Activation Function
3 minute read
Real-world data (images, speech, text, financial trends) is rarely linear.
Non-linearity allows the network to learn and represent complex mappings between inputs and outputs.
- It enables the network to become a ‘Universal Function Approximator’.
A neural network with following properties can approximate any continuous function.
- at least one hidden layer
- nonlinear activation
🎯 This theorem is the mathematical reason - why neural networks are so powerful.
A deep neural network without any non-linear activation collapses into a single linear layer.
Say, if, f(x) = ax and g(x) = bx,
then, g(f(x)) = g(ax) = (ba)x = cx
where, c = ba (another constant)
Effectively, both the linear functions g(f(x)) can be represented by another single linear function h(x).
❌ So depth becomes useless.
- Sigmoid
- Tanh (Hyperbolic Tangent)
- ReLU (Rectified Linear Unit)
- Leaky ReLU
- Softmax
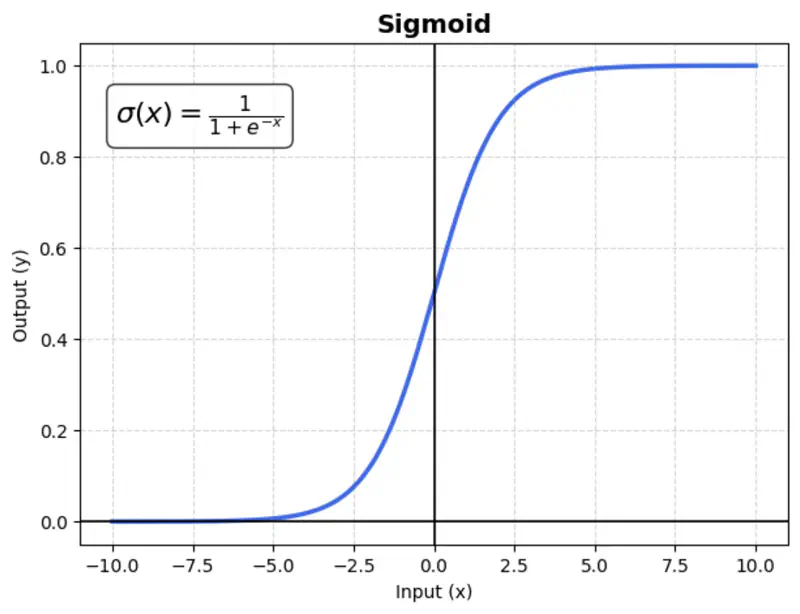
A mathematical function with a characteristic “S”-shaped curve (sigmoid curve) that maps any real-valued number into a range between 0 and 1.
\[\sigma(x) = \frac{1}{1 + e^{-x}}\]Usage:
Mostly used in binary classification output layers.
Issue:
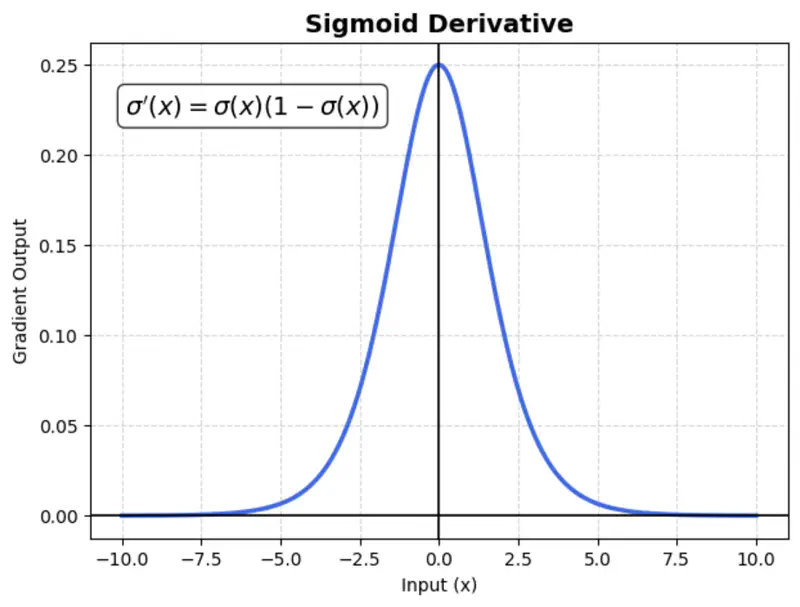
Suffers from vanishing gradient (gradients become near-zero for high or low input values), which slows down training.
