Back Propagation
4 minute read
Model Training
Training a model means updating the weights, i.e, repeatedly calculating \(\frac{\partial{J(w)}}{\partial{w_{old}}}\).
🎯 Goal: Minimize the cost function J(w).
We use gradient descent to find the optimum weights.
Gradient Descent
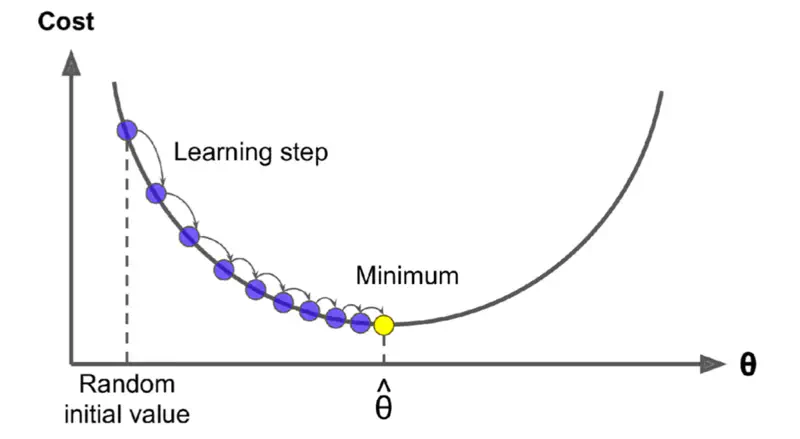
Read more about Gradient Descent
Problem
Weights in the early layers do not touch the final output directly, where the loss/cost is calculated.
Weights are ‘buried’ behind multiple layers of non-linear transformations (like ReLU or Sigmoid).
So, how do we calculate the gradient to update the weights in first layer when the actual error information is only available at the output layer at the end.
💡 For propagating the gradient, we can use something called chain rule of differentiation.
Chain Rule
Chain rule tells us how derivatives propagate through intermediate variables.
Let’s understand chain rule using a simple gear analogy.
Say we have 3 gears connected together of different radii, \(r_1\) = 1 unit, \(r_2\) = 2 units and \(r_3\) = 6 units.
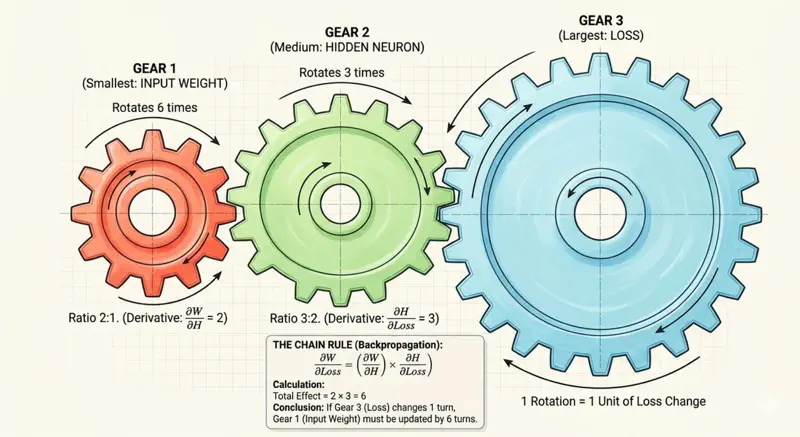
So, if the largest gear(far right) rotates 1 time, then the other smaller gears connected to it will also rotate, but since their radii is less, they will need to rotate more times to cover the same distance.
Distance covered by the largest gear in 1 rotation = \(2 \pi r_3\) = \(2 \times \pi \times 6\) = \(12 \pi\)
So, number of rotation required by middle gear \(r_2\) to cover the same distance
= \(\frac{12 \pi}{2 \pi r_2}\) = \(\frac{12 \pi}{2 \times \pi \times 2}\) = 3
Therefore, the middle gear will need to make 3 rotations if largest gear makes 1 rotation, and similarly the smallest gear(far left) will need to make 6 rotations.
So, when we see in terms of rate of change = rotations per unit time, and if we know the relation between the radii of adjacent gears, then we can propagate the rate of change from right to left.
