This is the multi-page printable view of this section. Click here to print.
Calculus
1 - Calculus Fundamentals
Integration is a mathematical tool that is used to find the area under a curve.
Let’s understand integration with the help of few simple examples for finding area under a curve:
- Area of a triangle:
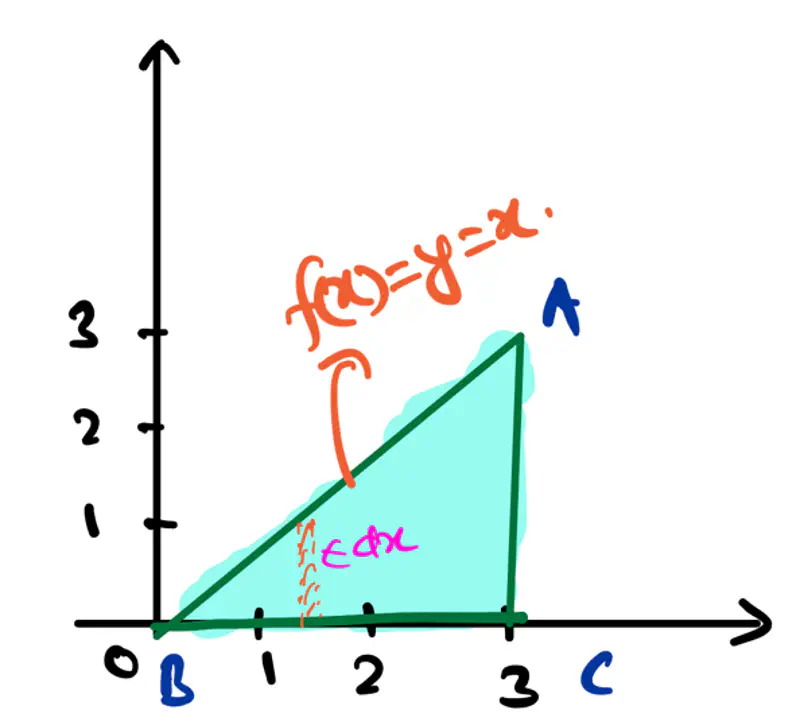
- Area of a rectangle:
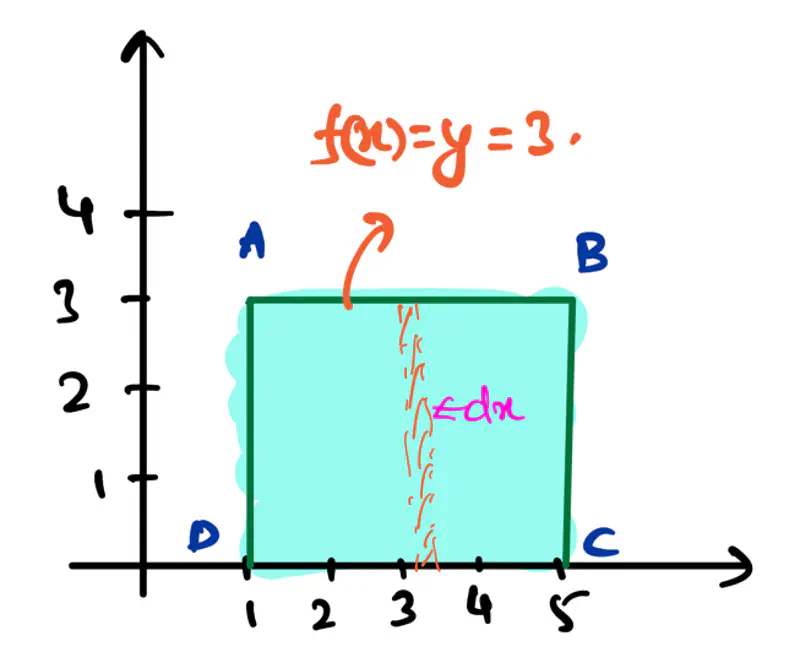
Note: The above examples were standard straight forward, where we know a direct formula for finding area under a curve.
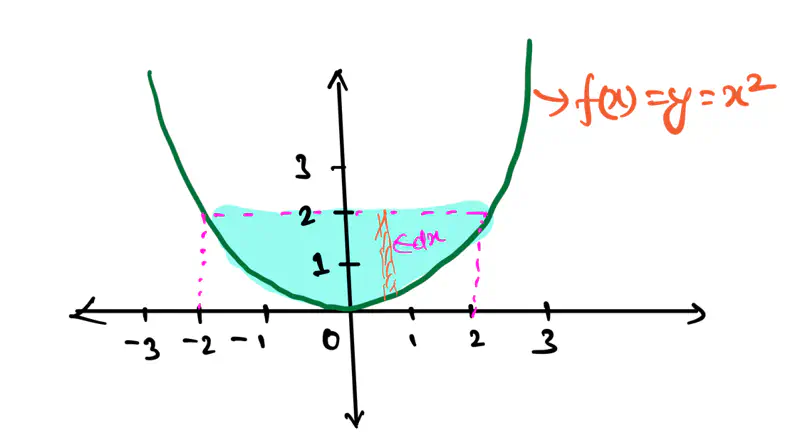
But, what if we have such a shape, for which, we do NOT know a ready-made formula, then how do we calculate
the area under the curve.
