Decision Trees Introduction
Decision Trees Introduction
2 minute read
How do we classify the below dataset ?
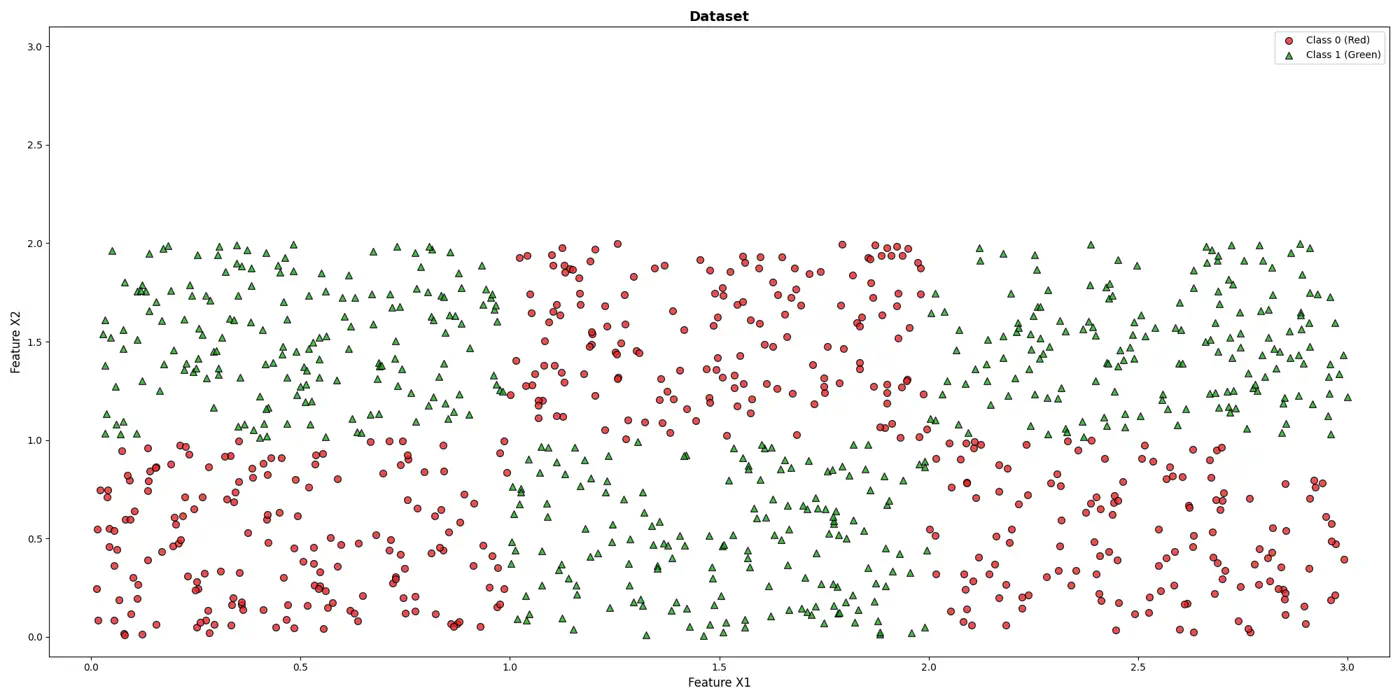
💡It can be written as nested 🕸️ if else statements.
