Expectation Maximization
3 minute read
- If we knew the parameters (\(\mu, \Sigma, \pi\)) we could easily calculate which cluster ‘z’ each point belongs to (using probability).
- If we knew the cluster assignments ‘z’ of each point, we could easily calculate the parameters for each cluster (using simple averages).
But we do not know either of them, as the parameters of the Gaussians - we aim to find and cluster indicator latent variable is hidden.
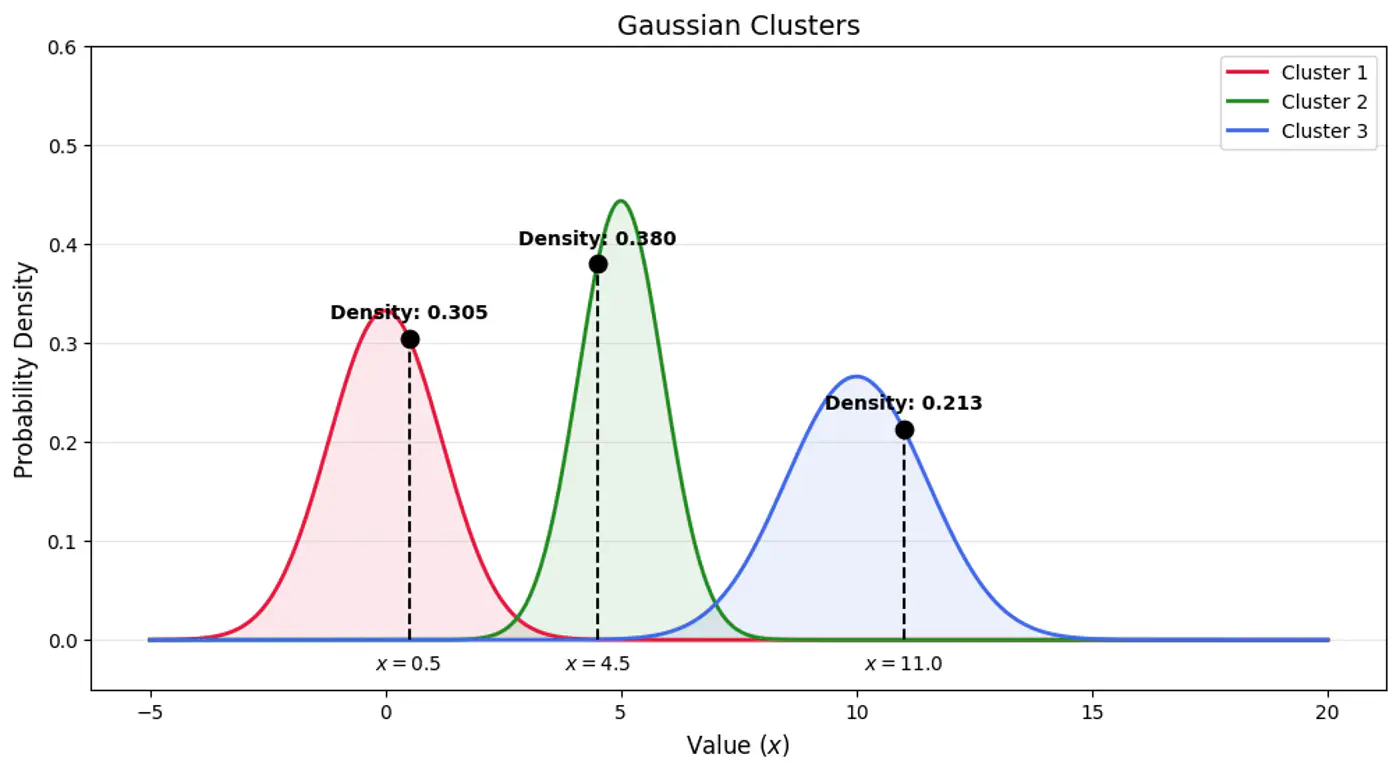
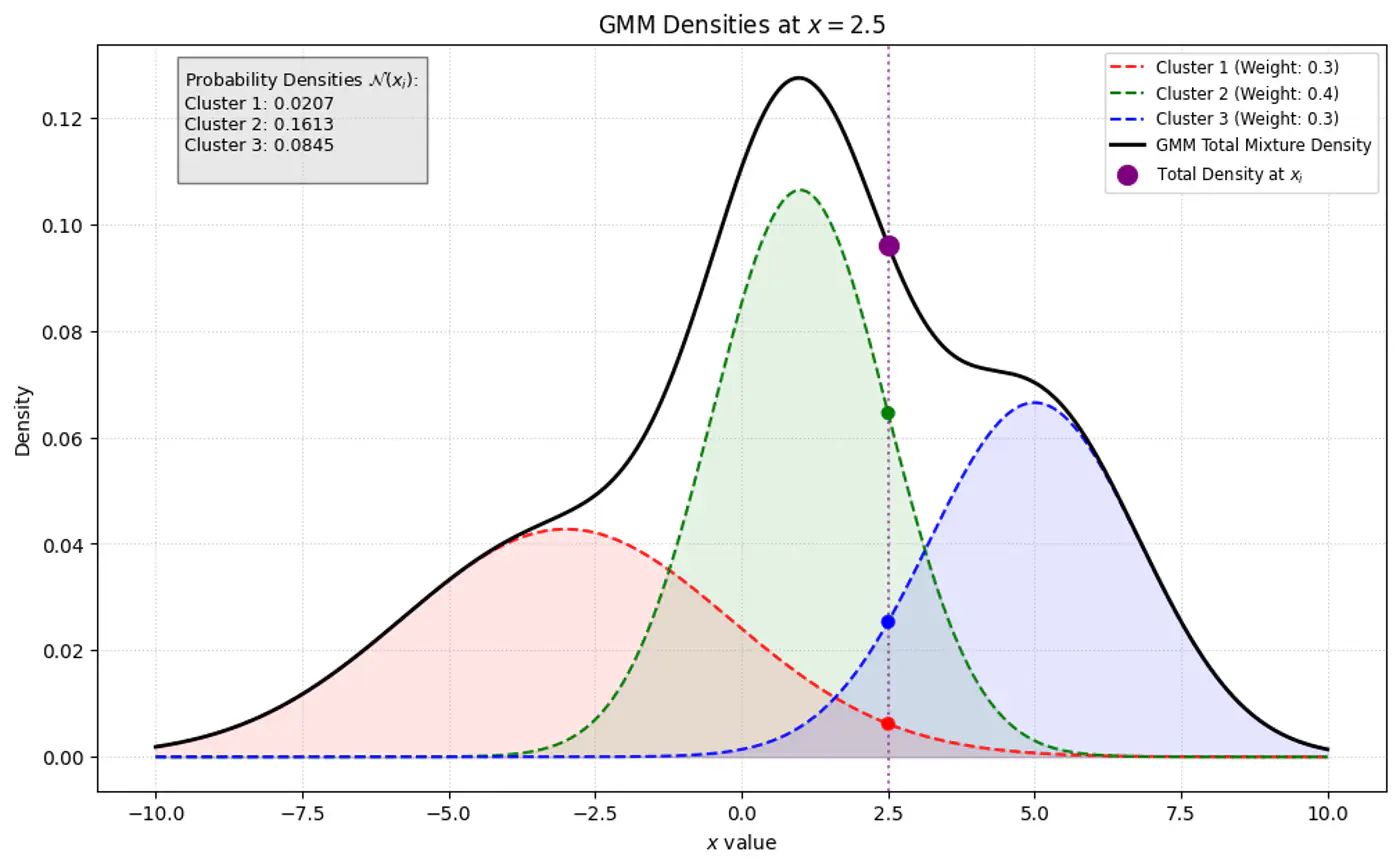
Find latent cluster indicator variable \(z_{ik}\).