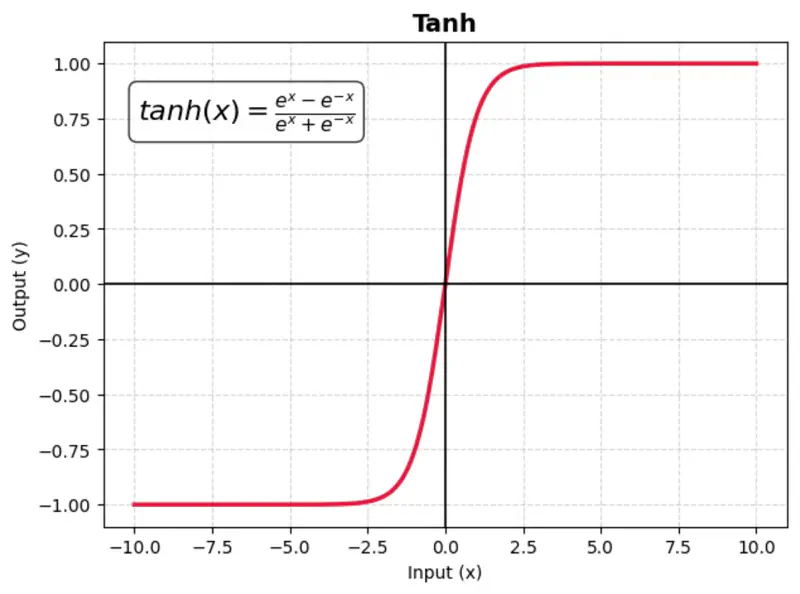
A mathematical function with a S-shaped curve that maps any real-valued number into a range between -1 and 1.
It is zero-centered, making it more effective than the sigmoid function for hidden layers in neural networks.
Benefit:
Makes optimization faster as the data is zero-centered.
Issue:
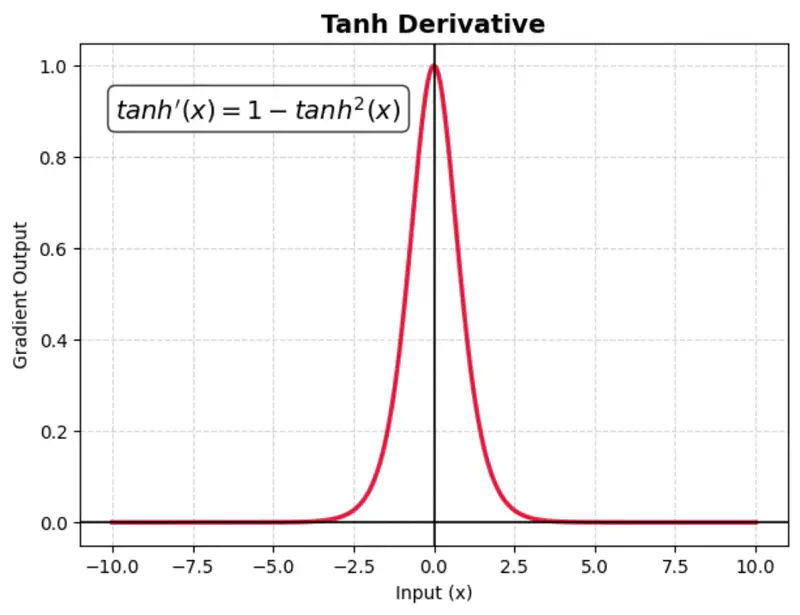
TanH also suffers from vanishing gradient (gradients become near-zero for high or low input values), which slows down training.