e.g: To classify the left bottom corner red points we can write:
👉if (FeatureX1 <1 & FeatureX2 <1)
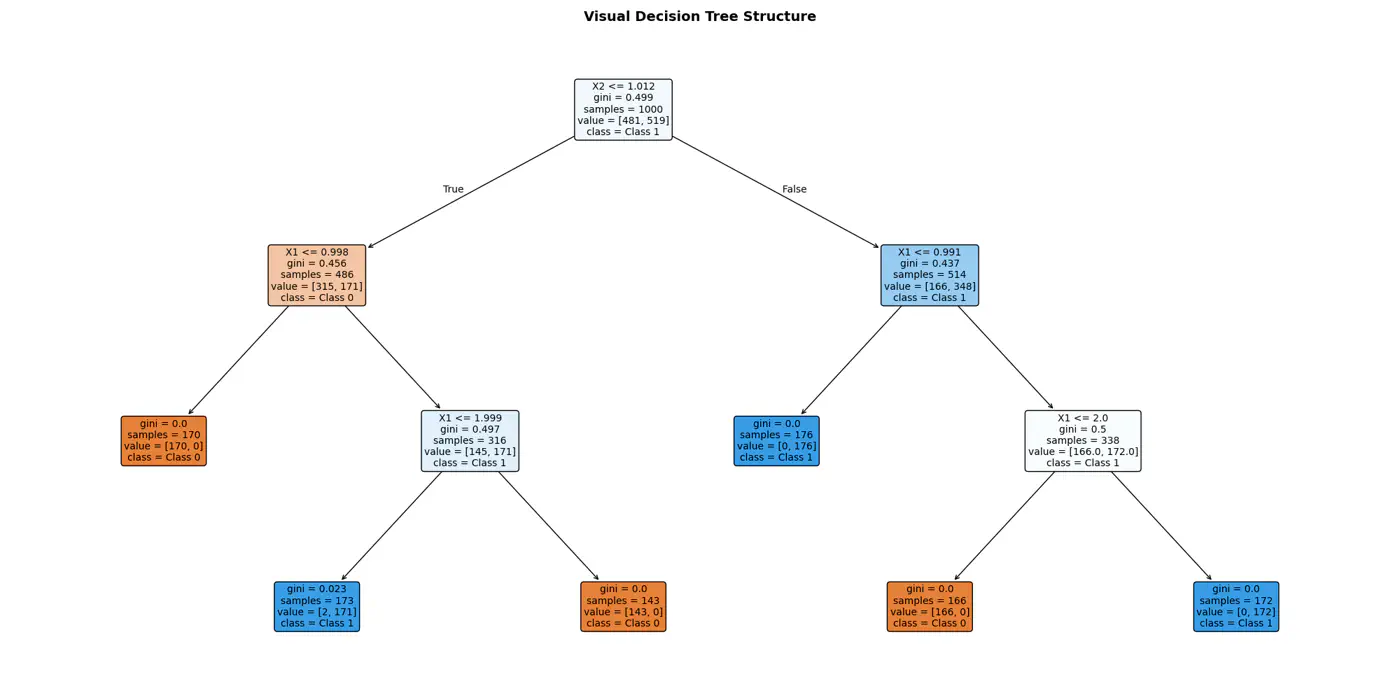
⭐️Extending the logic for all, we have an if else ladder like below:
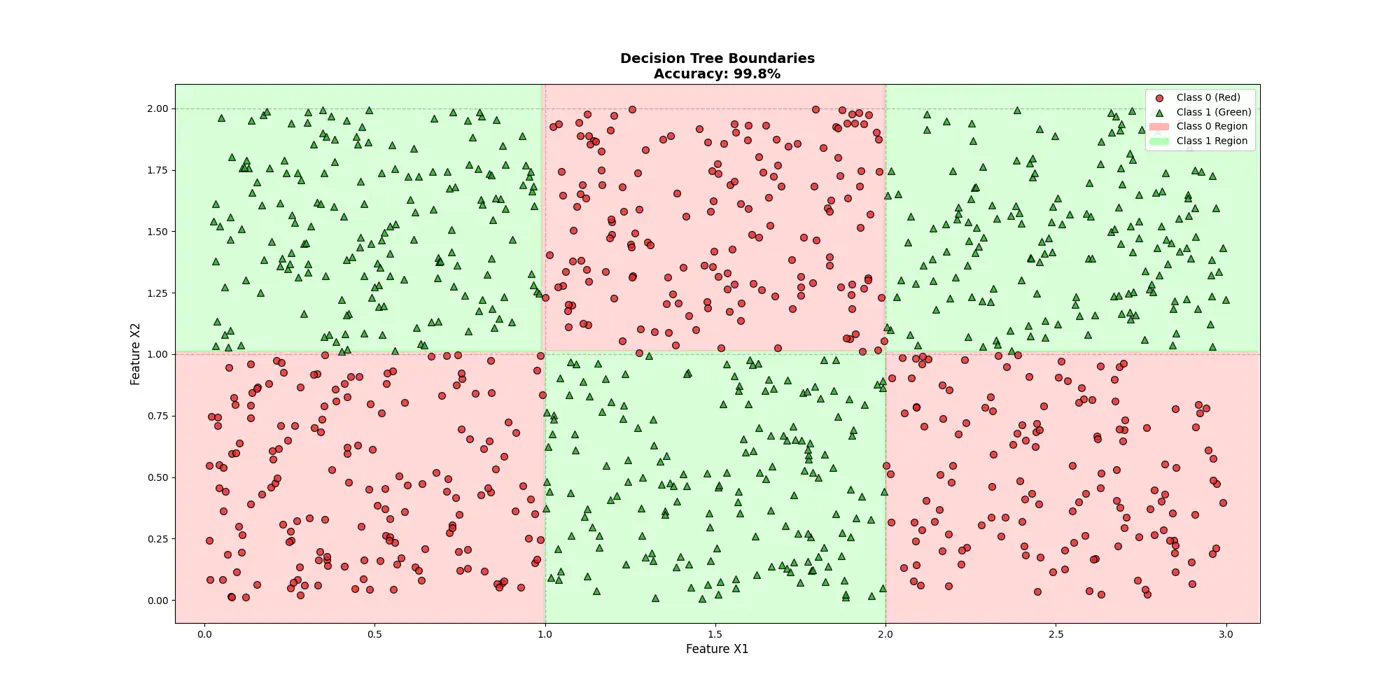
👉Final decision boundaries will be something like below:
What is a Decision Tree 🌲?