But \(z_{ik}\) is a ‘hard’ assignment’ (either ‘0’ or ‘1’).
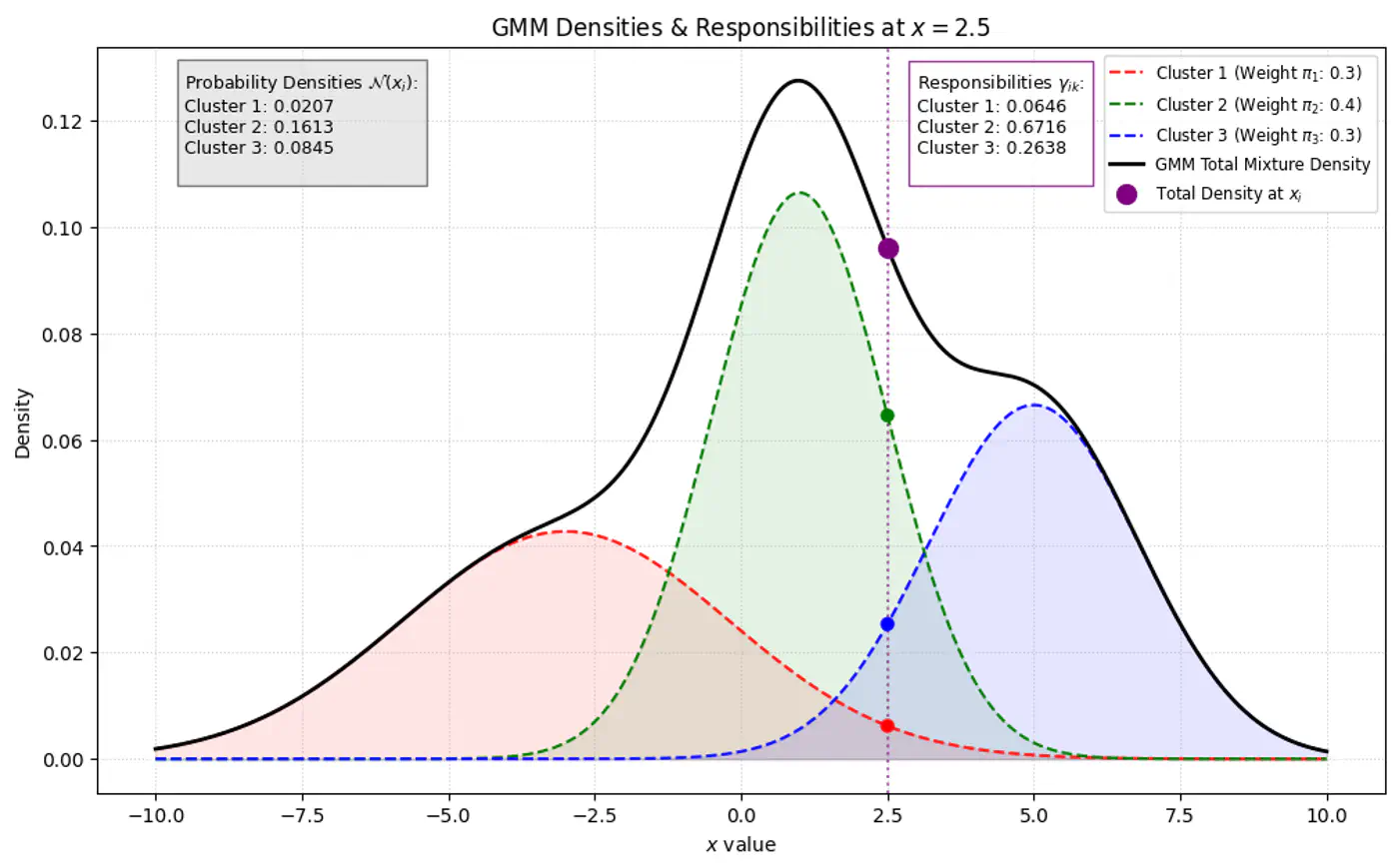
- Because we do not observe ‘z’, we use another variable ‘Responsibility’ (\(\gamma_{ik}\)) as a ‘soft’ assignment (value between 0 and 1).
