen values. e.g.:
=> Both the equations will be \(v_1 - v_2 = 0 \), i.e, \(v_1 = v_2\) So, we can choose any vector, where x-axis and y-axis components are same, i.e, \(v_1 = v_2\) => Eigen vector: \(v_1 = \begin{bmatrix} 1 \\ \\ 1 \\ \end{bmatrix}\) Similarly, for \(\lambda_2 = 1\) we will get, eigen vector: \(v_2 = \begin{bmatrix} 1 \\ \\ -1 \\ \end{bmatrix}\)
What are the eigen values and vectors of an identity matrix?
Characteristic equation for identity matrix: \(\mathbf{Iv} = \lambda \mathbf{v}\) Therefore, identity matrix has only one eigen value \(\lambda = 1\), and all non-zero vectors can be eigen vectors.
Are the eigen values of a real matrix always real?
No, eigen values can be complex; if complex, then always occur in conjugate pairs.
e.g: \(\mathbf{A} = \begin{bmatrix}
0 & 1 \\
\\
-1 & 0
\end{bmatrix}
\),
\( \quad det(\mathbf{A} - \lambda \mathbf{I}) = 0 \quad \)
=> det \(\begin{bmatrix}
0-\lambda & 1 \\
\\
-1 & 0-\lambda
\end{bmatrix} = 0
\)
=> \(\lambda^2 + 1 = 0\)
=> \(\lambda = \pm i\) So, eigen values are complex.
=> \((d_{11}-\lambda)(d_{22}-\lambda) \cdots (d_{nn}-\lambda) = 0\) => \(\lambda = d_{11}, d_{22}, \cdots, d_{nn}\) So, eigen values are the diagonal elements of the matrix.
Key Properties of Eigen Values and Eigen Vectors
For a \(n \times n\) matrix, there are \(n\) eigen values.
Eigen values need NOT be unique, e.g, identity matrix has only one eigen value \(\lambda = 1\).
Sum of eigen values = trace of matrix = sum of diagonal elements, i.e, \(tr(\mathbf{A}) = \lambda_1 + \lambda_2 + \cdots + \lambda_n\).
Product of eigen values = determinant of matrix, i.e, \(det(\mathbf{A}) = |\mathbf{A}|= \lambda_1 \lambda_2 \cdots \lambda_n\).
e.g: For the example matrix given above,
Now, how will we calculate higher powers of a matrix i.e \(\mathbf{A}^k\)?
If we follow the above method, then we will have to multiply the matrix \(\mathbf{A}\), \(k\) times, which will
be very time consuming and cumbersome. So, we need to find an easier way to calculate the power of a matrix.
How will we calculate the power of diagonal matrix?
Let’s calculate the 2nd power of a diagonal matrix.
Note that when we square the diagonal matrix, then all the diagonal elements got squared. Similarly, if we want to calculate the kth power of a diagonal matrix, then all we need to do is to just compute the kth
powers of all diagonal elements, instead of complex matrix multiplications. \(\quad \mathbf{A}^k = \begin{bmatrix}
3^k & 0 \\
\\
0 & 2^k
\end{bmatrix}
\)
Therefore, if we diagonalize a square matrix then the computation of power of the matrix will become very easy. Next, let’s see how to diagonalize a matrix.
Eigen Value Decomposition
\(\mathbf{V}\): Matrix of all eigen vectors(as columns) of matrix \(\mathbf{A}\) \( \mathbf{V} = \begin{bmatrix}
\mathbf{v}_1 & \mathbf{v}_2 & \cdots & \mathbf{v}_n \\
\vdots & \vdots & \ddots & \vdots \\
\vdots & \vdots & \vdots & \vdots\\
\end{bmatrix}
\), where, each column is an eigen vector corresponding to an eigen value \(\lambda_i\). If \( \mathbf{v}_1 \mathbf{v}_2 \cdots \mathbf{v}_n \) are linearly independent, then,
\(det(\mathbf{V}) ~⍯ ~ 0\). => \(\mathbf{V}\) is NOT singular and \(\mathbf{V}^{-1}\) exists.
\(\Lambda\): Diagonal matrix of all eigen values of matrix \(\mathbf{A}\) \( \Lambda = \begin{bmatrix}
\lambda_1 & 0 & \cdots & 0 \\
\\
0 & \lambda_2 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & \lambda_n
\end{bmatrix}
\), where, each diagonal element is an eigen value corresponding to an eigen vector \(\mathbf{v}_i\).
Let’s recall the characteristic equation of a matrix for calculating eigen values: \(\mathbf{A} \mathbf{v} = \lambda \mathbf{v}\) Let’s use the consolidated matrix for eigen values and eigen vectors described above: i.e, \(\mathbf{A} \mathbf{V} = \mathbf{\Lambda} \mathbf{V}\) For diagonalisation: => \(\mathbf{\Lambda} = \mathbf{V}^{-1} \mathbf{A} \mathbf{V}\)
We can see that, using the above equation, we can represent the matrix \(\mathbf{A}\) as a
diagonal matrix \(\mathbf{\Lambda}\) using the matrix of eigen vectors \(\mathbf{V}\).
