Categorical Variables
2 minute read
💡 ML models operate on numerical vectors.
👉 Categorical variables must be transformed (encoded) while preserving information and semantics.
- One Hot Encoding (OHE)
- Label Encoding
- Ordinal Encoding
- Frequency/Count Encoding
- Target Encoding
- Hash Encoding
⭐️ When the categorical data (nominal) is without any inherent ordering.
- Create binary columns per category.
- e.g.: Colors: Red, Blue, Green.
- Colors: [1,0,0], [0,1,0], [0,0,1]
Note: Use when low cardinality, or small number of unique values (<20).
⭐️ Assigns a unique integer (e.g., 0, 1, 2) to each category.
- When to use ?
- Target variable, i.e, unordered (nominal) data, in classification problems.
- e.g. encoding a city [“Paris”, “Tokyo”, “Amsterdam”] -> [1, 2, 0], (Alphabetical: Amsterdam=0, Paris=1, Tokyo=2).
- When to avoid ?
- For nominal data in linear models, because it can mislead the model to assume an order/hierarchy, when there is none.
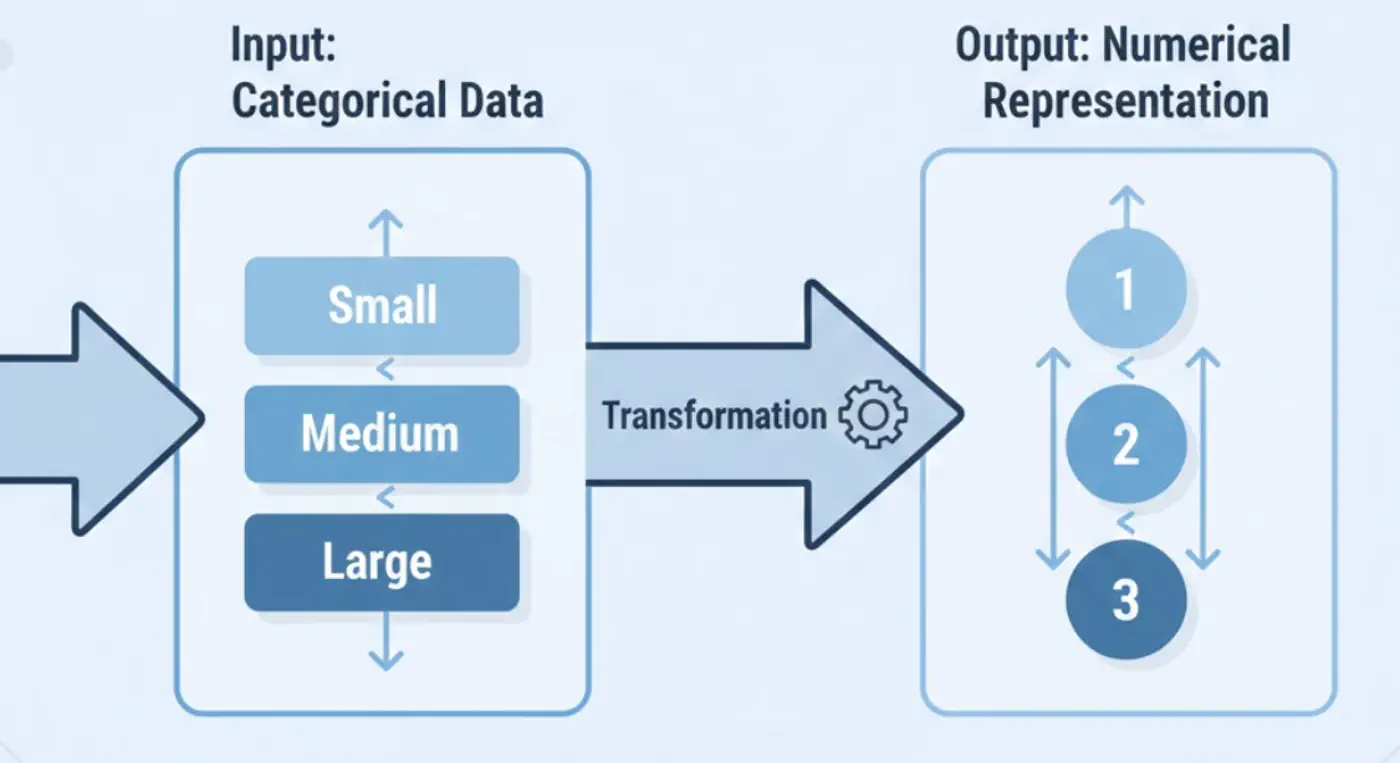
⭐️ When categorical data has logical ordering.