Let’s see an example:
3. Area of a part of parabola:
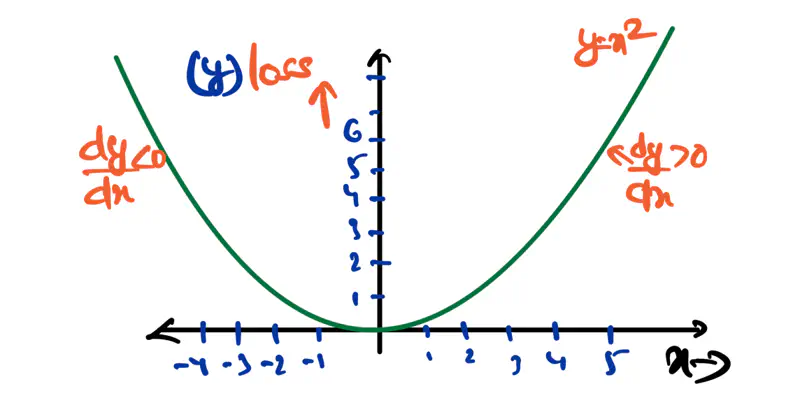
Differentiation is a mathematical tool that is used to find the derivative or rate of change of a function
at a specific point.
- \(\frac{dy}{dx} = f\prime(x) = tan\theta\) = Derivative = Slope = Gradient
- Derivative tells us how fast the function is changing at a specific point in relation to another variable.
Note: For a line, the slope is constant, but for a parabola, the slope is changing at every point.
How do we calculate the slope at a given point?
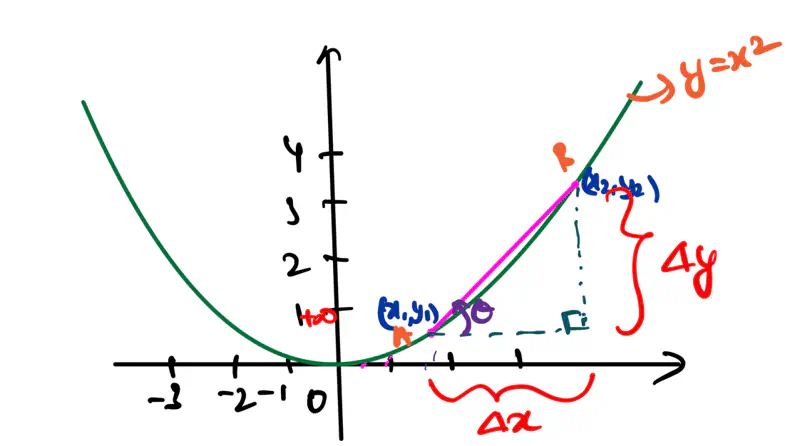
Let AB is a secant on the parabola, i.e, line connecting any 2 points on the curve.
Slope of secant = \(tan\theta = \frac{\Delta y}{\Delta x} = \frac{y_2-y_1}{x_2-x_1}\)
As \(\Delta x \rightarrow 0\), secant will become a tangent to the curve, i.e, the line will touch the curve only
at 1 point.
\(dx = \Delta x \rightarrow 0\)
\(x_2 = x_1 + \Delta x \)
\(y_2 = f(x_2) = f(x_1 + \Delta x) \)
Slope at \(x_1\) =
e.g.:
\( y = f(x) = x^2\), find the derivative of f(x) w.r.t x.
We will understand few important rules of differentiation that are most frequently used in Machine Learning.
Sum Rule:
\[ \frac{d}{dx} (f(x) + g(x)) = \frac{d}{dx} f(x) + \frac{d}{dx} g(x) = f\prime(x) + g\prime(x) \]Product Rule:
\[ \frac{d}{dx} (f(x).g(x)) = \frac{d}{dx} f(x).g(x) + f(x).\frac{d}{dx} g(x) = f\prime(x).g(x) + f(x).g\prime(x) \]e.g.:
\[ h(x) = f(x).g(x) \\[10pt] => h\prime(x) = f\prime(x).g(x) + f(x).g\prime(x) \\[10pt] => h\prime(x) = 2x.sin(x) + x^2.cos(x) \\[10pt] \]
\( h(x) = x^2 sin(x) \), find the derivative of h(x) w.r.t x.
Let, \(f(x) = x^2 , g(x) = sin(x)\).Quotient Rule:
\[ \frac{d}{dx} \frac{f(x)}{g(x)} = \frac{f\prime(x).g(x) - f(x).g\prime(x)}{(g(x))^2} \]e.g.:
\[ h(x) = \frac{f(x)}{g(x)} \\[10pt] => h\prime(x) = \frac{f\prime(x).g(x) - f(x).g\prime(x)}{(g(x))^2} \\[10pt] => h\prime(x) = \frac{cos(x).x - sin(x)}{x^2} \\[10pt] \]
\( h(x) = sin(x)/x \), find the derivative of h(x) w.r.t x.
Let, \(f(x) = sin(x) , g(x) = x\).Chain Rule:
\[ \frac{d}{dx} (f(g(x))) = f\prime(g(x)).g\prime(x) \]e.g.:
\[ h(x) = log(u) \\[10pt] => h\prime(x) = \frac{d h(x)}{du} \cdot \frac{du}{dx} \\[10pt] => h\prime(x) = \frac{1}{u} \cdot 2x = \frac{2x}{x^2} \\[10pt] => h\prime(x) = \frac{2}{x} \]
\( h(x) = log(x^2) \), find the derivative of h(x) w.r.t x.
Let, \( u = x^2 \)
Now, let’s dive deeper and understand the concepts that required for differentiation, such as, limits, continuity, differentiability, etc.
Limit of a function f(x) at any point ‘c’ is the value that f(x) approaches, as x gets very close to ‘c’,
but NOT necessarily equal to ‘c’.
One-sided limit: value of the function, as it approaches a point ‘c’ from only one direction, either left or right.
Two-sided limit: value of the function, as it approaches a point ‘c’ from both directions, left and right, simultaneously.
e.g.:
- \(f(x) = \frac{1}{x}\), find the limit of f(x) at x = 0.
