Types of ML
3 minute read
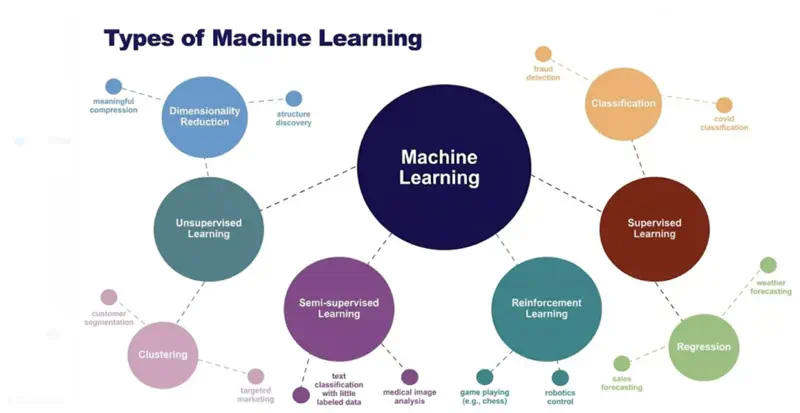
Supervised Learning uses labelled data (input-output pairs) to predict outcomes, such as, spam filters.
- Regression
- Classification
Unsupervised Learning finds hidden patterns in unlabelled data (like customer segmentation).
- Clustering (k-means, hierarchical)
- Dimensionality Reduction and Data Visualization (PCA, t-SNE, UMAP)
Semi-Supervised Learning uses a mix of both, leveraging a small amount of labelled data with a large amount of
unlabelled data to improve accuracy.
- Pseudo-labeling
- Graph-based methods
1. Pseudo-labelling:
- A model is initially trained on the available, limited labelled dataset.
- This trained model is then used to predict labels for the unlabelled data.These predictions are called ‘pseudo-labels’.
- The model is then retrained using both the original labelled data and the newly pseudo-labelled data.
Benefit:
It effectively expands the training data by assigning labels to previously unlabelled examples,
allowing the model to learn from a larger dataset.
2. Graph-based methods:
- Data points (both labelled and unlabelled) are represented as nodes in a graph.
- Edges are established between nodes based on their similarity or proximity in the feature space.The weight of an edge often reflects the degree of similarity.
- The core principle is that similar data points should have similar labels.This assumption is propagated through the graph, effectively ‘spreading’ the labels from the labelled nodes to the unlabelled nodes based on the graph structure.
- Various algorithms, such as label propagation or graph neural networks (GNNs), can be employed to infer the labels of unlabelled nodes.
Benefit:
These methods are particularly useful when the data naturally exhibits a graph-like structure or when local
neighborhood information is crucial for classification.
Agent learns to make optimal decisions by interacting with an environment, receiving rewards (positive feedback)
or penalties (negative feedback) for its actions.
- Mimic human trial-and-error learning to achieve a goal 🎯.
- Agent: The learning entity that makes decisions and takes actions within the environment.
- Environment: The external system with which the agent interacts.It defines the rules, states, and the consequences of the agent’s actions.
- State: A specific configuration or situation of the environment at a given point in time.
- Action: A move or decision made by the agent in a particular state.
- Reward: A numerical signal received by the agent from the environment, indicating the desirability of an action taken
in a specific state.
Positive rewards encourage certain behaviors, while negative rewards (penalties) discourage them. - Policy: The strategy or mapping that defines which action the agent should take in each state to maximize long-term rewards 💰.
- Exploration: The agent tries out new actions to discover their effects and potentially find better strategies.
- Exploitation: The agent utilizes its learned knowledge to choose actions that have yielded high rewards in the past.
Note: The agent continuously balances exploration and exploitation to refine its policy and achieve the optimal behavior.
Large Language Models (LLMs) are deep learning models that often employ unsupervised learning techniques during their pre-training phase.
LLMs are trained on massive amounts of raw, unlabelled text data (e.g., books, articles, web pages) to predict the next
word in a sequence or fill in masked words.
This process, often called self-supervised learning, allows the model to learn grammar, syntax, semantics,
and general world knowledge by identifying statistical relationships within the text.
LLMs generally also undergo supervised fine-tuning (SFT) for specific tasks, where they are trained on labeled datasets to improve performance on those tasks.
Reinforcement Learning from Human Feedback (RLHF) allows LLMs to learn from human judgment, enabling them to generate more nuanced, context-aware, and ethically aligned outputs that better meet human expectations.
End of Section