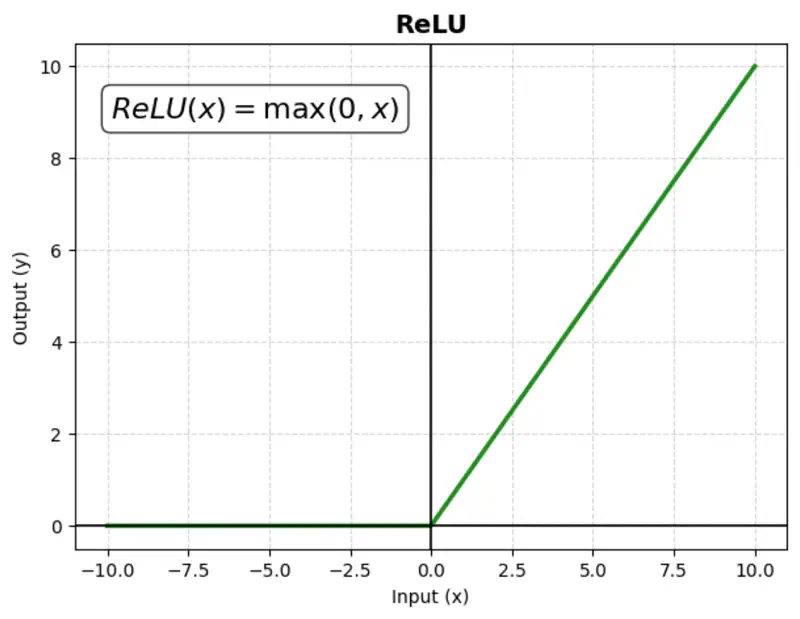
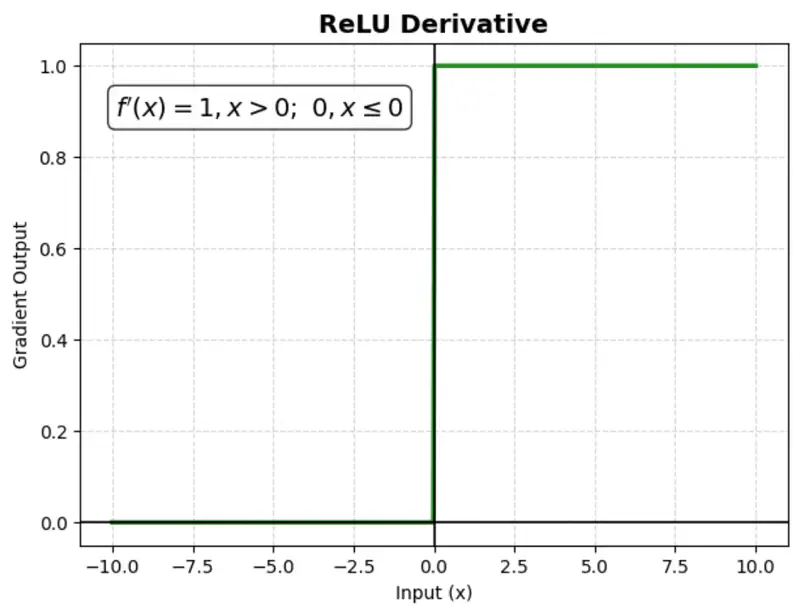
A mathematical function that outputs the input value directly if it is positive, and zero otherwise.
Computationally simple; very fast to compute; does not saturate in the positive direction.
Benefit:
It is computationally efficient and helps mitigate the ‘vanishing gradient’ problem, making it the most popular choice for hidden layers.
Issue:
‘Dying ReLU’ problem: negative inputs result in a zero gradient, meaning the neuron stops learning (no weight updates).