Just reshuffling the above equation will give us the Eigen Value Decomposition of the matrix \(\mathbf{A}\): \(\mathbf{A} = \mathbf{V} \mathbf{\Lambda} \mathbf{V}^{-1}\)
Important: Given that \(\mathbf{V}^{-1}\) exists, i.e, all the eigen vectors are linearly independent.
\( \because \mathbf{A} = \mathbf{V} \mathbf{\Lambda} \mathbf{V}^{-1}\) We know, \( \mathbf{V} ~and~ \mathbf{\Lambda} \), we need to calculate \(\mathbf{V}^{-1}\).
Spectral decomposition is a specific type of eigendecomposition that applies to a symmetric matrix,
requiring its eigenvectors to be orthogonal. In contrast, a general eigendecomposition applies to any diagonalizable matrix and does not require the eigenvectors
to be orthogonal.
The eigen vectors corresponding to distinct eigen values are orthogonal. However, the matrix \(\mathbf{V}\) formed by the eigen vectors as columns is NOT orthogonal,
because the rows/columns are NOT orthonormal i.e unit length. So, in order to make the matrix \(\mathbf{V}\) orthogonal, we need to normalize the rows/columns of the matrix
\(\mathbf{V}\), i.e, make, each eigen vector(column) unit length, by dividing the vector by its magnitude.
After normalisation we get orthogonal matrix \(\mathbf{Q}\) that is composed of unit length and orthogonal eigen vectors
or orthonormal eigen vectors. Since, matrix \(\mathbf{Q}\) is orthogonal, => \(\mathbf{Q}^T = \mathbf{Q}^{-1}\)
The eigen value decomposition of a square matrix is: \(\mathbf{A} = \mathbf{V} \mathbf{\Lambda} \mathbf{V}^{-1}\)
And, the spectral decomposition of a real symmetric matrix is: \(\mathbf{A} = \mathbf{Q} \mathbf{\Lambda} \mathbf{Q}^T\)
Important: Note that, we are discussing only the special case of real symmetric matrix here, because a real symmetric matrix is guaranteed to have all real eigenvalues.
Applications of Eigen Value Decomposition
Principal Component Analysis (PCA): For dimensionality reduction.
Page Rank Algorithm: For finding the importance of a web page.
Structural Engineering: By calculating the eigen values of a bridge’s structural model, we can identify its naturalfrequencies to ensure that the bridge won’t resonate and be damaged by external forces, such as wind, and seismic waves.
In the diagram below, if we need to reduce the dimensionality of the data to 1, which feature should be dropped?
Whenever we want to reduce the dimensionality of the data, we should aim to minimize information loss. Since, information = variance, we should drop the feature that brings least information, i.e, has least variance. Therefore, drop the feature 1.
What if the variance in both directions is same ? What should be done in this case? Check the diagram below.
Here, since the variance in both directions is approximately same, in order to capture maximum variance in data, we will rotate the f1-axis in the direction of maximum spread/variance of data, i.e, f1’-axis and then we can
drop f2’-axis, which is perpendicular to f1’-axis.
Principal Component Analysis (PCA)
It is a dimensionality reduction technique that finds the direction of maximum variance in the data. Note: Some loss of information will always be there in dimensionality reduction, because there will be some variability
in data along the direction that is dropped, and that will be lost.
Goal: Fundamental goal of PCA is to find the new set of orthogonal axes, called the principal components, onto which
the data can be projected, such that, the variance of the projected data is maximum.
Say, we have data, \(D:X \in \mathbb{R}^{n \times d}\), n is the number of samples d is the number of features or dimensions of each data point. In order to find the directions of maximum variance in data, we will use the covariance matrix of data. Covariance matrix (C) summarizes the spread and relationship of the data in the original d-dimensional space. \(C_{d \times d} = \frac{1}{n-1}X^TX \), where \(X\) is the data matrix. Note: (n-1) in the denominator is for unbiased estimation(Bessel’s correction) of covariance matrix. \(C_{ii}\) is the variance of the \(i^{th}\) feature. \(C_{ij}\) is the co-variance between feature \(i\) and feature \(j\). Trace(C) = Sum of diagonal elements of C = Total variance of data.
Algorithm:
Data is first mean centered, i.e, make mean = 0, i.e, subtract mean from each data point. \(X = X - \mu\)
Perform the eigen value decomposition of covariance matrix. \( C = Q \Lambda Q^T \) \(C\): Orthogonal matrix of eigen vectors of covariance matrix. New rotated axes or prinicipal components of the data. \(\Lambda\): Diagonal matrix of eigen values of covariance matrix. Scaling of variance along new eigen basis. Note: Eigen values are sorted in descending order, i.e \( \lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_d \).
Project the data onto the new axes or principal components/directions. Note: k < d = reduced dimensionality. \(X_{new} = Z = XQ_k\) \(X_{new}\): Projected data or principal component score
What is the variance of the projected data?
Variance of projected data is given by the eigen value of the co-variance matrix. Covariance of projected data = \((XQ)^TXQ \)
It decomposes any matrix into a rotation, a scaling (based on singular values), and another rotation. It is a generalization of the eigen value decomposition(for square matrix) to rectangular matrices. Any rectangular matrix can be decomposed into a product of three matrices using SVD, as follows:
\(\mathbf{U}\): Set of orthonormal eigen vectors of \(\mathbf{AA^T}_{m \times m} \) \(\mathbf{V}\): Set of orthonormal eigen vectors of \(\mathbf{A^TA}_{n \times n} \) \(\mathbf{\Sigma}\): Rectangular diagonal matrix, whose diagonal values are called singular values;
square root of non-zeroeigen values of \(\mathbf{AA^T}\).