- \(\gamma_{ik}\) is the expected value of the latent variable \(z_{ik}\), given the observed data \(x_{i}\) and parameters \(\Theta\). \[\gamma _{ik}=E[z_{ik}\mid x_{i},\theta ]=P(z_{ik}=1\mid x_{i},\theta )\]
Note: \(\gamma_{ik}\) is the posterior probability (or ‘responsibility’) that cluster ‘k’ takes for explaining data point \(x_{i}\).
Using Bayes’ Theorem, we derive responsibility (posterior probability that component ‘k’ generated data point \(x_i\)) by combining the prior/weights (\(\pi_k\)) and the likelihood (\(\mathcal{N}(x_{i}\mid \mu _{k},\Sigma _{k})\)).
\[\gamma _{ik}= P(z_{ik}=1\mid x_{i},\theta ) = \frac{P(z_{ik}=1)P(x_{i}\mid z_{ik}=1)}{P(x_{i})}\]\[\gamma _{ik}=\frac{\pi _{k}\mathcal{N}(x_{i}\mid \mu _{k},\Sigma _{k})}{\sum _{j=1}^{K}\pi _{j}\mathcal{N}(x_{i}\mid \mu _{j},\Sigma _{j})}\]Bayes’ Theorem: \(P(A|B)=\frac{P(B|A)\cdot P(A)}{P(B)}\)
GMM Densities at point
GMM Densities at point (different cluster weights)
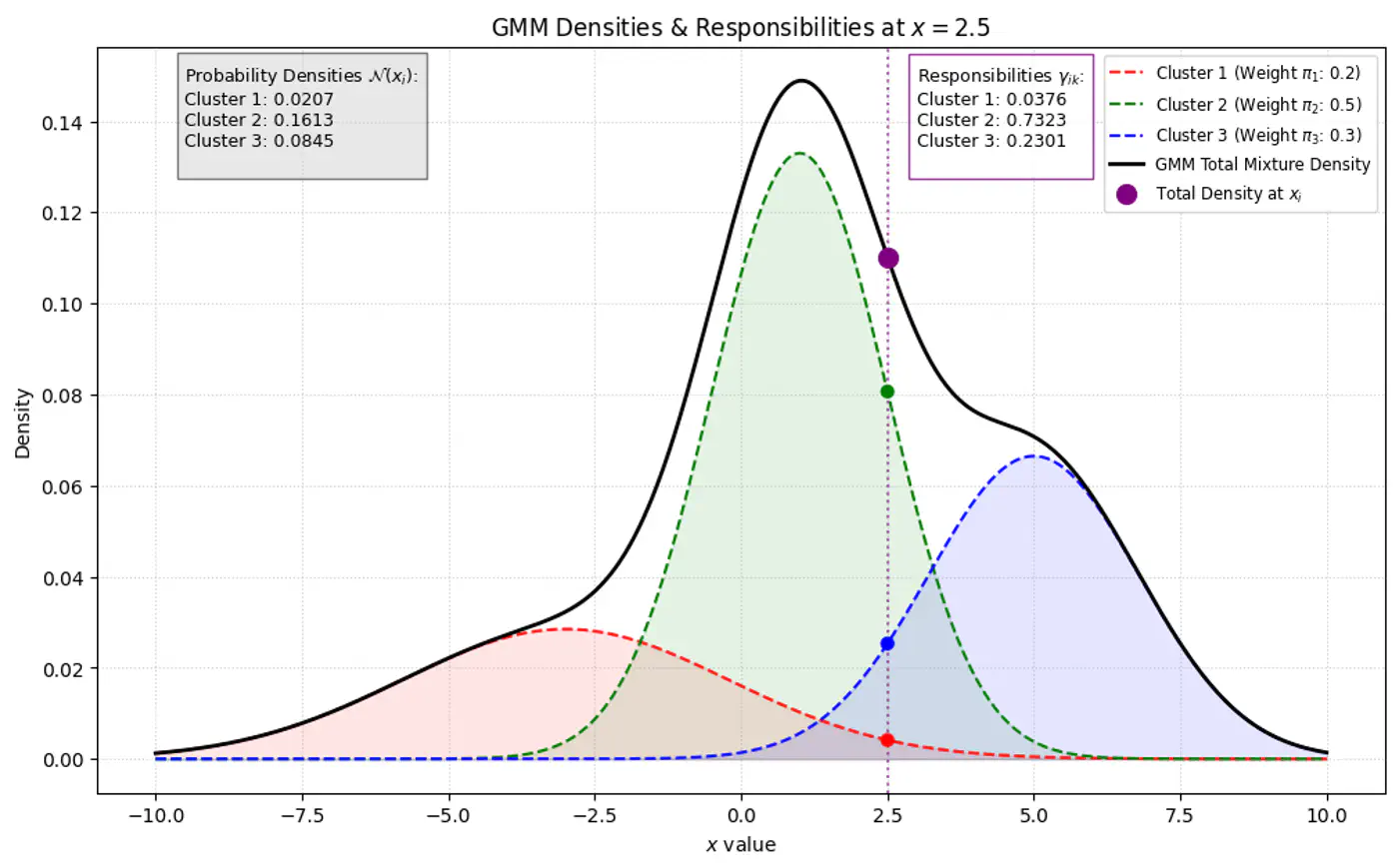
- Initialization: Assign initial values to parameters (\(\mu, \Sigma, \pi\)), often using K-Means results.
- Expectation Step (E): Calculate responsibilities; provides ‘soft’ assignments of points to clusters.
- Maximization Step (M): Update parameters using responsibilities as weights to maximize the expected log-likelihood.
- Convergence: Repeat ‘E’ and ‘M’ steps until the change in log-likelihood falls below a threshold.