Thus, the gradient in a deep neural network also flows back in a similar fashion from output (right) to the first layer (left).
So, we can have multiple such gears connected in a complex manner, and we just need to know the relation of a gear’s radius to the adjacent gears,
and that information is sufficient to calculate how many times that gear needs to rotate if the gear on the far right rotated once.
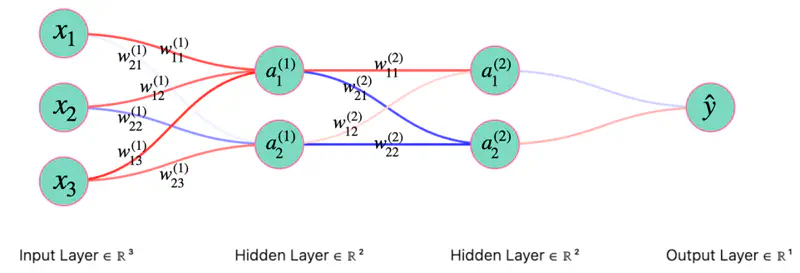
Now, lets apply this chain rule concept and understand the back propagation through a fully connected neural network.
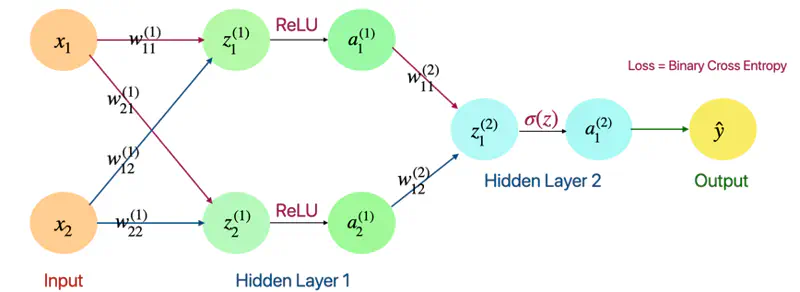
Forward Pass
Layer 1
- \(z_1^{(1)} = w_{11}^{(1)}x_1 + w_{12}^{(1)}x_2\)
- \(z_2^{(1)} = w_{21}^{(1)}x_1 + w_{22}^{(1)}x_2\)
- \(a_1^{(1)} = ReLU(z_{1}^{(1)})\)
- \(a_2^{(1)} = ReLU(z_{2}^{(1)})\)
Layer 2
- \(z_1^{(2)} = w_{11}^{(2)}a_1^{(1)} + w_{12}^{(2)}a_2^{(1)}\)
- \(a_1^{(2)} = \sigma(z_{1}^{(2)})\)
- \(\hat{y} = a_1^{(2)} = \sigma(z_{1}^{(2)})\)
Now, let’s go from right to left, calculating gradient at each point and propagating it back, using chain rule.
Back Propagation
Derivative of Loss w.r.t Output(\(\hat{y}\))
- Loss = Binary Cross Entropy
\[ \mathcal{L} = -[ylog(\hat{y}) + (1-y)log(1-\hat{y})] \] \[ \begin{align*} \frac{\partial{\mathcal{L}}}{\partial{\hat{y}}} &= - [\frac{y}{\hat{y}} - \frac{1-y}{1-\hat{y}}] \\ &= -[\frac{y- \cancel{y\hat{y}} -\hat{y} + \cancel{y\hat{y}}}{\hat{y}(1-\hat{y})}] \\ \therefore \frac{\partial{\mathcal{L}}}{\partial{\hat{y}}} &= \frac{\hat{y} - y}{\hat{y}(1-\hat{y})} \end{align*} \]
Derivative of Loss w.r.t \(\text{z}_1^{(2)}\)
\[ \begin{align*} \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}} &= \frac{\partial{\mathcal{L}}} {\partial{\hat{y}}}. \frac{\partial{\hat{y}}}{\partial{z_1^{(2)}}} \quad \text{also, } \hat{y} = a_1^{(2)} = \sigma(z_{1}^{(2)})\\ \end{align*} \]\[ \text{we know that: } \frac{\partial{\mathcal{L}}}{\partial{\hat{y}}} = \frac{\hat{y} - y}{\hat{y}(1-\hat{y})} \quad \text{so, we need to find: } \frac{\partial{\hat{y}}}{\partial{z_1^{(2)}}} = ? \]\[\text{so, } \frac{\partial{\hat{y}}}{\partial{z_1^{(2)}}} = \frac{\partial{\sigma(z_{1}^{(2)})}}{\partial{z_{1}^{(2)}}} \]\[\because \frac{\partial{\sigma(z)}}{\partial{z}} = \sigma(z).(1-\sigma(z))\]\[ \implies \frac{\partial{\hat{y}}}{\partial{z_1^{(2)}}} = \hat{y}(1-\hat{y})\]\[\frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}} = \frac{\partial{\mathcal{L}}} {\partial{\hat{y}}}. \frac{\partial{\hat{y}}}{\partial{z_1^{(2)}}} = \frac{\hat{y} - y}{\cancel{\hat{y}(1-\hat{y})}}.\cancel{\hat{y}(1-\hat{y})}\]\[\therefore \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}} = \hat{y} - y\]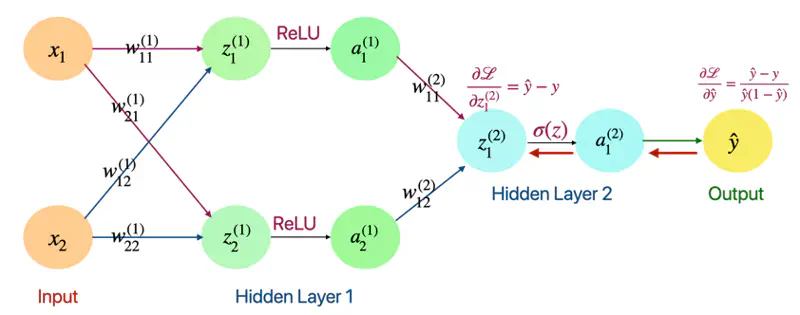
Derivative of Loss w.r.t \(\text{w}_{11}^{(2)}\) and \(a_1^{(1)}\)
\[ \begin{align*} \frac{\partial{\mathcal{L}}}{\partial{w_{11}^{(2)}}} = \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}}. \frac{\partial{z_1^{(2)}}}{\partial{w_{11}^{(2)}}} \end{align*} \]\[\text{we know that: } \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}} = \hat{y} - y \quad \text{so, we need to find: } \frac{\partial{z_1^{(2)}}}{\partial{w_{11}^{(2)}}} = ?\]\[\because z_1^{(2)} = w_{11}^{(2)}a_1^{(1)} + w_{12}^{(2)}a_2^{(1)}\]\[\implies \frac{\partial{z_1^{(2)}}}{\partial{w_{11}^{(2)}}} = a_1^{(1)} \quad \text{and } \frac{\partial{z_1^{(2)}}}{\partial{a_1^{(1)}}} = w_{11}^{(2)}\]\[ \begin{align*} \therefore \frac{\partial{\mathcal{L}}}{\partial{w_{11}^{(2)}}} = \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}}. \frac{\partial{z_1^{(2)}}}{\partial{w_{11}^{(2)}}} = (\hat{y} - y).a_1^{(1)} \end{align*} \]\[ \begin{align*} \text{ Similarly, } \frac{\partial{\mathcal{L}}}{\partial{a_1^{(1)}}} = \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}}. \frac{\partial{z_1^{(2)}}}{\partial{a_1^{(1)}}} = (\hat{y} - y).w_{11}^{(2)} \end{align*} \]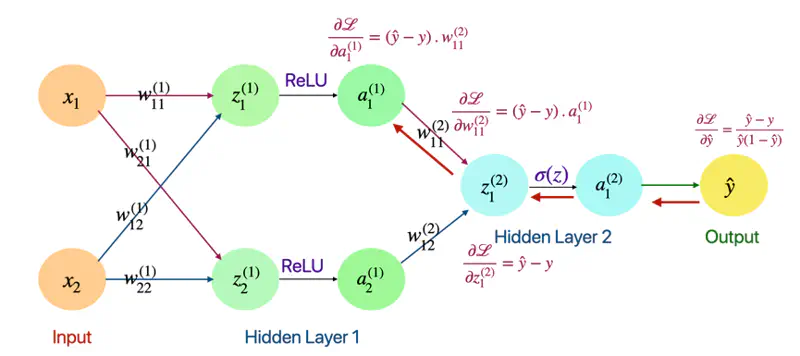