Note: The number of non-zero diagonal entries in \(\mathbf{\Sigma}\) = rank of matrix \(\mathbf{A}\). Rank (r): Number of linearly independent rows or columns of a matrix.
Singular value decomposition, thus refers to the set of scale factors \(\mathbf{\Sigma}\) that are fundamentally
linked to the matrix’s singularity and rank.
Properties of Singular Values
All singular values are non-negative.
Square roots of the eigen values of the matrix \(\mathbf{AA^T}\) or \(\mathbf{A^TA}\).
Note: If rank of matrix < dimensions, then 1 or more of the singular values are zero, i.e, dimension collapse.
Suppose a satellite takes picture of objects in space and sends them to earth. Size of each picture = 1000x1000 pixels. How can we compress the image size to save satellite bandwidth?
We can perform singular value decomposition on the image matrix and find the minimum number of top ranks required to to successfully reconstruct the original image back. Say we performed the SVD on the image matrix and found that top 20 rank singular values, out of 1000, are sufficient to
tell what the picture is about.
\(\mathbf{A} = \mathbf{U} \mathbf{\Sigma} \mathbf{V}^T \)
\( = u_1 \sigma_1 v_1^T + u_2 \sigma_2 v_2^T + \cdots + u_r \sigma_r v_r^T \), where \(r = 20\) A = sum of ‘r=20’ matrices of rank=1. Now, we need to send only the \(u_i, \sigma_i , v_i\) values for i=20, i.e, top 20 ranks to earth and then do the calculation to reconstruct the approximation of original image. \(\mathbf{u} = \begin{bmatrix} u_1 \\ u_2 \\ \vdots \\ u_{1000} \end{bmatrix}\)
\(\mathbf{v} = \begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_{1000} \end{bmatrix}\)
So, we need to send data corresponding to 20 (rank=1) matrices, i.e, \(u_i, v_i ~and~ \sigma_i\) = (1000 + 1000 + 1)20
= 200020 pixels (approx)
\( \mathbf{u}_i : i^{th}\) column vector of \(\mathbf{U}\) \( \mathbf{v}_i^T : i^{th}\) column vector of \(\mathbf{V}^T\) \( \sigma_i : i^{th}\) singular value, i.e, diagonal entry of \(\mathbf{\Sigma}\)
Since, the singular values are arranged from largest to smallest, i.e, \(\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_r\), The top ranks capture the vast majority of the information or variance in the matrix.
So, in order to get the best rank-k approximation of the matrix,
we simply truncate the summation after the k’th term.
The approximation \(\mathbf{A_k}\) is called the low rank approximation of \(\mathbf{A}\),
which is achieved by keeping only the largest singular values and corresponding vectors.
Applications:
Image compression
Data compression, such as, LoRA (Low Rank Adaptation)
Let \(\mathbf{x} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix}_{\text{n×1}}\) be a vector, i.e, \(\mathbf{x} \in \mathbb{R}^n\).
Let \(f(x)\) be a function that maps a vector to a scalar, i.e, \(f : \mathbb{R}^n \rightarrow \mathbb{R}\). The derivative of function \(f(x)\) with respect to \(\mathbf{x}\) is defined as:
Let’s calculate \(\frac{\partial y}{\partial x_k}\), i.e, for the \(k^{th}\) element and sum it over 1 to n. The \(k^{th}\) element \(x_k\) will appear 2 times in the below summation, i.e, when \(i=k ~and~ j=k\)
Above, we saw the gradient of a scalar valued function, i.e, a function that maps a vector to a scalar, i.e,
\(f : \mathbb{R}^n \rightarrow \mathbb{R}\). There is another kind of function called vector valued function, i.e, a function that maps a vector to another vector, i.e,
\(f : \mathbb{R}^n \rightarrow \mathbb{R}^m\).
The Jacobian is the matrix of all first-order partial derivatives of a vector-valued function,
while the gradient is a vector representing the partial derivatives of a scalar-valued function.
Jacobian matrix provides the best linear approximation of a vector valued function near a given point,
similar to how a derivative/gradient is the best linear approximation for a scalar valued function
Note: Gradient is a special case of the Jacobian;
it is the transpose of the Jacobian for a scalar valued function.
Let, \(f(x)\) be a function that maps a vector to another vector, i.e, \(f : \mathbb{R}^n \rightarrow \mathbb{R}^m\)
The above matrix is called Jacobian matrix of \(f(x)\).
Assumption: All the first order partial derivatives exist.
Hessian Matrix
Hessian Matrix: It is a square matrix of second-order partial derivatives of a scalar-valued function. This is used to characterize the curvature of a function at a give point.
