Intro to DL
5 minute read
📘 Deep learning is a subset of AI and machine learning that uses multi-layered artificial neural networks to simulate human-like learning, analyzing vast data to identify complex patterns, such as recognizing objects in photos, detecting medical anomalies, or processing natural language, like LLMs.
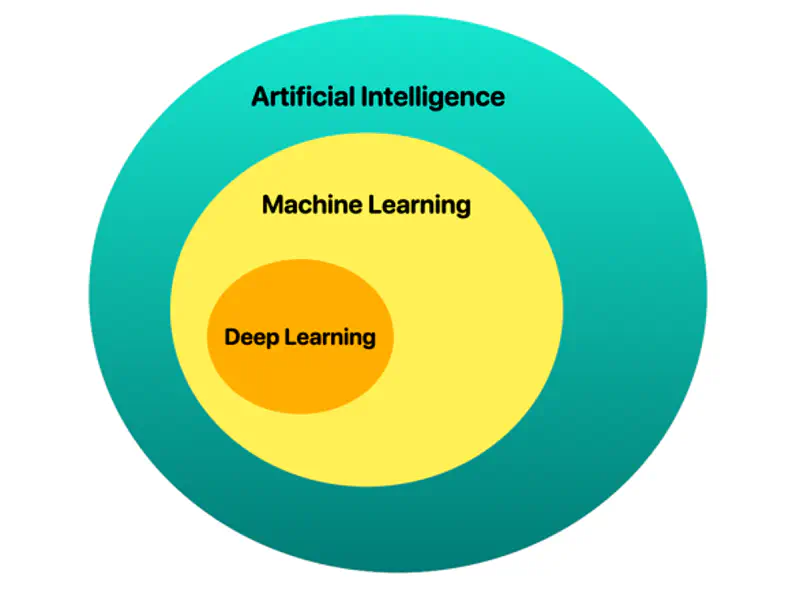
💡 The ‘deep’ in ‘deep learning’ stands for the idea of successive layers of representations.
🐋 It is “deep” because it uses many layers (often hundreds) to automatically extract, transform, and map data features into predictions, surpassing traditional machine learning in handling unstructured data.
🖼️ A deep neural network for digit classification
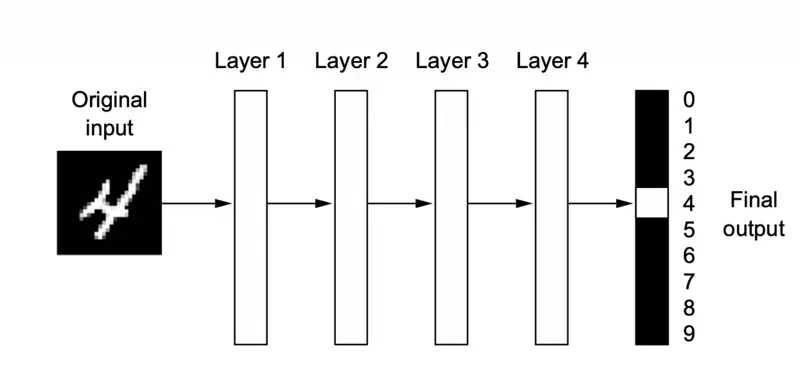
📘 Deep learning is a multistage way to learn data representations.
💡 It’s a simple idea - but, as it turns out, very simple mechanisms, sufficiently scaled, can end up looking like magic.
🖼️ A fully connected neural network
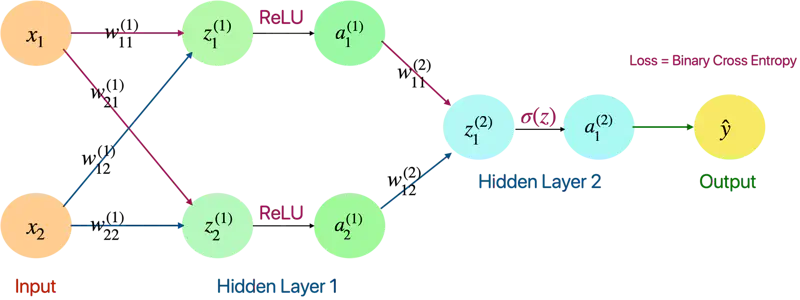
Feature Engineering: Deep learning completely automates what used to be the most crucial step in a machine learning workflow, making problem-solving much easier.