Let’s check for one-sided limit at x=0:
\[ \lim_{x \rightarrow 0^+} \frac{1}{x} = + \infty \\[10pt] \lim_{x \rightarrow 0^-} \frac{1}{x} = - \infty \\[10pt] so, \lim_{x \rightarrow 0^+} \frac{1}{x} ⍯ \lim_{x \rightarrow 0^-} \frac{1}{x} \\[10pt] => \text{ limit does NOT exist at } x = 0. \]
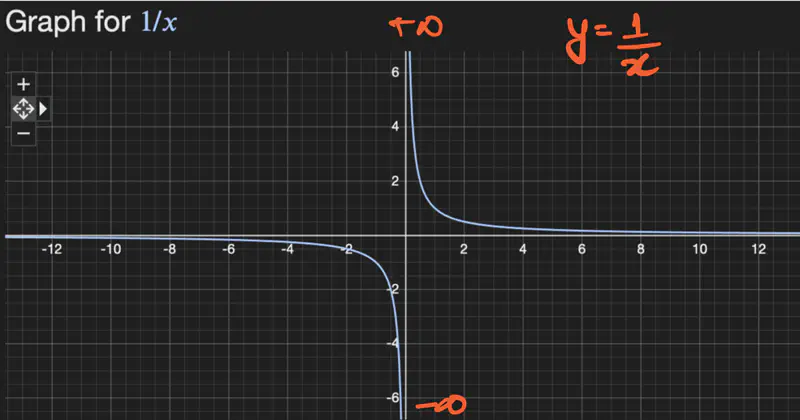
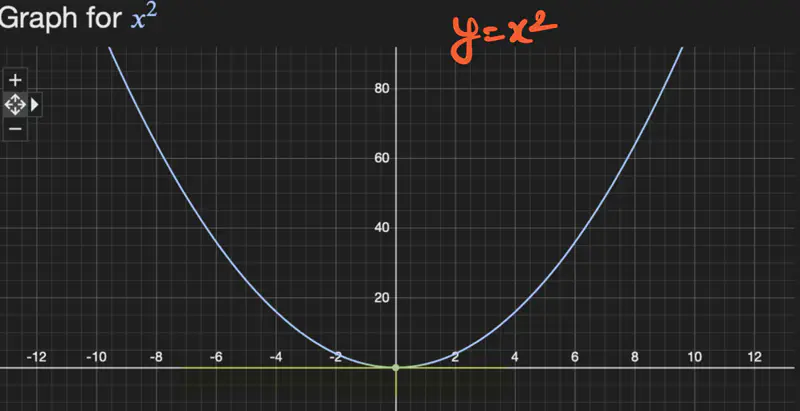
2. \(f(x) = x^2\), find the limit of f(x) at x = 0.
Let’s check for one-sided limit at x=0:
Note: Two-Sided Limit
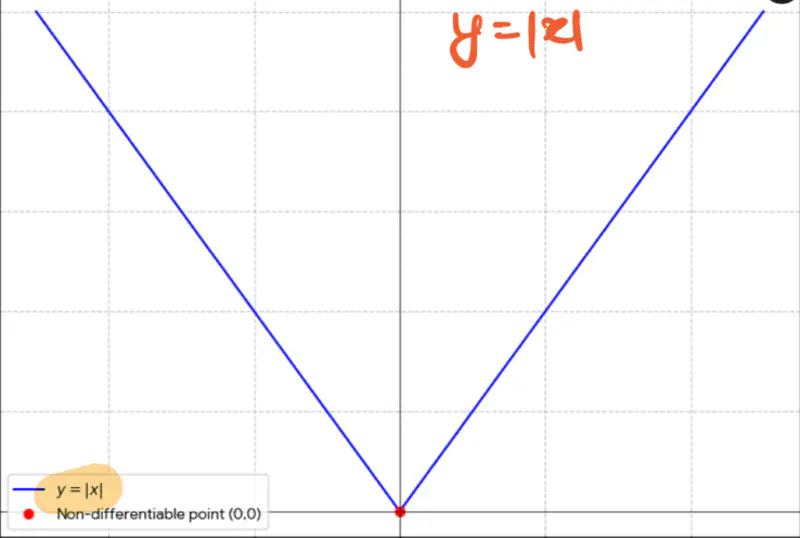
3. f(x) = |x|, find the limit of f(x) at x = 0.
Let’s check for one-sided limit at x=0:
A function f(x) is said to be continuous at a point ‘c’, if its graph can be drawn through that point,
without lifting the pen.
Continuity bridges the gap between the function’s value at the given point and the limit.
Conditions for Continuity:
A function f(x) is continuous at a point ‘c’, if and only if, all the below 3 conditions are met:
- f(x) must be defined at point ‘c’.
- Limit of f(x) must exist at point ‘c’, i.e, left and right limits must be equal. \[ \lim_{x \rightarrow c^+} f(x) = \lim_{x \rightarrow c^-} f(x) \]
- Value of f(x) at ‘c’ must be equal to its limit at ‘c’. \[ \lim_{x \rightarrow c} f(x) = f(c) \]
e.g.:
- \(f(x) = \frac{1}{x}\) is NOT continuous at x = 0, since, f(x) is not defined at x = 0.
- \(f(x) = |x|\) is continuous everywhere.
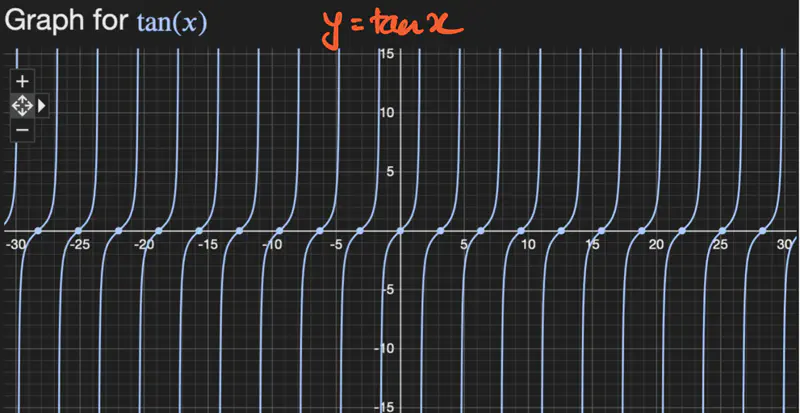
- \(f(x) = tanx \) is discontinuous at infinite points.