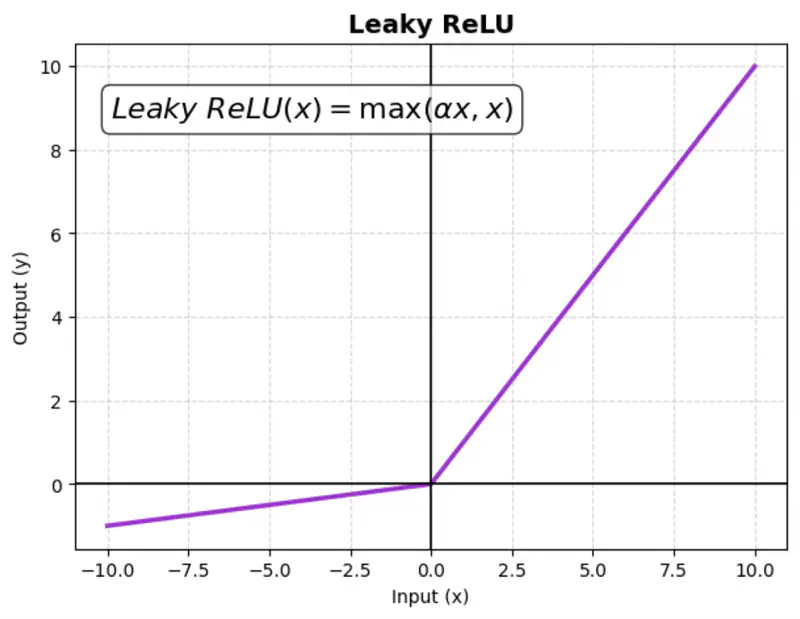
Instead of setting negative input values to zero like a standard ReLU, Leaky ReLU allows a small,
non-zero gradient (slope) for negative values.
This ensures that neurons continue learning (even for negative values).
where ‘\(\alpha\)’ is a small constant (e.g., 0.01)
Benefit:
Fixes the ‘dying ReLU’ problem.
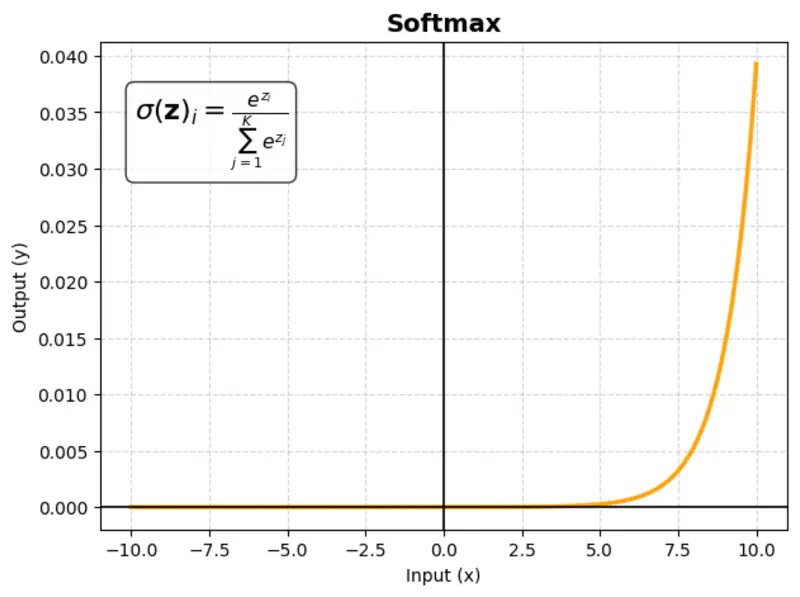
images/deep_learning/fundamentals/activation_function/Leaky_relu_derivative.png in assets/ or Page Bundle.Multivariate activation function that takes a vector of raw scores (logits) and converts them into a probability distribution; sum of probabilities = 1.
\[\sigma(\mathbf{z})_i = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}}\]where ‘K’ = number of classes
Usage:
Almost exclusively used in the output layer of multi-class classification networks.
Example:
Consider an AI model reading a product review to categorize the customer’s mood into three classes:
Positive,Neutral, or Negative.
| Class | Score (Logit) | Softmax |
|---|---|---|
| Positive | 3 | 82.1% |
| Neutral | 1 | 11.1% |
| Negative | 0.5 | 6.7% |
Similarly, you can calculate for negative and neutral sentiments.