Given our current guess of the clusters, what is the probability that point \(x_i\) came from cluster ‘k’ ?
\[\gamma (z_{ik})=p(z_{i}=k|\mathbf{x}_{i},\mathbf{\theta }^{(\text{old})})=\frac{\pi _{k}^{(\text{old})}\mathcal{N}(\mathbf{x}_{i}|\mathbf{\mu }_{k}^{(\text{old})},\mathbf{\Sigma }_{k}^{(\text{old})})}{\sum _{j=1}^{K}\pi _{j}^{(\text{old})}\mathcal{N}(\mathbf{x}_{i}|\mathbf{\mu }_{j}^{(\text{old})},\mathbf{\Sigma }_{j}^{(\text{old})})}\]\(\pi_k\) : Probability that a randomly selected data point \(x_i\) belongs to the k-th component before we even look at the specific value of \(x_i\), such that \(\pi_k \ge 0\) and \(\sum _{k=1}^{K}\pi _{k}=1\).
Update the parameters (\(\mu, \Sigma, \pi\)) by calculating weighted versions of the standard MLE formulas using responsibilities as weight ️♀️.
\[ \begin{align*} &\bullet \mathbf{\mu }_{k}^{(\text{new})}=\frac{1}{N_{k}}\sum _{i=1}^{N}\gamma (z_{ik})\mathbf{x}_{i} \\ &\bullet \mathbf{\Sigma }_{k}^{(\text{new})}=\frac{1}{N_{k}}\sum _{i=1}^{N}\gamma (z_{ik})(\mathbf{x}_{i}-\mathbf{\mu }_{k}^{(\text{new})})(\mathbf{x}_{i}-\mathbf{\mu }_{k}^{(\text{new})})^{\top } \\ &\bullet \pi _{k}^{(\text{new})}=\frac{N_{k}}{N} \end{align*} \]- where, \(N_{k}=\sum _{i=1}^{N}\gamma (z_{ik})\) is the effective number of points assigned to component ‘k'.
You've worked through all 3 lessons in this module.