A function is differentiable at a point ‘c’, if derivative of the function exists at that point.
A function must be continuous at the given point ‘c’ to be differentiable at that point.
Note: A function can be continuous at a given point, but NOT differentiable at that point.
e.g.:
We know that \( f(x) = |x| \) is continuous at x=0, but its NOT differentiable at x=0.
Critical Point:
A point of the function where the derivative is either zero or undefined.
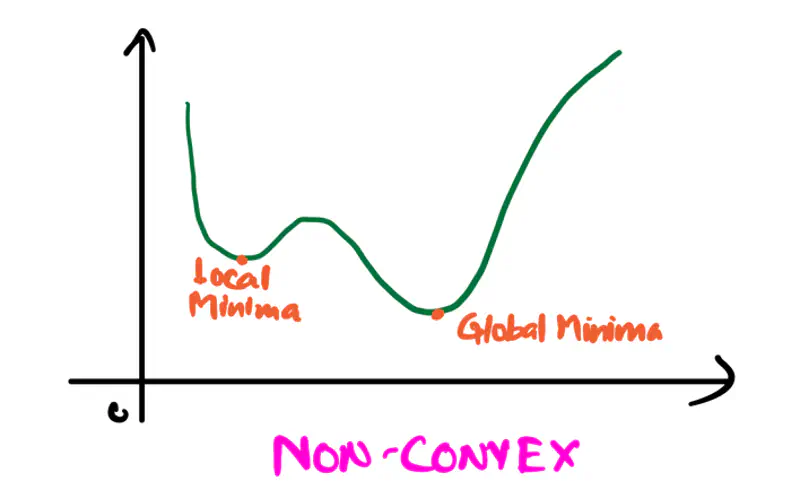
These critical points are candidates for local maxima or minima,
which are the highest and lowest points in a function’s immediate neighborhood, respectively.
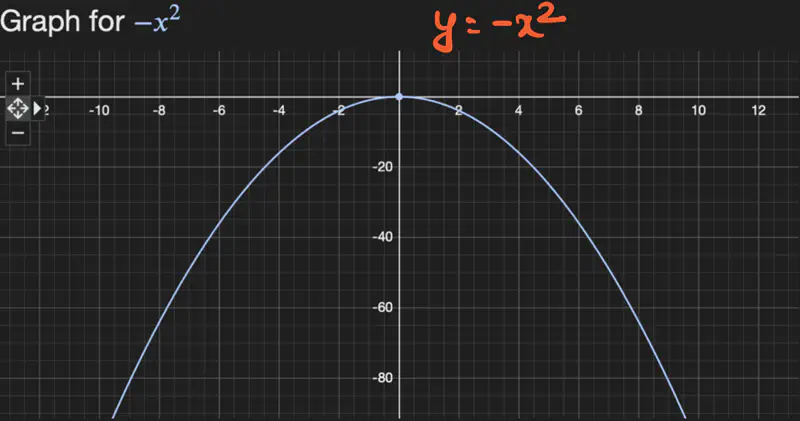
Maxima:
Highest point w.r.t immediate neighbourhood.
f’(x)/gradient/slope changes from +ve to 0 to -ve, therefore, change in f’(x) is -ve.
=> f’’(x) < 0
Let, \(f(x) = -x^2; \quad f'(x) = -2x; \quad f''(x) = -2 < 0 => maxima\)
| x | f’(x) |
|---|---|
| -1 | 2 |
| 0 | 0 |
| 1 | -2 |
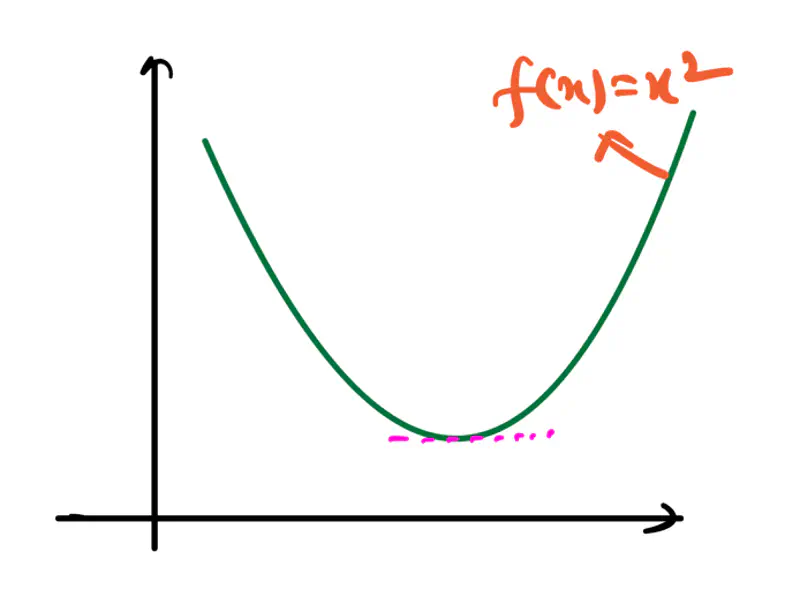
Minima:
Lowest point w.r.t immediate neighbourhood.
f’(x)/gradient/slope changes from -ve to 0 to +ve, therefore, change in f’(x) is +ve.