Let, \(f(x)\) be a function that maps a vector to a scalar value, i.e, \(f : \mathbb{R}^n \rightarrow \mathbb{R}\) The Hessian matrix is defined as:
Let f(A) be a function that maps a matrix to a scalar value, i.e, \(f : \mathbb{R}^{m \times n} \rightarrow \mathbb{R}\) , then derivative of function f(A) w.r.t A is defined as:
It is a measure of the size of a vector or distance from the origin. Vector norm is a function that maps a vector to a real number, i.e, \({\| \cdot \|} : \mathbb{R}^n \rightarrow \mathbb{R}\). Vector Norm should satisfy following 3 properties:
Non-Negativity: Norm is always greater than or equal to zero, \( {\| x \|} \ge 0\), and \( {\| x \|} = 0\), if and only if \(\vec{x} = \vec{0}\).
Homogeneity (or Scaling): \( {\| \alpha x \|} = |\alpha| {\| x \|} \).
Triangle Inequality: \( {\| x + y \|} \le {\| x \|} + {\| y \|} \).
P-Norm: It is a generalised form of most common family of vector norms, also called Minkowski norm. It is defined as:
\[ {\| x \|}_p = (\sum_{i=1}^n |x_i|^p)^{1/p} \]
We can change the value of \(p\) to get different norms.
L1 Norm: It is the sum of absolute values of all the elements of a vector; also known as Manhattan distance. p=1:
Let, vector \(\mathbf{x} = \begin{bmatrix} 3 \\ \\ -4 \end{bmatrix}\), then \({\| x \|_1} = |3| + |-4| = 7\) \({\| x \|_2} = \sqrt{3^2 + (-4)^2} = \sqrt{25} = 5\) \({\| x \|_\infty} = max(|3|, |-4|) = max(3, 4) = 4\)
Matrix Norm
It is a function that assigns non-negative size or magnitude to a matrix. Matrix Norm is a function that maps a matrix to a non-negative real number, i.e, \({\| \cdot \|} : \mathbb{R}^{m \times n} \rightarrow \mathbb{R}\) It should satisfy following 3 properties:
Non-Negativity: Norm is always greater than or equal to zero, \( {\| x \|} \ge 0\), and \( {\| x \|} = 0\), if and only if \(\vec{x} = \vec{0}\).
Homogeneity (or Scaling): \( {\| \alpha x \|} = |\alpha| {\| x \|} \).
Triangle Inequality: \( {\| x + y \|} \le {\| x \|} + {\| y \|} \).
There are 2 types of matrix norms:
Element wise norms, e.g,, Frobenius norm
Vector induced norms Frobenius Norm:
Frobenius Norm: It is equivalent to the Euclidean norm of the matrix if it were flattened into a single vector. If A is a matrix of size \(m \times n\), then, Frobenius norm is defined as:
\(\sigma_i\) is the \(i\)th singular value of matrix A.
Vector Induced Norm: It measures the maximum stretching a matrix can apply when multiplied with a vector, where the vector has a unit length under the chosen vector norm.
Matrix Induced by Vector P-Norm: P-Norm:
\[ {\| A \|_p} = \max_{{\| x \|_p} =1} \frac{\| Ax \|_p}{\| x \|_p} \]
P=1 Norm:
\[ {\| A \|_1} = \max_{1 \le j \le n } \sum_{i=1}^m |a_{ij}| =
\text{ max absolute column sum } \]
P=\(\infty\) Norm:
\[ {\| A \|_\infty} = \max_{1 \le i \le m } \sum_{j=1}^n |a_{ij}| =
\text{ max absolute row sum } \]
P=2 Norm: Also called Spectral norm, i.e, maximum factor by which the matrix can stretch a unit vector in Euclidean norm.
\[ {\| A \|_2} = \sigma_{max}(A) =
\text{ max singular value of matrix } \]
Example
Let, matrix \(\mathbf{A} = \begin{bmatrix} a_{11} & a_{12} \\ \\ a_{21} & a_{22} \end{bmatrix}\), then find Frobenius norm.
Let, matrix \(\mathbf{A} = \begin{bmatrix} 1 & -2 & 3 \\ \\ 4 & 5 & -6 \end{bmatrix}\), then
Column 1 absolute value sum = |1|+|4| = 5 Column 2 absolute value sum = |-2|+|5|= 7 Column 3 absolute value sum = |3|+|-6|= 9
Row 1 absolute value sum = |1|+|-2|+|3| = 6 Row 2 absolute value sum = |4|+|5|+|-6| = 15
\({\| A \|_1} = max(5,7,9) = 9\) = max column absolute value sum. \({\| A \|_\infty} = max(6,15) = 15\) = max row absolute value sum.
Let, matrix \(\mathbf{A} = \begin{bmatrix} 2 & 1 \\ \\ 1 & 2 \end{bmatrix}\), then find spectral norm. Spectral norm can be found using the singular value decomposition, in order to get the largest singular value. \({\| A \|_2} = \sigma_{max}(A) \)
By convention, the direction of the hyperplane is given by a unit vector perpendicular to the hyperplane
, i.e, \({\Vert \mathbf{w} \Vert} = 1\), since the direction is only important.
\(w_0\) gives the signed perpendicular distance from the origin. \(w_0 = 0\) => Hyperplane passes through the origin. \(w_0 < 0\) => Hyperplane is in the same direction of unit vector \(\mathbf{\widehat{w}}\) w.r.t the origin. \(w_0 > 0\) => Hyperplane is in the opposite direction of unit vector \(\mathbf{\widehat{w}}\) w.r.t the origin.
