Decision Trees For Regression
2 minute read
Decision Trees can also be used for Regression tasks but using a different metrics.
⭐️Metric:
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
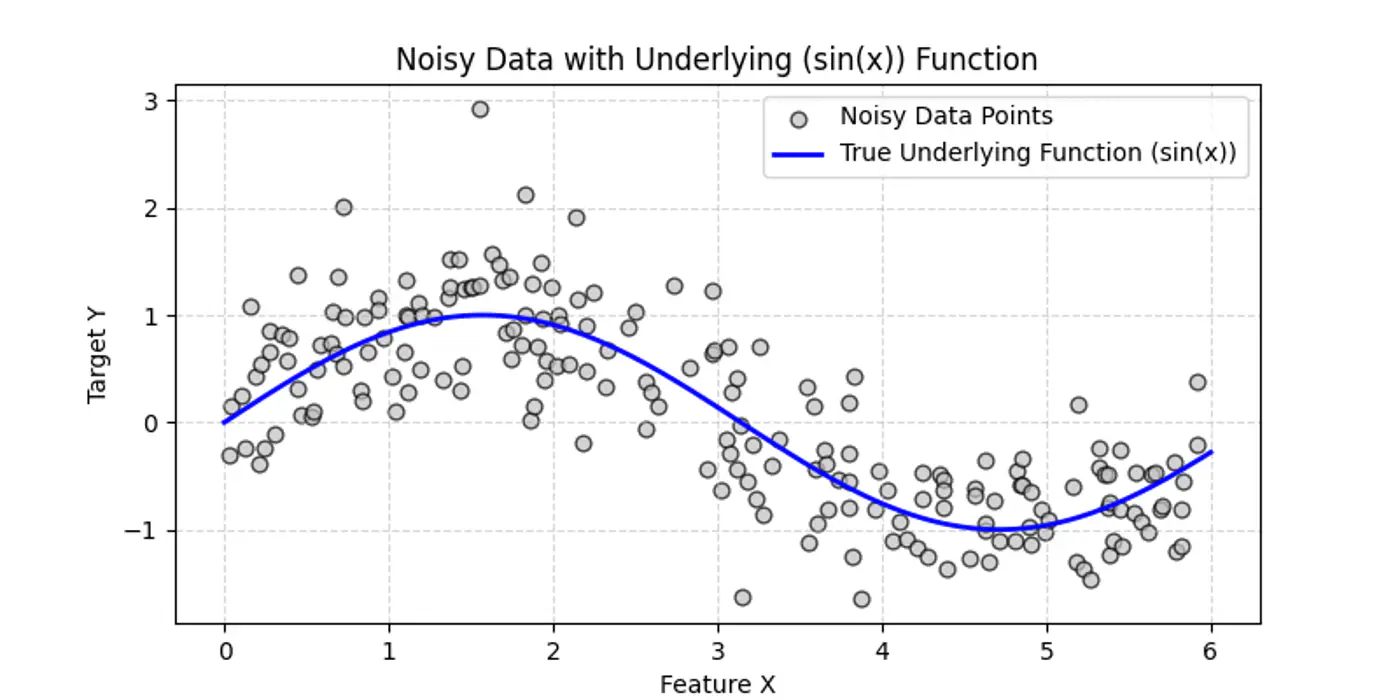
👉Say we have a following dataset, that we need to fit using decision trees:
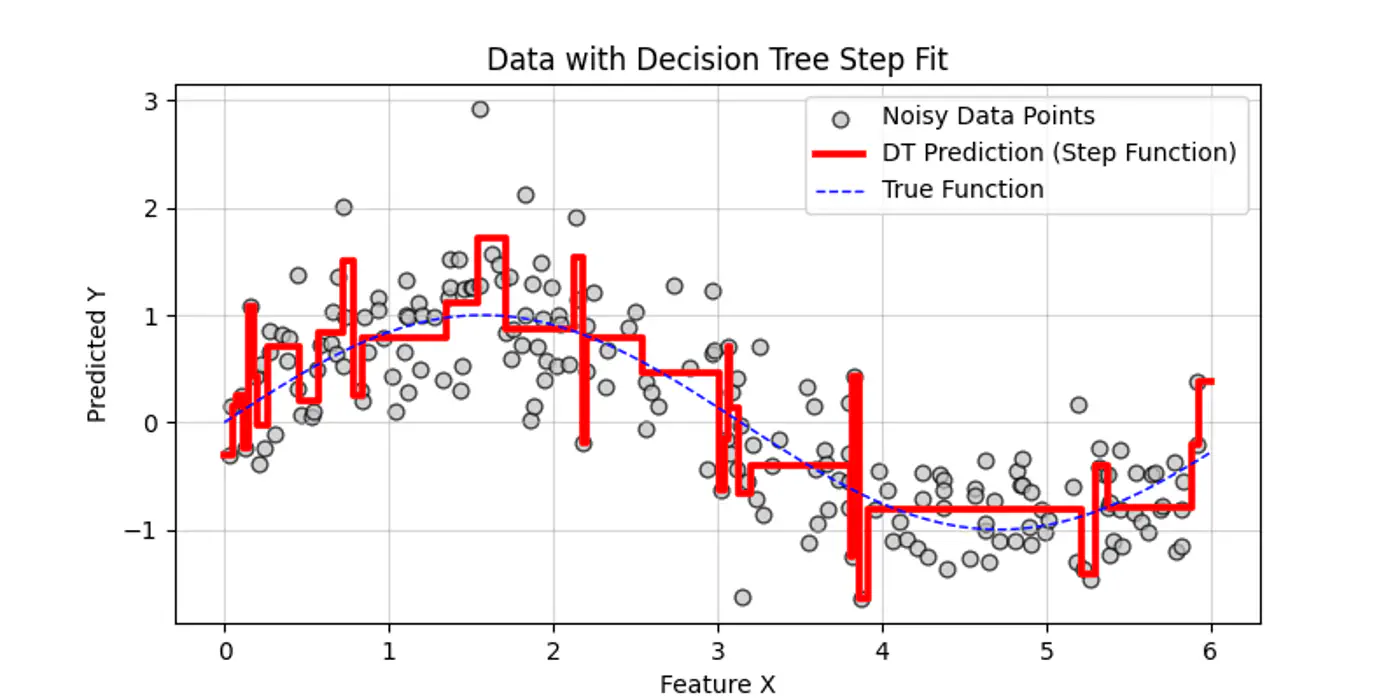
👉Decision trees try to find the decision splits, building step functions that approximate the actual curve, as shown below:
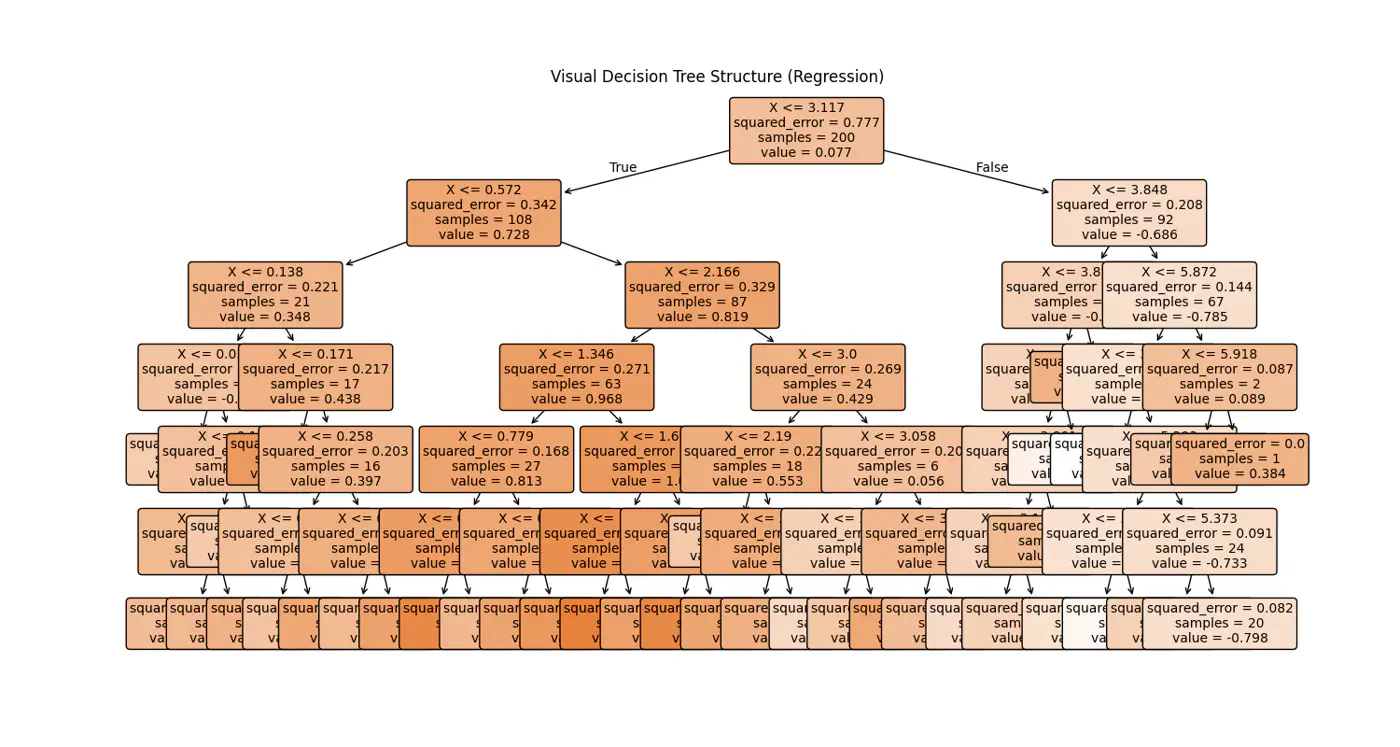
👉Internally the decision tree (if else ladder) looks like below:
Decision trees cannot predict values outside the range of the training data, i.e, extrapolation.
Let’s understand the interpolation and extrapolation cases one by one.
⭐️Predicting values within the range of features and targets observed during training 🏃♂️.
- Trees capture discontinuities perfectly, because they are piece-wise constant.
- They do not try to force a smooth line where a ‘jump’ exists in reality.
e.g: Predicting a house 🏡 price 💰 for a 3-BHK home when you have seen 2-BHK and 4-BHK homes in that same neighborhood.
⭐️Predicting values outside the range of training 🏃♂️data.
Problem:
Because a tree outputs the mean of training 🏃♂️ samples in a leaf, it cannot predict a value higher than the
highest ‘y’ it saw during training 🏃♂️.
- Flat-Line: Once a feature ‘X’ goes beyond the training boundaries, the tree falls into the same ‘last’ leaf forever.
e.g: Predicting the price 💰 of a house 🏡 in 2026 based on data from 2010 to 2025.
End of Section