=> f’’(x) > 0
Let, \(f(x) = x^2; \quad f'(x) = 2x; \quad f''(x) = 2 > 0 => minima\)
| x | f’(x) |
|---|---|
| -1 | -2 |
| 0 | 0 |
| 1 | 2 |
e.g.:
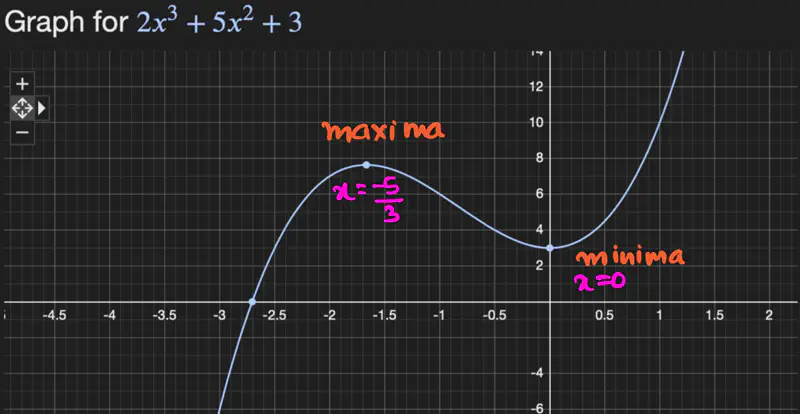
- Let \(f(x) = 2x^3 + 5x^2 + 3 \), find the maxima and minima of f(x).
To find the maxima and minima, lets take the derivative of the function and equate it to zero.
\[ f'(x) = 6x^2 + 10x = 0\\[10pt] => x(6x+10) = 0 \\[10pt] => x = 0 \quad or \quad x = -10/6 = -5/3 \\[10pt] \text{ lets check the second order derivative to find which point is maxima and minima: } \\[10pt] f''(x) = 12x + 10 \\[10pt] => at ~ x = 0, \quad f''(x) = 12*0 + 10 = 10 >0 \quad => minima \\[10pt] => at ~ x = -5/3, \quad f''(x) = 12*(-5/3) + 10 = -20 + 10 = -10<0 \quad => maxima \\[10pt] \]
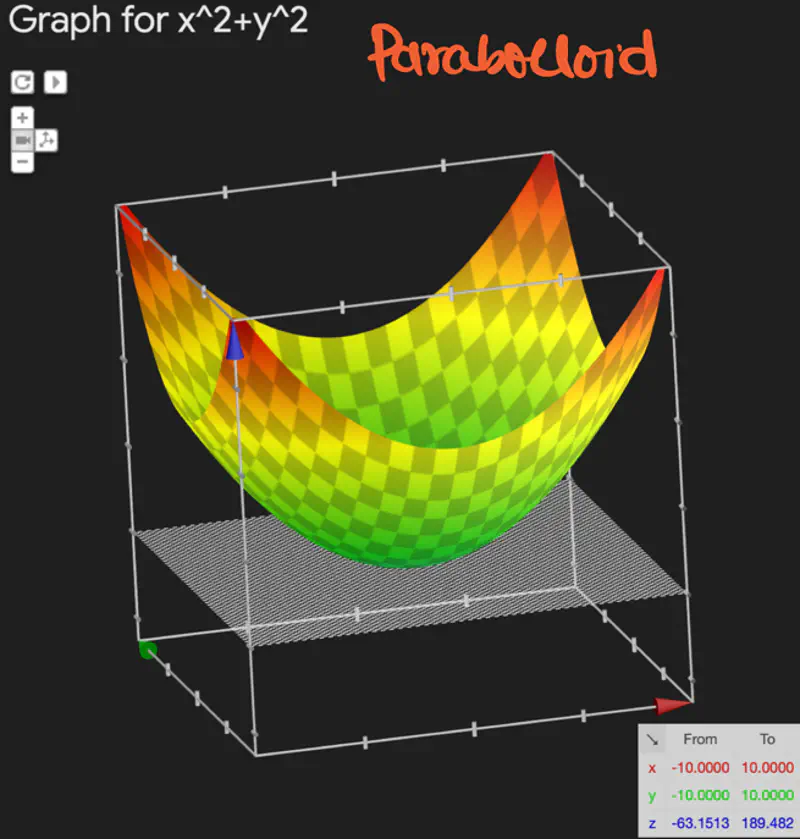
- \(f(x,y) = z = x^2 + y^2\), find the minima of f(x,y).
Since, this is a multi-variable function, we will use vector and matrix for calculation.
\[ Gradient = \nabla f_z = \begin{bmatrix} \frac{\partial f_z}{\partial x} \\ \\ \frac{\partial f_z}{\partial y} \end{bmatrix} = \begin{bmatrix} 2x \\ \\ 2y \end{bmatrix} = \begin{bmatrix} 0 \\ \\ 0 \end{bmatrix} \\[10pt] => x=0, y=0 \text{ is a point of optima for } f(x,y) \]
Partial Derivative:
Partial derivative \( \frac{\partial f(x,y)}{\partial x} ~or~ \frac{\partial f(x,y)}{\partial y} \)is the rate of change
or derivative of a multi-variable function w.r.t one of its variables,
while all the other variables are held constant.
Let’s continue solving the above problem, and calculate the Hessian, i.e, 2nd order derivative of f(x,y):
Since, determinant of Hessian = 4 > 0 and \( \frac{\partial^2 f_z}{\partial x^2} > 0\) => (x=0, y=0) is a point of minima.
Hessian Interpretation:
- Minima: If det(Hessian) > 0 and \( \frac{\partial^2 f(x,y)}{\partial x^2} > 0\)
- Maxima: If det(Hessian) > 0 and \( \frac{\partial^2 f(x,y)}{\partial x^2} < 0\)
- Saddle Point: If det(Hessian) < 0
- Inconclusive: If det(Hessian) = 0, need to perform other tests.