Consider a line as a hyperplane in 2D space. Let the unit vector point towards the positive x-axis direction. What is the direction of the hyperplane w.r.t the origin and the direction of the unit vector ?
Equation of a hyperplane is: \(\pi_d = \mathbf{w}^\top \mathbf{x} + w_0 = 0\) Let, the equation of the line/hyperplane in 2D be: \(\pi_d = 1.x + 0.y + w_0 = x + w_0 = 0\)
Case 1: \(w_0 < 0\), say \(w_0 = -5\) Therefore, equation of hyperplane: \( x - 5 = 0 => x = 5\) Here, the hyperplane(line) is located in the same direction as the unit vector w.r.t the origin, i.e, towards the +ve x-axis direction.
Case 2: \(w_0 > 0\), say \(w_0 = 5\) Therefore, equation of hyperplane: \( x + 5 = 0 => x = -5\) Here, the hyperplane(line) is located in the opposite direction as the unit vector w.r.t the origin, i.e, towards the -ve x-axis direction.
Half Spaces
A hyperplane divides a space into 2 distinct parts called half-spaces. e.g.: A 2D hyperplane divided a 3D space into 2 distinct parts. Similar example in real world: A wall divides a room into 2 distinct spaces.
Positive Half-Space: A half space that is in the same direction as the unit vector w.r.t the origin.
Negative Half-Space: A half space that is in the opposite direction as the unit vector w.r.t the origin.
\[
\text { If point 'x' is on the hyperplane, then:} \\[10pt]
\pi_d = \mathbf{w}^\top \mathbf{x} + w_0 = 0 \\[10pt]
\mathbf{w}^\top \mathbf{x_1} + w_0 > 0 ~or~ \mathbf{w}^\top \mathbf{x_1} + w_0 < 0 \quad ? \\[10pt]
\text { Distance of } x_1 < x_1\prime \text{ as } x_1 \text{ is between the origin and the hyperplane
and } x_1\prime \text { lies on the hyperplane } \\[10pt]
=> \tag{1}\Vert \mathbf{x_1} \Vert < \Vert \mathbf{x_1\prime} \Vert
\]\[
\mathbf{w}^\top \mathbf{x_1\prime} + w_0 = 0 \\[10pt]
=> \tag{2} \Vert \mathbf{w} \Vert \Vert \mathbf{x_1\prime} \Vert cos{\theta} + w_0 = 0
\]
Note: The above examples were standard straight forward, where we know a direct formula for finding area under a curve. But, what if we have such a shape, for which, we do NOT know a ready-made formula, then how do we calculate
the area under the curve. Let’s see an example:
Derivative tells us how fast the function is changing at a specific point in relation to another variable.
Note: For a line, the slope is constant, but for a parabola, the slope is changing at every point.
How do we calculate the slope at a given point?
Let AB is a secant on the parabola, i.e, line connecting any 2 points on the curve. Slope of secant = \(tan\theta = \frac{\Delta y}{\Delta x} = \frac{y_2-y_1}{x_2-x_1}\) As \(\Delta x \rightarrow 0\), secant will become a tangent to the curve, i.e, the line will touch the curve only
at 1 point. \(dx = \Delta x \rightarrow 0\) \(x_2 = x_1 + \Delta x \) \(y_2 = f(x_2) = f(x_1 + \Delta x) \) Slope at \(x_1\) =
Now, let’s dive deeper and understand the concepts that required for differentiation, such as, limits, continuity,
differentiability, etc.
Limits
Limit of a function f(x) at any point ‘c’ is the value that f(x) approaches, as x gets very close to ‘c’, but NOT necessarily equal to ‘c’.
One-sided limit: value of the function, as it approaches a point ‘c’ from only one direction, either left or right. Two-sided limit: value of the function, as it approaches a point ‘c’ from both directions, left and right, simultaneously.
e.g.:
\(f(x) = \frac{1}{x}\), find the limit of f(x) at x = 0. Let’s check for one-sided limit at x=0: \[
\lim_{x \rightarrow 0^+} \frac{1}{x} = + \infty \\[10pt]
\lim_{x \rightarrow 0^-} \frac{1}{x} = - \infty \\[10pt]
so, \lim_{x \rightarrow 0^+} \frac{1}{x} ⍯ \lim_{x \rightarrow 0^-} \frac{1}{x} \\[10pt]
=> \text{ limit does NOT exist at } x = 0.
\]
2. \(f(x) = x^2\), find the limit of f(x) at x = 0. Let’s check for one-sided limit at x=0:
3. f(x) = |x|, find the limit of f(x) at x = 0. Let’s check for one-sided limit at x=0:
\[
\lim_{x \rightarrow 0^+} |x| = x = 0 \\[10pt]
\lim_{x \rightarrow 0^-} |x| = -x = 0 \\[10pt]
so, \lim_{x \rightarrow 0^+} |x| = \lim_{x \rightarrow 0^-} |x| \\[10pt]
=> \text{ limit exists at } x = 0.
\]
Continuity
A function f(x) is said to be continuous at a point ‘c’, if its graph can be drawn through that point,
without lifting the pen. Continuity bridges the gap between the function’s value at the given point and the limit.
