Performance Metrics
6 minute read
E.g.: For regression models, we have - MSE, RMSE, MAE, R^2 metric, etc.
Here, we will discuss various performance metrics for classification models.
It is a table that summarizes model’s predictions against the actual class labels, detailing where the model
succeeded and where it failed.
It is used for binary or multi-class classification problems.
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
Type-1 Error:
It is the number of false positives.
e.g.: Model predicted that a patient has diabetes, but the patient actually does NOT have diabetes; “false alarm”.
Type-2 Error:
It is the number of false negatives.
e.g.: Model predicted that a patient does NOT have diabetes, but the patient actually has diabetes; “a miss”.
Many metrics are derived from the confusion matrix.
Precision:
It answers the question: “Of all the instances that the model predicted as positive, how many were actually positive?”
It measures exactness or quality of the positive predictions.
Recall:
It answers the question: “Of all the actual positive instances, how many did the model correctly identify?”
It measures completeness or coverage of the positive predictions.
F1 Score:
It is the harmonic mean of precision and recall.
It is used when we need a balance between precision and recall; also helpful when we have imbalanced data.
Harmonic mean penalizes extreme values more heavily, encouraging both metrics to be high.
| Precision | Recall | F1 Score | Mean |
|---|---|---|---|
| 0.5 | 0.5 | 0.50 | 0.5 |
| 0.7 | 0.3 | 0.42 | 0.5 |
| 0.9 | 0.1 | 0.18 | 0.5 |
Trade-Off:
Precision Focus:: Critical when cost of false positives is high.
e.g: Identify a potential terrorist.
A false positive, i.e, wrongly flagging an innocent person as a potential terrorist is very harmful.
Recall Focus:: Critical when cost of false negatives is high.
e.g.: Medical diagnosis of a serious disease.
A false negative, i.e, falsely missing a serious disease can cost someone’s life.
Analyze the performance of an access control system. Below is the data for 1000 access attempts.
| Predicted Authorised Access | Predicted Unauthorised Access | |
|---|---|---|
| Actual Authorised Access | 90 (TP) | 10 (FN) |
| Actual Unauthorised Access | 1 (FP) | 899 (TN) |
When the system allows access, it is correct 98.9% of the time.
The system caught 90% of all authorized accesses.
It is a graphical plot that shows the discriminating ability of a binary classifier system, as its
discrimination threshold is varied.
Y-axis: True Positive Rate (TPR), Recall, Sensitivity
\(TPR = \frac{TP}{TP + FN}\)
X-axis: False Positive Rate (FPR); (1 - Specificity)
\(FPR = \frac{FP}{FP + TN}\)
Note: A binary classifier model outputs a probability score between 0 and 1.
and a threshold (default=0.5) is applied to the probability score to get the final class label.
\(p \ge 0.5\) => Positive Class
\(p < 0.5\) => Negative Class
Algorithm:
- Sort the data by the probability score in descending order.
- Set each probability score as the threshold for classification and calculate the TPR and FPR for each threshold.
- Plot each pair of (TPR, FPR) for all ’n’ data points to get the final ROC curve.
e.g.:
| Patient_Id | True Label \(y_i\) | Predicted Probability Score \(\hat{y_i}\) |
|---|---|---|
| 1 | 1 | 0.95 |
| 2 | 0 | 0.85 |
| 3 | 1 | 0.72 |
| 4 | 1 | 0.63 |
| 5 | 0 | 0.59 |
| 6 | 1 | 0.45 |
| 7 | 1 | 0.37 |
| 8 | 0 | 0.20 |
| 9 | 0 | 0.12 |
| 10 | 0 | 0.05 |
Set the threshold \(\tau_1\) = 0.95, calculate \({TPR}_1, {FPR}_1\)
Set the threshold \(\tau_2\) = 0.85, calculate \({TPR}_2, {FPR}_2\)
Set the threshold \(\tau_3\) = 0.72, calculate \({TPR}_3, {FPR}_3\)
…
…
Set the threshold \(\tau_n\) = 0.05, calculate \({TPR}_n, {FPR}_n\)
Now, we have ’n’ pairs of (TPR, FPR) for all ’n’ data points.
Plot the points on a graph to get the final ROC curve.