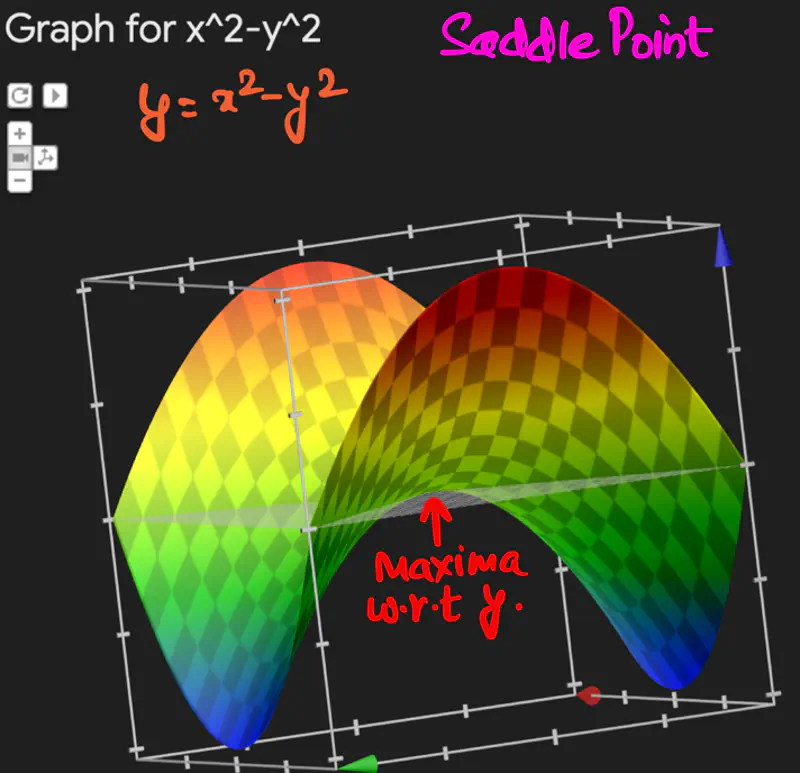
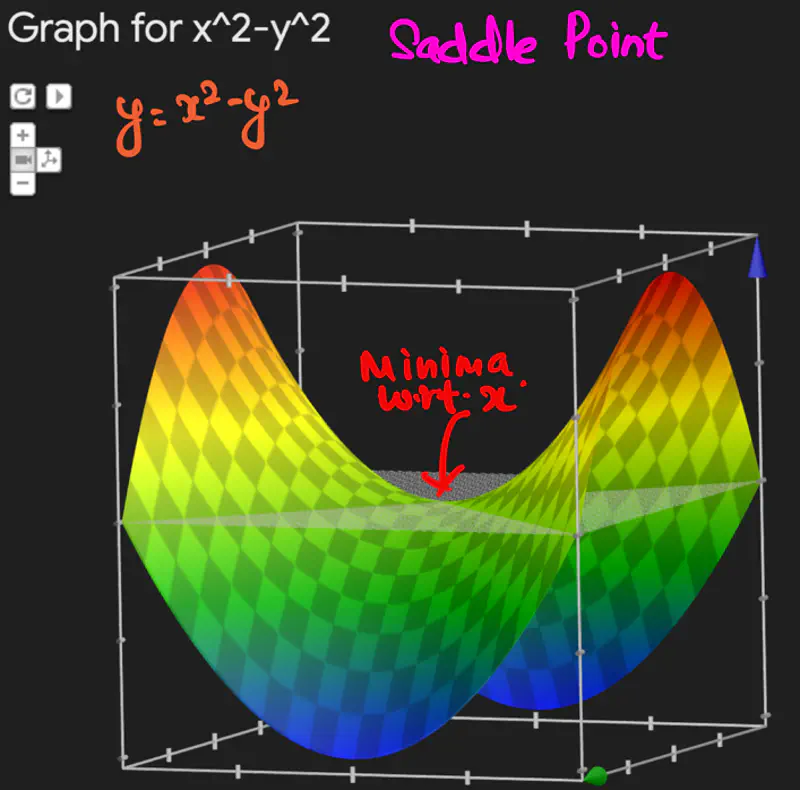
Saddle Point is a critical point where the function is maximum w.r.t one variable,
and minimum w.r.t to another.
e.g.:
Let, \(f(x,y) = z = x^2 - y^2\), find the point of optima for f(x,y).
Since, determinant of Hessian = -4 < 0 => (x=0, y=0) is a saddle point.
End of Section
2 - Optimization
How do we measure and minimize these mistakes in predictions made by the model?
minimizing a loss function.
Loss Function:
It quantifies error of a single data point in a dataset.
e.g.: Squared Loss, Hinge Loss, Absolute Loss, etc, for a single data point.
Cost Function:
It is the average of all losses over the entire dataset.
e.g.: Mean Squared Error(MSE), Mean Absolute Error(MAE), etc.
Objective Function:
It is the over-arching objective of an optimization problem, representing the function that is minimized or maximized.
e.g.: Minimize MSE.
Let’s understant this through an example:
Task:
Predict the price of a company’s stock based on its historical data.
Objective Function:
Minimize the difference between actual and predicted price.
Let, \(y\): original or actual price
\(\hat y\): predicted price
Say, the dataset has ’n’ such data points.
Loss Function:
loss = \( y - \hat y \) for a single data point.
We want to minimize the loss for all ’n’ data points.
Cost Function:
We want to minimize the average/total loss over all ’n’ data points.
So, what are the ways ?
- We take a simple sum of all the losses, but this can be misleading, as loss for a
single data point can be +ve or -ve, we can get a net-zero loss even for very large losses, when we sum them all. - We take the sum of absolute value of each loss, i.e, \( |y - \hat y| \), this way the losses will not cancel out each other.
But the absolute value function is NOT differentiable at y=0, and this can cause issues in optimisation algorithms, such as, gradient descent.
Read more about Differentiability - So, we choose squared loss, i.e, \( (y - \hat y)^2 \), this solves the above issues.
Note: In general, we refer to the cost function as the loss function also, the terms are used interchangeably.
Cost = Loss = Mean Squared Error(MSE) \[\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat y_i)^2 \] The task is to minimize the above loss.
Key Points:
- Loss is the bridge between ‘data’ and ‘optimization’.