Conditions for Continuity: A function f(x) is continuous at a point ‘c’, if and only if, all the below 3 conditions are met:
f(x) must be defined at point ‘c’.
Limit of f(x) must exist at point ‘c’, i.e, left and right limits must be equal.
\[ \lim_{x \rightarrow c^+} f(x) = \lim_{x \rightarrow c^-} f(x) \]
Value of f(x) at ‘c’ must be equal to its limit at ‘c’.
\[ \lim_{x \rightarrow c} f(x) = f(c) \]
e.g.:
\(f(x) = \frac{1}{x}\) is NOT continuous at x = 0, since, f(x) is not defined at x = 0.
\(f(x) = |x|\) is continuous everywhere.
\(f(x) = tanx \) is discontinuous at infinite points.
Differentiability
A function is differentiable at a point ‘c’, if derivative of the function exists at that point. A function must be continuous at the given point ‘c’ to be differentiable at that point. Note: A function can be continuous at a given point, but NOT differentiable at that point.
e.g.: We know that \( f(x) = |x| \) is continuous at x=0, but its NOT differentiable at x=0.
\[
f\prime(x) =\lim_{\Delta x \rightarrow 0} \frac{f(x + \Delta x) - f(x)}{\Delta x}
= \lim_{\Delta x \rightarrow 0} \frac{|x + \Delta x| - |x|}{\Delta x} \\[10pt]
\text{ let's calculate the one-sided limit from both left and right sides and check if they are equal: } \\[10pt]
if ~ x>0, \lim_{\Delta x \rightarrow 0^+} \frac{|x + \Delta x| - |x|}{\Delta x}
= \lim_{\Delta x \rightarrow 0+} \frac{\cancel x + \Delta x - \cancel x}{\Delta x} = 1 \\[10pt]
if ~ x<0, \lim_{\Delta x \rightarrow 0^-} \frac{|x + \Delta x| - |x|}{\Delta x}
= \lim_{\Delta x \rightarrow 0^-} \frac{-(x + \Delta x) - (-x)}{\Delta x}
= \lim_{\Delta x \rightarrow 0-} \frac{\cancel {-x} - \Delta x + \cancel x}{\Delta x} = -1 \\[10pt]
=> \text{ left hand limit (-1) ⍯ right hand limit (1) } \\[10pt]
=> f\prime(0) \text{ does NOT exist.}
\]
Critical Point: A point of the function where the derivative is either zero or undefined.
These critical points are candidates for local maxima or minima,
which are the highest and lowest points in a function’s immediate neighborhood, respectively.
Maxima: Highest point w.r.t immediate neighbourhood. f’(x)/gradient/slope changes from +ve to 0 to -ve, therefore, change in f’(x) is -ve. => f’’(x) < 0
Minima: Lowest point w.r.t immediate neighbourhood. f’(x)/gradient/slope changes from -ve to 0 to +ve, therefore, change in f’(x) is +ve. => f’’(x) > 0
Let \(f(x) = 2x^3 + 5x^2 + 3 \), find the maxima and minima of f(x). To find the maxima and minima, lets take the derivative of the function and equate it to zero. \[
f'(x) = 6x^2 + 10x = 0\\[10pt]
=> x(6x+10) = 0 \\[10pt]
=> x = 0 \quad or \quad x = -10/6 = -5/3 \\[10pt]
\text{ lets check the second order derivative to find which point is maxima and minima: } \\[10pt]
f''(x) = 12x + 10 \\[10pt]
=> at ~ x = 0, \quad f''(x) = 12*0 + 10 = 10 >0 \quad => minima \\[10pt]
=> at ~ x = -5/3, \quad f''(x) = 12*(-5/3) + 10 = -20 + 10 = -10<0 \quad => maxima \\[10pt]
\]
\(f(x,y) = z = x^2 + y^2\), find the minima of f(x,y). Since, this is a multi-variable function, we will use vector and matrix for calculation. \[
Gradient = \nabla f_z =
\begin{bmatrix}
\frac{\partial f_z}{\partial x} \\
\\
\frac{\partial f_z}{\partial y}
\end{bmatrix} =
\begin{bmatrix}
2x \\
\\
2y
\end{bmatrix} =
\begin{bmatrix}
0 \\
\\
0
\end{bmatrix} \\[10pt]
=> x=0, y=0 \text{ is a point of optima for } f(x,y)
\]
Partial Derivative: Partial derivative \( \frac{\partial f(x,y)}{\partial x} ~or~ \frac{\partial f(x,y)}{\partial y} \)is the rate of change
or derivative of a multi-variable function w.r.t one of its variables,
while all the other variables are held constant.
Let’s continue solving the above problem, and calculate the Hessian, i.e, 2nd order derivative of f(x,y):
Whenever we build a Machine Learning model, we try to make sure that the model makes least mistakes in its predictions. How do we measure and minimize these mistakes in predictions made by the model?
To measure, how wrong the are the predictions made by a Machine Learning model, every model is formulated as minimizing a loss function.
Loss Function
Loss Function: It quantifies error of a single data point in a dataset. e.g.: Squared Loss, Hinge Loss, Absolute Loss, etc, for a single data point.