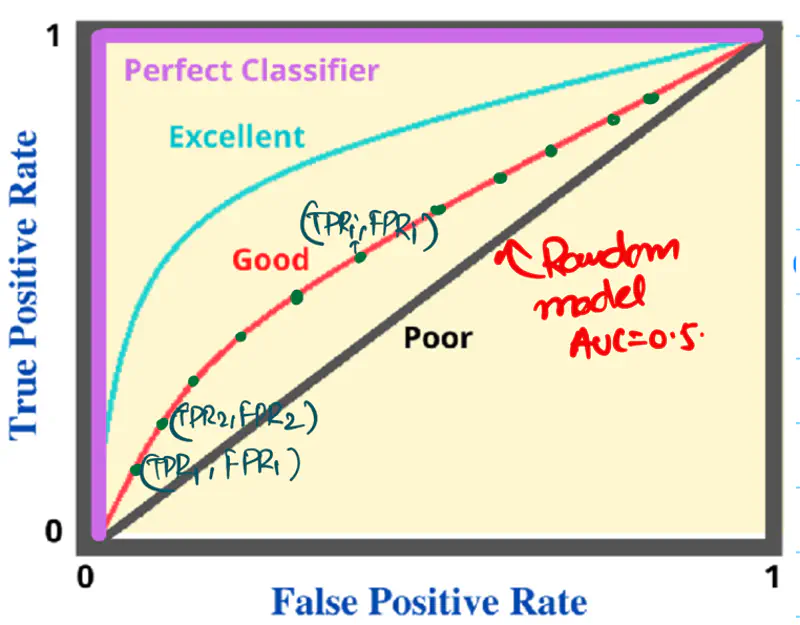
AU ROC = AUC = Area under the ROC curve = Area under the curve
Note:
- If AUC < 0.5, then invert the labels of the classes.
- ROC does NOT perform well on imbalanced data.
- Either balance the data or
- Use Precision-Recall curve.
Since, labels are randomly generated as 0/1 for binary classification, so 50% labels from each class.
Because random number generators generate numbers uniformly in the given range.
Let’s understand this with the below fraud detection example.
Below is a dataset from a fraud detection system for N = 10,000 transactions.
Fraud = 100, NOT fraud = 9900
| Predicted Fraud | Predicted NOT Fraud | |
|---|---|---|
| Actual Fraud | 80 (TP) | 20 (FN) |
| Actual NOT Fraud | 220 (FP) | 9680 (TN) |
If we check the location of above (TPR, FPR) pair on the ROC curve, then we can see that it is
very close to the top-left corner.
This means that the model is very good at detecting fraudulent transactions, but that is NOT the case.
This is happening because of the imbalanced data, i.e, count of NOT fraud transactions is 99 times
of fraudulent transactions.
Let’s look at the Precision value:
We can see that the model has poor precision,i.e, only 26.7% of flagged transactions are actual frauds.
Unacceptable precision for a good fraud detection system.
It is used to evaluate the performance of a binary classifier model across various thresholds.
It is similar to the ROC curve, but it uses Precision instead of TPR on the Y-axis.
Plots Precision (Y-axis) against Recall (X-axis) for different classification thresholds.
Note: It is useful when the data is imbalanced.
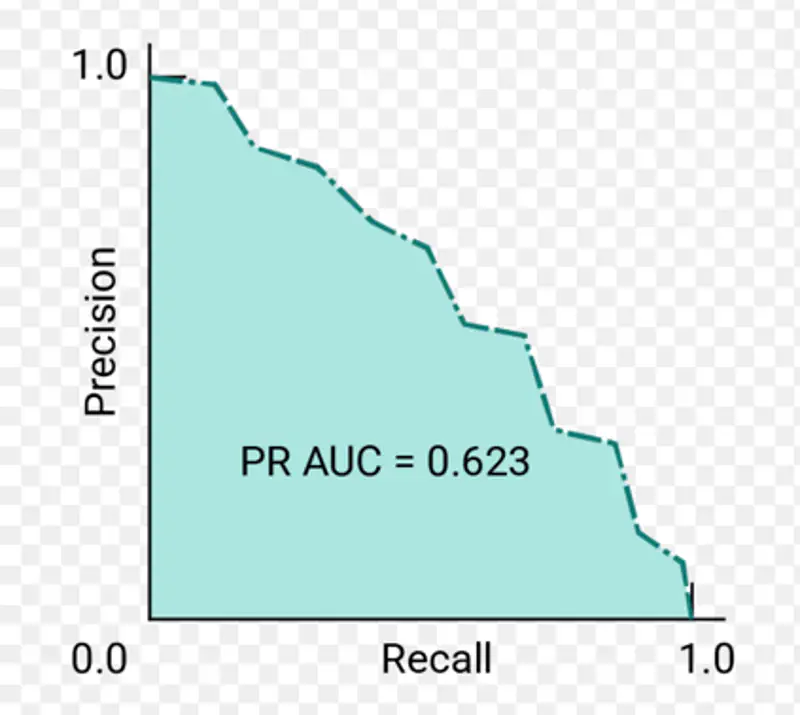
AU PRC = PR AUC = Area under Precision-Recall curve
Let’s revisit the fraud detection example discussed above to understand the utility of PR curve.
| Predicted Fraud | Predicted NOT Fraud | |
|---|---|---|
| Actual Fraud | 80 (TP) | 20 (FN) |
| Actual NOT Fraud | 220 (FP) | 9680 (TN) |
If we check the location of above (Precision, Recall) point on PRC curve, we will find that it is located near the
bottom right corner, i.e, the model performance is poor.
End of Section