- Good loss functions are differentiable and convex.
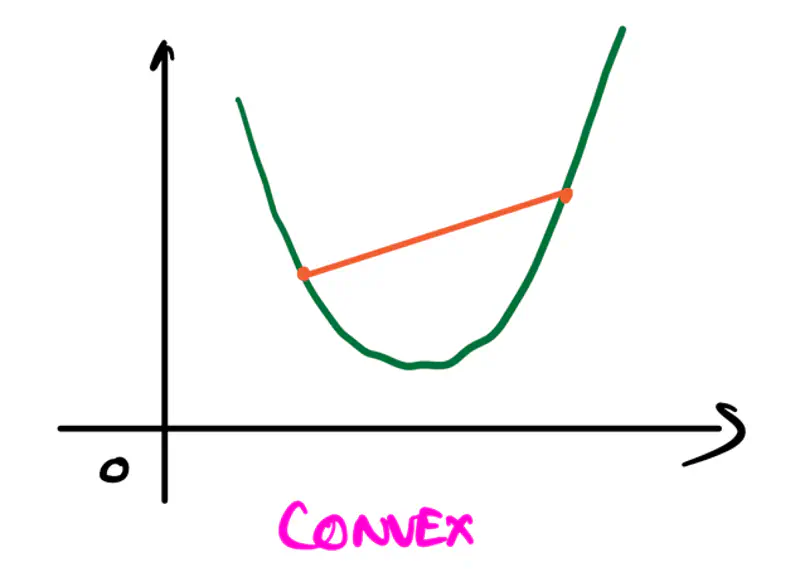
Convexity:
It refers to a property of a function where a line segment connecting any two points on its graph
lies above or on the graph itself.
A convex function is curved upwards.
It is always described by a convex set.
Convex Set:
A convex set is a set of points in which the straight line segment connecting any two points in the set lies
entirely within that set.
A set \(C\) is convex if for any two points \(x\) and \(y\) in \(C\), the convex combination
\(\theta x+(1-\theta )y\) is also in \(C\) for all values of \(\theta \) where \(0\le \theta \le 1\).
A function \(f: \mathbb{R}^n \rightarrow \mathbb{R}\) is convex if for all values of \(x,y\) and \(0\le \theta \le 1\),
\[ f(\theta x + (1-\theta )y) \le \theta f(x) + (1-\theta )f(y) \]Second-Order Test:
If a function is twice differentiable, i.e, 2nd derivative exists, then the function is convex,
if and only if, the Hessian is positive semi-definite for all points in its domain.
Positive Definite:
A symmetric matrix is positive definite if and only if:
- Eigenvalues are all strictly positive, or
- For any non-zero vector \(z\), the quadratic form \(z^THz > 0\)
Note: If the Hessian is positive definite, then the function is convex; has upward curvature in all directions.
Positive Semi-Definite:
A symmetric matrix is positive semi-definite if and only if:
- Eigenvalues are all non-negative (i.e, greater than or equal to zero), or
- For any non-zero vector \(z\), the quadratic form \(z^THz \ge 0\)
Note: If the Hessian is positive definite, then the function is not strictly convex, but flat in some directions.
All machine learning algorithms minimize loss (mostly), so we need to find the optimum parameters for the model that
minimizes the loss.
This is an optimization problem, i.e, find the best solution from a set of alternatives.
Note: Convexity ensures that there is only 1 minima for the loss function.
Optimization:
It is the iterative procedure of finding the optimum parameter \(x^*\) that minimizes the loss function f(x).
Let’s formulate an optimization problem for a model to minimize the MSE loss function discussed above:
Note: To minimize the loss, we want \(y_i, \hat y_i\) to be as close as possible, for that we want to find the optimum weights \(w, w_0\) of the model.
Important:
Deep Learning models have non-convex loss function, so it is challenging to reach the global minima,
so any local minima is also a good enough solution.
Read more about Maxima-Minima
Constrained Optimization:
It is an optimization process to find the best possible solution (min or max), but within a set of limitations or
restrictions called constraints.
Constraints limit the range of acceptable values; they can be equality constraints or inequality constraints.
e.g.:
Minimize f(x) subject to following constraints:
Equality Constraints: \( g_i(x) = c_i \forall ~i \in \{1,2,3, \ldots, n\} \)
Inequality Constraints: \( h_j(x) \le d_j \forall ~j \in \{1,2,3, \ldots, m\}\)
Lagrangian Method:
Lagrangian method converts a constrained optimization problem to an unconstrained optimization problem,
by introducing a new variable called Lagrange multiplier (\(\lambda\)).
Note: Addition of Lagrangian function that incorporates the constraints,
makes the problem solvable using standard calculus.
e.g.:
Let f(x) be the objective function with single equality constraint \(g(x) = c\),
then the Lagrangian function \( \mathcal{L}\) is defined as:
Now, the above constrained optimization problem becomes an unconstrained optimization problem:
By solving the above unconstrained optimization problem,
we get the optimum solution for the original constrained problem.
Objective: To minimize the distance between point (x,y) on the line 2x + 3y = 13 and the origin (0,0).
distance, d = \(\sqrt{(x-0)^2 + (y-0)^2}\)
=> Objective function = minimize distance = \( \underset{x^*, y^*}{\mathrm{argmin}}\ f(x,y) =
\underset{x^*, y^*}{\mathrm{argmin}}\ x^2+y^2\)
Constraint: Point (x,y) must be on the line 2x + 3y = 13.
=> Constraint (equality) function = \(g(x,y) = 2x + 3y - 13 = 0\)
Lagragian function =
To find the optimum solution, we solve the below unconstrained optimization problem.
Take the derivative and equate it to zero.
Since, it is multi-variable function, we take the partial derivatives, w.r.t, x, y and \(\lambda\).
Now, we have 3 variables and 3 equations (1), (2) and (3), lets solve them.