Best for: Ordered (ordinal) input features.
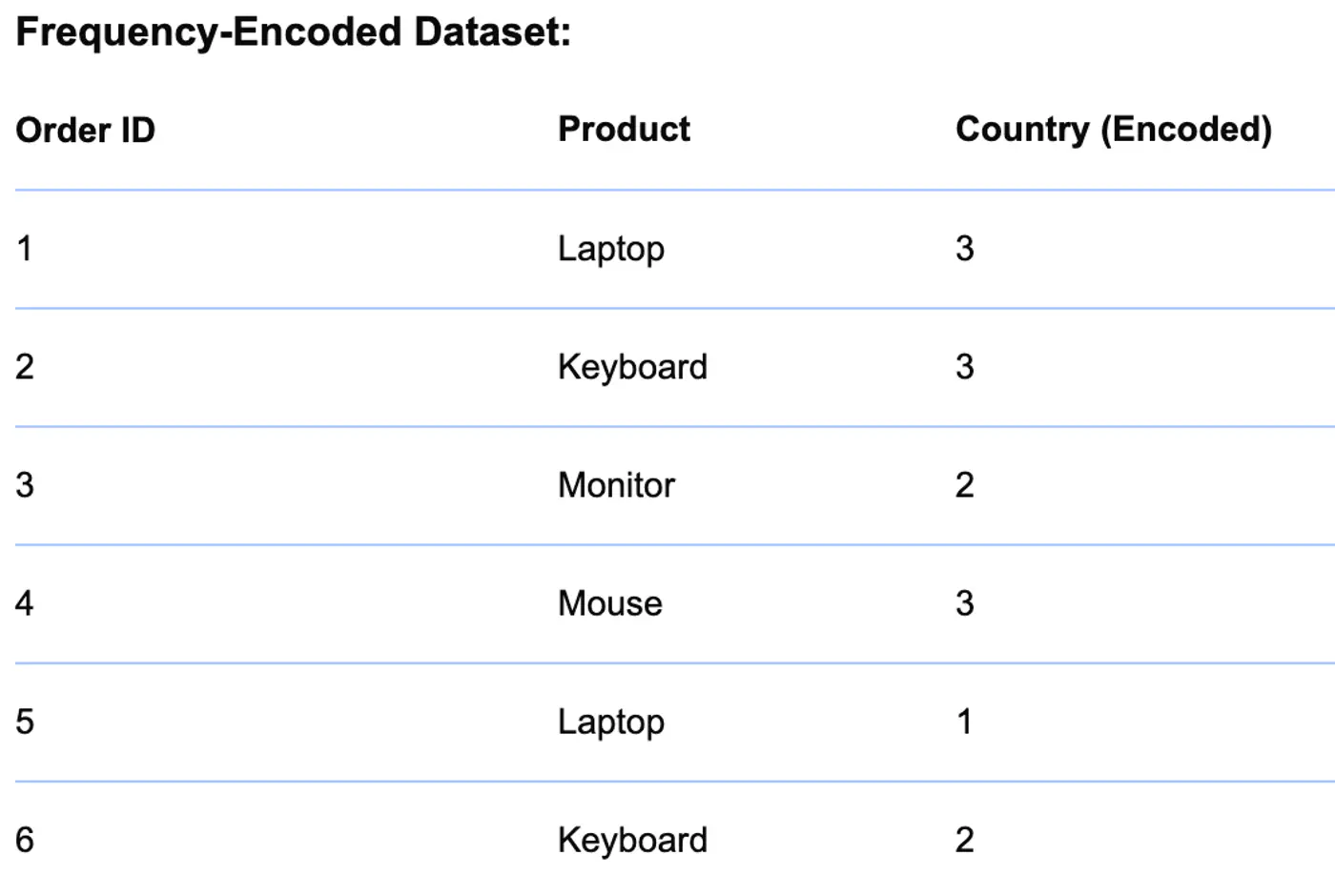
⭐️ Replace categories with their frequency or count in the dataset.