Performance: Better performance for solving many kinds of problems, especially with unstructured data.
Although deep learning is a fairly old subfield of machine learning, it only rose to prominence in the early 2010s.
- Perceptron (1957), Frank Rosenblatt
- Back Propagation (1986), Geoffrey Hinton
- LSTM (1997), Sepp Hochreiter and Jürgen Schmidhuber
Some of the important algorithms such as back propagation, long short term memory (time series) of deep learning were well understood before 2000s and have barely changed since then.
Break Through Moment
It began with a win in academic image-classification competitions with GPU-trained deep neural networks.
🚀 But the watershed moment came in 2012, with the entry of Geoffrey Hinton’s group in the yearly large-scale image-classification challenge ImageNet (ImageNet Large Scale Visual Recognition Challenge, or ILSVRC for short).
ImageNet
The ImageNet challenge was very difficult at the time, consisting of classifying high-resolution color images into 1,000 different categories after training on 1.4 million
images.
- In 2011, the top-five accuracy of the winning model, based on classical approaches to computer vision, was only 74.3%.
- Then, in 2012, a team led by Alex Krizhevsky and advised by Geoffrey Hinton was able to achieve a top-five accuracy of 83.6% — a significant breakthrough.
- Since then, the competition has been dominated by deep convolutional neural networks.
Note: By 2015, the winner reached an accuracy of 96.4%, and the classification task on ImageNet was considered to be a completely solved problem.
Driving Forces
- Hardware
- Datasets and Benchmarks
- Algorithmic Advances
Note: The real bottlenecks throughout the 1990s and 2000s were data and hardware.
Experiments and Engineering
Because the deep learning field is guided by experimental findings rather than by theory, algorithmic advances only become possible when appropriate data and hardware are available to try new ideas
(or to scale up old ideas, as is often the case).
Machine learning isn’t mathematics or physics, where major advances can be done with a pen and a piece of paper.
🚀 It’s an engineering science.
Graphical Processing Unit (GPU)
Throughout the 2000s, companies like NVIDIA and AMD invested billions of dollars in developing fast, massively parallel chips (GPUs) for video games to render complex 3D scenes in real time on the computer screen.
This investment came to benefit the scientific community when, in 2007, NVIDIA launched CUDA, a programming interface for its line of GPUs.
Deep neural networks, consisting mostly of many small matrix multiplications, are also highly parallelizable using GPUs.
💡 AI is sometimes heralded as the new industrial revolution.
If deep learning is the steam engine of this revolution, then data is its coal: the raw material that powers
our intelligent machines, without which nothing would be possible.
🌐 When it comes to data, in addition to the exponential progress in storage hardware over the past 20 years (following Moore’s law), the game changer has been the rise of the internet, making it feasible to collect and distribute very large datasets for machine learning.
Today, large companies work with image datasets, video datasets, and natural language datasets that could not have been collected without the internet.
In addition to hardware and data, until the late 2000s, we were missing a reliable way
to train very deep neural networks.
As a result, neural networks were still fairly shallow, using only one or two layers
of representations; thus, they weren’t able to shine against more-refined shallow methods such as SVMs and Random Forests.
- The key issue was that of gradient propagation through deep stacks of layers.
- The feedback signal used to train neural networks would fade away as the number of layers increased.
🎯 This changed around 2009–2010 with the advent of several simple but important algorithmic improvements that allowed for better gradient propagation:
- Better activation functions for neural layers, such as ReLU.
- Better weight-initialization schemes, such as, He (2015) and Xavier initialization (2010).
- Better optimization schemes, such as RMSProp (2012) and Adam (2014).
- Advanced ways to improve gradient propagation were discovered, such as batch normalization (2015), residual connections (2015).