Hence, the point (x=2, y=3) on the line 2x + 3y = 13 that is closest to the origin.
To solve the optimization problem, there are many methods, such as, analytical method, which gives the normal equation for the linear regression,
but we will discuss that method later in detail, when we have understood what is linear regression?
Normal Equation for linear regression:
X: Feature variables
y: Vector of all observed target values
End of Section
3 - Gradient Descent
Till now, we have understood how to formulate a minimization problem as a mathematical optimization problem.
Now, lets take a step forward and understand how to solve these optimization problems.
We will focus on two important iterative gradient based methods:
- Gradient Descent: First order method, uses only the gradient.
- Newton’s Method: Second order method, used both the gradient and the Hessian.
Gradient Descent:
It is a first order iterative optimization algorithm that is used to find the local minimum of a differentiable function.
It iteratively adjusts the parameters of the model in the direction opposite to the gradient of cost function,
since moving opposite to the direction of gradient leads towards the minima.
Algorithm:
Initialize the weights/parameters with random values.
Calculate the gradient of the cost function at current parameter values.
Update the parameters using the gradient.
\[ w_{new} = w_{old} - \eta \cdot \frac{\partial f}{\partial w_{old}} \\[10pt] \eta: \text{ learning rate or step size to take for each parameter update} \]Repeat steps 2 and 3 iteratively until convergence (to minima).
There are 3 types of Gradient Descent:
- Batch Gradient Descent
- Stochastic Gradient Descent
- Mini-Batch Gradient Descent
Batch Gradient Descent (BGD):
Computes the gradient using all the data points in the dataset for parameter update in each iteration.
Say, number of data points in the dataset is \(n\).
Let, the loss function for individual data point be \(l_i(w)\)
Key Points:
- Slow steps towards convergence, i.e, TC = O(n).
- Smooth, direct path towards minima.
- Number of steps/iterations is minimum.
- Not suitable for large datasets; impractical for Deep Learning, as n = millions/billions.
Stochastic Gradient Descent (SGD):
It uses only 1 data point selected randomly from dataset to compute gradient for parameter update in each iteration.
Key Points:
- Computationally fastest per step; TC = O(1).
- Highly noisy, zig-zag path to minima.
- High variance in gradient estimation makes path to minima volatile, requiring a careful decay of learning rate \(\eta\) to ensure convergence to minima.
Mini Batch Gradient Descent (MBGD):
It uses small randomly selected subsets of dataset, called mini-batch, (1<k<n) to compute gradient for
parameter update in each iteration.
Key Points:
- Moderate time consumption per step; TC = O(k<n).
- Less noisy, and more reliable convergence than stochastic gradient descent.
- More efficient and faster than batch gradient descent.
- Standard optimization algorithm for Deep Learning.
Note: Vectorization on GPUs allows for parallel processing of mini-batches; also GPUs are the reason for the mini-batch size to be a power of 2.
End of Section
4 - Newton's Method
Newton’s Method:
It is a second-order iterative gradient based optimization technique known for its extremely fast convergence.
When close to optimum, it achieves quadratic convergence, better than gradient descent’s linear convergence.
Algorithm:
- Start at a random point \(x_k\).
- Compute the slope at \(x_k, ~i.e,~ f'(x_k)\).
- Compute the curvature at \(x_k, ~i.e,~ f''(x_k)\).
- Draw a parabola at \(x_k\) that locally approximates the function.
- Jump directly to the minimum of that parabola; that’s the next step. Note: So, instead of walking down the slope step by step (gradient descent), we are jumping straight to the point where the curve bends downwards towards the bottom.
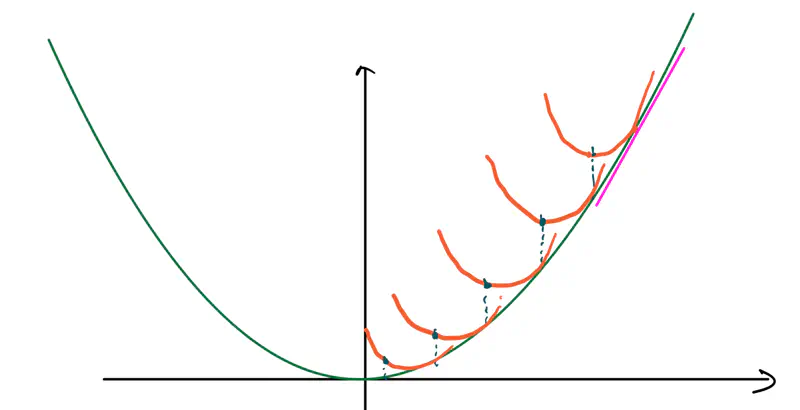
- Find the minima of \(f(x) = x^2 - 4x + 5\)
To find the minima, lets calulate the first derivative and equate to zero.
\(f'(x) = 2x - 4 = 0 \)
\( => x^* = 2 \)
\(f''(x) = 2 >0 \) => minima is at \(x^* = 2\)
Now, we will solve this using Newton’s Method.
Let’s start at x = 0.
Hence, we can see that using Newton’s Method we can get to the minima \(x^* = 2\) in just 1 step.
Full Newton’s Method is rarely used in Machine Learning/Deep Learning optimization,
because of the following limitations:
- \(TC = O(n^2\)) for Hessian calculation, since for a network with \(n\) parameters
requires \(n^2\) derivative calculations. - \(TC = O(n^3\)) for Hessian Inverse calculation.
- If it encounters a Saddle point, then it can go to a maxima rather than minima.
Because of the above limitations, we use Quasi-Newton methods like BFGS and L-BFGS.
The quasi-Newton methods make use of approximations for Hessian calculation, in order to gain the benefits
of curvature without incurring the cost of Hessian calculation.
BFGS: Broyden-Fletcher-Goldfarb-Shanno
L-BFGS: Limited-memory BFGS
End of Section