Cost Function: It is the average of all losses over the entire dataset. e.g.: Mean Squared Error(MSE), Mean Absolute Error(MAE), etc.
Objective Function: It is the over-arching objective of an optimization problem, representing the function that is minimized or maximized. e.g.: Minimize MSE.
Let’s understant this through an example: Task: Predict the price of a company’s stock based on its historical data.
Objective Function: Minimize the difference between actual and predicted price. Let, \(y\): original or actual price \(\hat y\): predicted price
Say, the dataset has ’n’ such data points. Loss Function: loss = \( y - \hat y \) for a single data point. We want to minimize the loss for all ’n’ data points.
Cost Function: We want to minimize the average/total loss over all ’n’ data points. So, what are the ways ?
We take a simple sum of all the losses, but this can be misleading, as loss for a single data point can be +ve or -ve, we can get a net-zero loss even for very large losses, when we sum them all.
We take the sum of absolute value of each loss, i.e, \( |y - \hat y| \), this way the losses will not cancel out each other. But the absolute value function is NOT differentiable at y=0, and this can cause issues in optimisation algorithms,
such as, gradient descent. Read more about Differentiability
So, we choose squared loss, i.e, \( (y - \hat y)^2 \), this solves the above issues.
Note: In general, we refer to the cost function as the loss function also, the terms are used interchangeably.
Cost = Loss = Mean Squared Error(MSE)
\[\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat y_i)^2 \]
The task is to minimize the above loss.
Key Points:
Loss is the bridge between ‘data’ and ‘optimization’.
Good loss functions are differentiable and convex.
Convexity: It refers to a property of a function where a line segment connecting any two points on its graph
lies above or on the graph itself. A convex function is curved upwards. It is always described by a convex set.
Convex Set: A convex set is a set of points in which the straight line segment connecting any two points in the set lies
entirely within that set. A set \(C\) is convex if for any two points \(x\) and \(y\) in \(C\), the convex combination \(\theta x+(1-\theta )y\) is also in \(C\) for all values of \(\theta \) where \(0\le \theta \le 1\).
A function \(f: \mathbb{R}^n \rightarrow \mathbb{R}\) is convex if for all values of \(x,y\) and \(0\le \theta \le 1\),
Second-Order Test: If a function is twice differentiable, i.e, 2nd derivative exists, then the function is convex,
if and only if, the Hessian is positive semi-definite for all points in its domain.
All machine learning algorithms minimize loss (mostly), so we need to find the optimum parameters for the model that
minimizes the loss. This is an optimization problem, i.e, find the best solution from a set of alternatives. Note: Convexity ensures that there is only 1 minima for the loss function.
Optimization: It is the iterative procedure of finding the optimum parameter \(x^*\) that minimizes the loss function f(x).
\[
x^* = \underset{x}{\mathrm{argmin}}\ f(x)
\]
Let’s formulate an optimization problem for a model to minimize the MSE loss function discussed above:
\[
Loss = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat y_i)^2 \\[10pt]
\text { We need to find the weights } w, w_0 \text{ of the model that minimize our MSE loss: } \\[10pt]
\underset{w, w_0}{\mathrm{argmin}}\ \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat y_i)^2
\]
Note: To minimize the loss, we want \(y_i, \hat y_i\) to be as close as possible,
for that we want to find the optimum weights \(w, w_0\) of the model.
Important: Deep Learning models have non-convex loss function, so it is challenging to reach the global minima,
so any local minima is also a good enough solution.
Constrained Optimization: It is an optimization process to find the best possible solution (min or max), but within a set of limitations or
restrictions called constraints. Constraints limit the range of acceptable values; they can be equality constraints or inequality constraints. e.g.: Minimize f(x) subject to following constraints: Equality Constraints: \( g_i(x) = c_i \forall ~i \in \{1,2,3, \ldots, n\} \) Inequality Constraints: \( h_j(x) \le d_j \forall ~j \in \{1,2,3, \ldots, m\}\)
Lagrangian Method: Lagrangian method converts a constrained optimization problem to an unconstrained optimization problem,
by introducing a new variable called Lagrange multiplier (\(\lambda\)).
Note: Addition of Lagrangian function that incorporates the constraints,
makes the problem solvable using standard calculus.
e.g.: Let f(x) be the objective function with single equality constraint \(g(x) = c\), then the Lagrangian function \( \mathcal{L}\) is defined as:
By solving the above unconstrained optimization problem,
we get the optimum solution for the original constrained problem.
Find the point on the line 2x + 3y = 13 that is closest to the origin.
Objective: To minimize the distance between point (x,y) on the line 2x + 3y = 13 and the origin (0,0). distance, d = \(\sqrt{(x-0)^2 + (y-0)^2}\) => Objective function = minimize distance = \( \underset{x^*, y^*}{\mathrm{argmin}}\ f(x,y) =
\underset{x^*, y^*}{\mathrm{argmin}}\ x^2+y^2\) Constraint: Point (x,y) must be on the line 2x + 3y = 13. => Constraint (equality) function = \(g(x,y) = 2x + 3y - 13 = 0\) Lagragian function =
To solve the optimization problem, there are many methods, such as, analytical method, which gives the normal equation for the linear regression,
but we will discuss that method later in detail, when we have understood what is linear regression?