Derivative of Loss w.r.t \(\text{z}_1^{(1)}\)
\[ \begin{align*} \frac{\partial{\mathcal{L}}}{\partial{z_1^{(1)}}} = \frac{\partial{\mathcal{L}}}{\partial{a_1^{(1)}}}. \frac{\partial{a_1^{(1)}}}{\partial{z_1^{(1)}}} \end{align*} \]\[\text{we know that: } \frac{\partial{\mathcal{L}}}{\partial{a_1^{(1)}}} = (\hat{y} - y).w_{11}^{(2)} \quad \text{so, we need to find: } \frac{\partial{a_1^{(1)}}}{\partial{z_1^{(1)}}}= ?\]\[\because a_1^{(1)} = ReLU(z_{1}^{(1)})\]\[\implies \frac{\partial{a_1^{(1)}}}{\partial{z_1^{(1)}}} = \frac{\partial{ReLU(z_{1}^{(1)})}}{\partial{z_1^{(1)}}} = ReLU'(z_{1}^{(1)})\]\[ \begin{align*} \therefore \frac{\partial{\mathcal{L}}}{\partial{z_1^{(1)}}} = \frac{\partial{\mathcal{L}}}{\partial{a_1^{(1)}}}. \frac{\partial{a_1^{(1)}}}{\partial{z_1^{(1)}}} = (\hat{y} - y).w_{11}^{(2)}.ReLU'(z_{1}^{(1)}) \end{align*} \]Derivative of Loss w.r.t \(\text{w}_{11}^{(1)}\)
\[ \begin{align*} \frac{\partial{\mathcal{L}}}{\partial{w_{11}^{(1)}}} = \frac{\partial{\mathcal{L}}}{\partial{z_1^{(1)}}}. \frac{\partial{z_1^{(1)}}}{\partial{w_{11}^{(1)}}} \end{align*} \]\[\text{we know that: } \frac{\partial{\mathcal{L}}}{\partial{z_1^{(2)}}} = (\hat{y} - y).w_{11}^{(2)}.ReLU'(z_{1}^{(1)}) \quad \text{so, we need to find: } \frac{\partial{z_1^{(1)}}}{\partial{w_{11}^{(1)}}} = ?\]\[\because z_1^{(1)} = w_{11}^{(1)}x_1 + w_{12}^{(1)}x_2\]\[\implies \frac{\partial{z_1^{(1)}}}{\partial{w_{11}^{(1)}}} = x_1\]\[\therefore \frac{\partial{\mathcal{L}}}{\partial{w_{11}^{(1)}}} = \frac{\partial{\mathcal{L}}}{\partial{z_1^{(1)}}}. \frac{\partial{z_1^{(1)}}}{\partial{w_{11}^{(1)}}} = (\hat{y} - y).w_{11}^{(2)}.ReLU'(z_{1}^{(1)}).x_1\]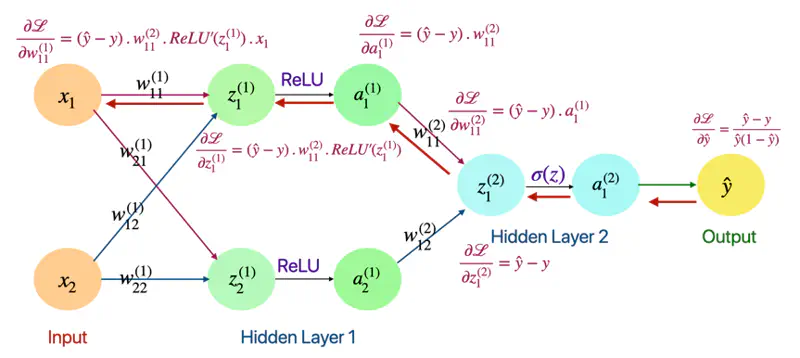
You've worked through all 7 lessons in this module.