- Useful for high-cardinality features where many unique values exist.
👉 Example
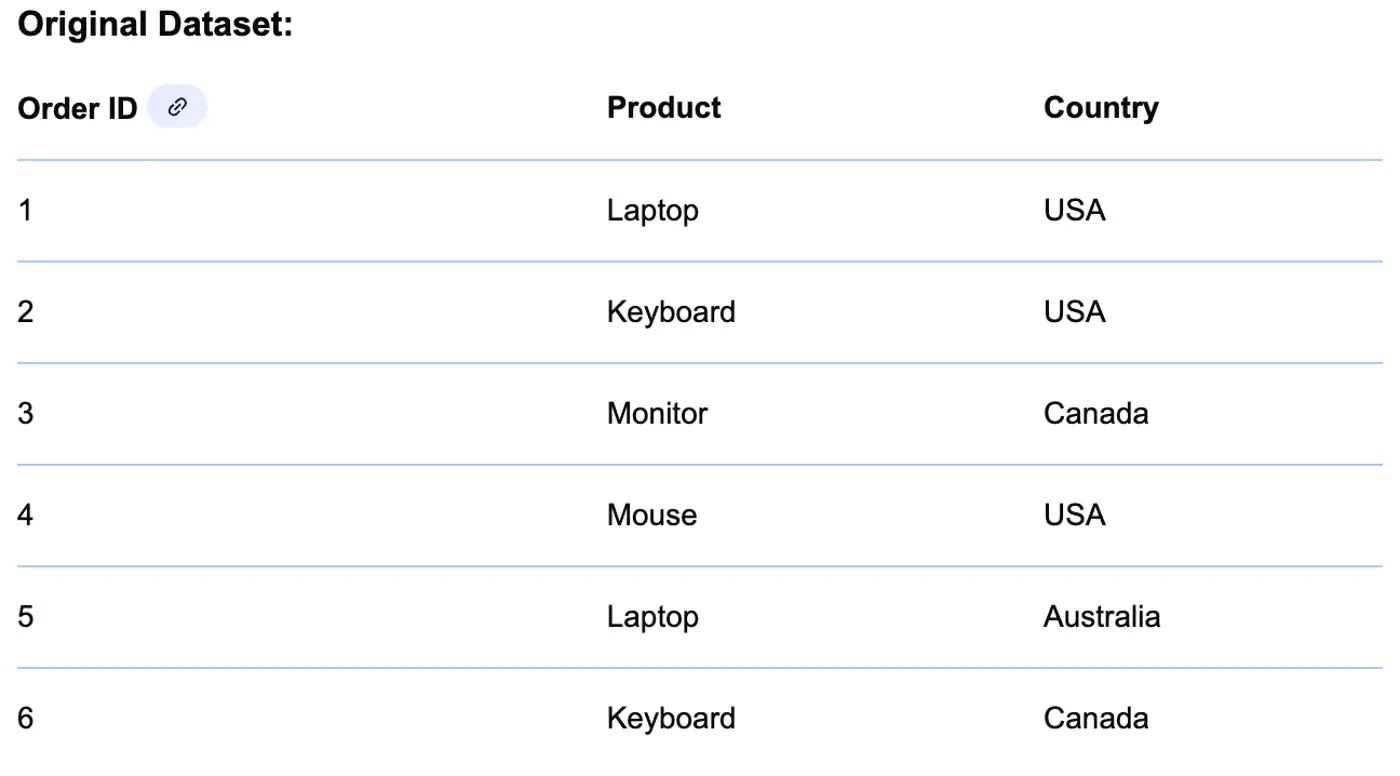
👉 Frequency of Country

👉 Country replaced with Frequency
⭐️ Replace a category with the mean of the target variable for that specific category.