- Non-parametric model.
- Recursively partitions the feature space.
- Top-down, greedy approach to iteratively select feature splits.
- Maximize purity of a node, based on metrics, such as, Information Gain 💵 or Gini 🧞♂️Impurity.
Note: We can extract the if/else logic of the decision tree and write in C++/Java for better performance.
Computation 💻
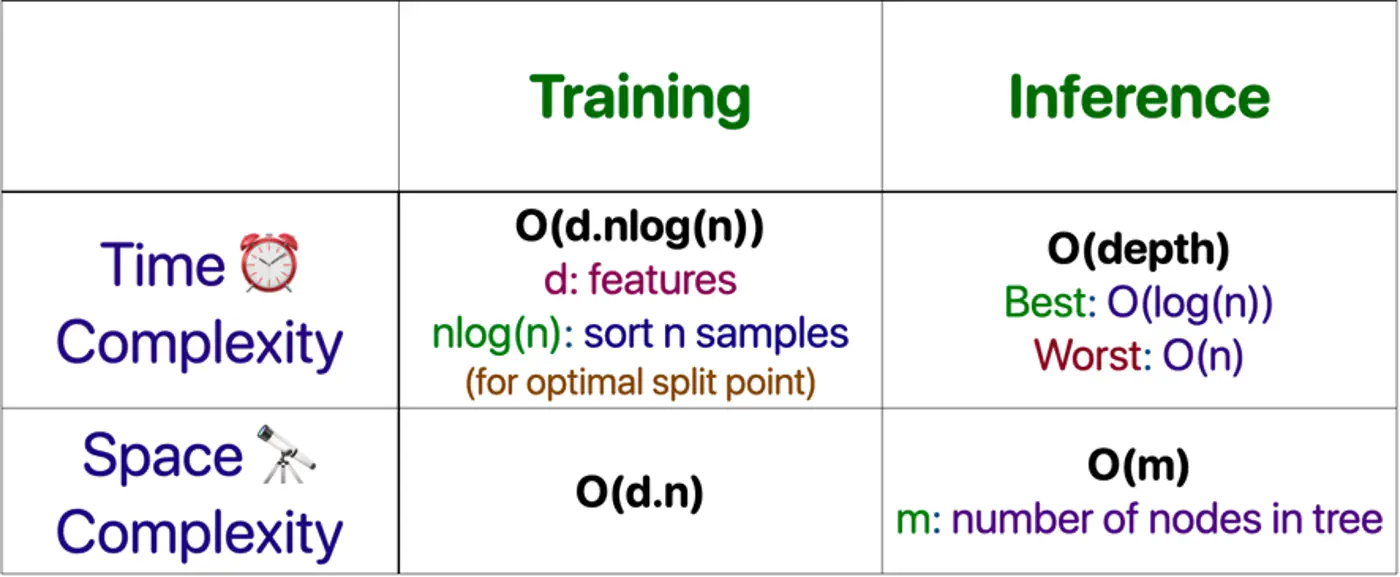
Decision Tree 🌲 Analysis
⭐️Building an optimal decision tree 🌲 is a NP-Hard problem.
👉(Time Complexity: Exponential; combinatorial search space)
- Pros
- No standardization of data needed.
- Highly interpretable.
- Good runtime performance.
- Works for both classification & regression.
- Cons
- Number of dimensions should not be too large. (Curse of dimensionality)
- Overfitting.
When to use Decision Tree 🌲
- As base learners in ensembles, such as, bagging(RF), boosting(GBDT), stacking, cascading, etc.
- As a baseline, interpretable, model or for quick feature selection.
- Runtime performance is important.
End of Section