Normal Equation for linear regression:
\[
w^* = (X^TX)^{-1}X^Ty
\]
X: Feature variables y: Vector of all observed target values
Till now, we have understood how to formulate a minimization problem as a mathematical optimization problem. Now, lets take a step forward and understand how to solve these optimization problems.
We will focus on two important iterative gradient based methods:
Gradient Descent: First order method, uses only the gradient.
Newton’s Method: Second order method, used both the gradient and the Hessian.
Gradient Descent: It is a first order iterative optimization algorithm that is used to find the local minimum of a differentiable function. It iteratively adjusts the parameters of the model in the direction opposite to the gradient of cost function,
since moving opposite to the direction of gradient leads towards the minima.
Algorithm:
Initialize the weights/parameters with random values.
Calculate the gradient of the cost function at current parameter values.
Update the parameters using the gradient.
\[
w_{new} = w_{old} - \eta \cdot \frac{\partial f}{\partial w_{old}} \\[10pt]
\eta: \text{ learning rate or step size to take for each parameter update}
\]
Repeat steps 2 and 3 iteratively until convergence (to minima).
Types of Gradient Descent
There are 3 types of Gradient Descent:
Batch Gradient Descent
Stochastic Gradient Descent
Mini-Batch Gradient Descent
Batch Gradient Descent (BGD): Computes the gradient using all the data points in the dataset for parameter update in each iteration. Say, number of data points in the dataset is \(n\). Let, the loss function for individual data point be \(l_i(w)\)
Not suitable for large datasets; impractical for Deep Learning, as n = millions/billions.
Stochastic Gradient Descent (SGD): It uses only 1 data point selected randomly from dataset to compute gradient for parameter update in each iteration.
\[
\frac{\partial L}{\partial w} \approx \frac{\partial l_i}{\partial w}, \text { say i = 5} \\[10pt]
w_{new} = w_{old} - \eta \cdot (\text{gradient of i-th data point})
\]
Key Points:
Computationally fastest per step; TC = O(1).
Highly noisy, zig-zag path to minima.
High variance in gradient estimation makes path to minima volatile, requiring a careful decay of learning rate
\(\eta\) to ensure convergence to minima.
Mini Batch Gradient Descent (MBGD): It uses small randomly selected subsets of dataset, called mini-batch, (1<k<n) to compute gradient for
parameter update in each iteration.
\[
\frac{\partial L}{\partial w} = \frac{1}{n} \sum_{i=1}^{k} \frac{\partial l_i}{\partial w} , \text { say k = 32} \\[10pt]
w_{new} = w_{old} - \eta \cdot (\text{average gradient of k data points})
\]
Key Points:
Moderate time consumption per step; TC = O(k<n).
Less noisy, and more reliable convergence than stochastic gradient descent.
More efficient and faster than batch gradient descent.
Standard optimization algorithm for Deep Learning. Note: Vectorization on GPUs allows for parallel processing of mini-batches;
also GPUs are the reason for the mini-batch size to be a power of 2.
Newton’s Method: It is a second-order iterative gradient based optimization technique known for its extremely fast convergence. When close to optimum, it achieves quadratic convergence, better than gradient descent’s linear convergence.
Algorithm:
Start at a random point \(x_k\).
Compute the slope at \(x_k, ~i.e,~ f'(x_k)\).
Compute the curvature at \(x_k, ~i.e,~ f''(x_k)\).
Draw a parabola at \(x_k\) that locally approximates the function.
Jump directly to the minimum of that parabola; that’s the next step.
Note: So, instead of walking down the slope step by step (gradient descent), we are jumping straight to the point
where the curve bends downwards towards the bottom.
\[
x_{k+1} = x_k - \frac{f\prime(x_k)}{f\prime\prime(x_k)} \\[10pt]
\text{ step size = } \frac{1}{f\prime\prime(x_k)} \\[10pt]
f\prime\prime(x_k) : \text{ tells curvature of the function at } x_k \\[10pt]
x_{new} = x_{old} - (\nabla^2 f(x_{old})^{-1} \nabla f(x_{old}) \\[10pt]
\nabla^2 f(x_{old}): Hessian
\]
Example
Find the minima of \(f(x) = x^2 - 4x + 5\)
To find the minima, lets calulate the first derivative and equate to zero. \(f'(x) = 2x - 4 = 0 \) \( => x^* = 2 \)
\(f''(x) = 2 >0 \) => minima is at \(x^* = 2\)
Now, we will solve this using Newton’s Method. Let’s start at x = 0.
Hence, we can see that using Newton’s Method we can get to the minima \(x^* = 2\) in just 1 step.
Limitations
Full Newton’s Method is rarely used in Machine Learning/Deep Learning optimization,
because of the following limitations:
\(TC = O(n^2\)) for Hessian calculation, since for a network with \(n\) parameters requires \(n^2\) derivative calculations.
\(TC = O(n^3\)) for Hessian Inverse calculation.
If it encounters a Saddle point, then it can go to a maxima rather than minima.
Because of the above limitations, we use Quasi-Newton methods like BFGS and L-BFGS. The quasi-Newton methods make use of approximations for Hessian calculation, in order to gain the benefits
of curvature without incurring the cost of Hessian calculation.