- When to use ?
- For high-cardinality nominal features, where one hot encoding is inefficient, e.g., zip code, product id, etc.
- Strong correlation between the category and the target variable.
- When to avoid ?
- With small datasets, because the category averages (encodings) are based on too few samples, making them unrepresentative.
- Also, it can lead to target leakage and overfitting unless proper smoothing or cross-validation techniques (like K-fold or Leave-One-Out) are used.
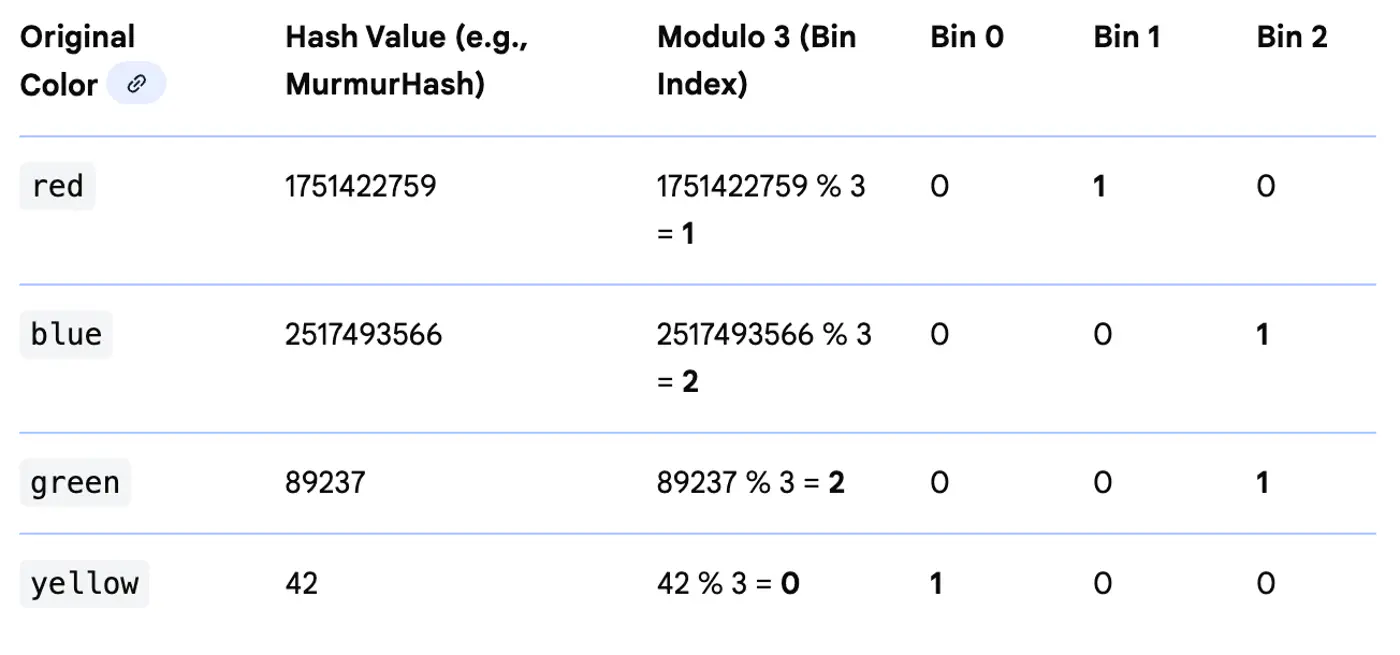
⭐️ Maps categories to a fixed number of features using a hash function.
Useful for high-cardinality features where we want to limit the dimensionality.
End of Section