BERT
4 minute read
Limitations of Word Vectors
Before 2018, models like Word2Vec and GloVe provided “context-free” embeddings.
The word “bank” had the same vector whether it was a “river bank” or a “bank account”.
Google AI Language team developed, Transformer (encoder only) based language model designed to understand the meaning of words in a text by using the context from both directions.
BERT Architecture (Encoder Only)
BERT Input Representation
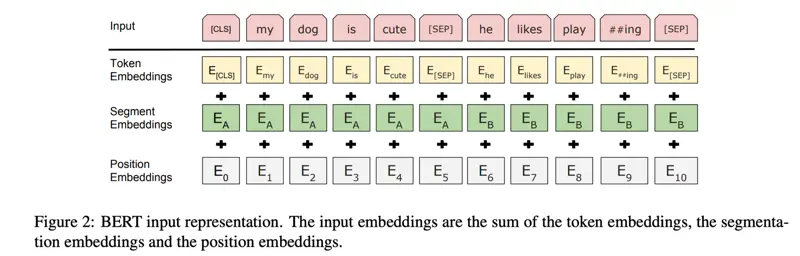
Note: BERT uses WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary.
Research Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin et al., 2018; https://arxiv.org/pdf/1810.04805
Pre-Training
Model is trained on a massive, unlabeled dataset (e.g., internet scale) to learn
general language features, grammar, syntax, and reasoning patterns, using self-supervised learning techniques.
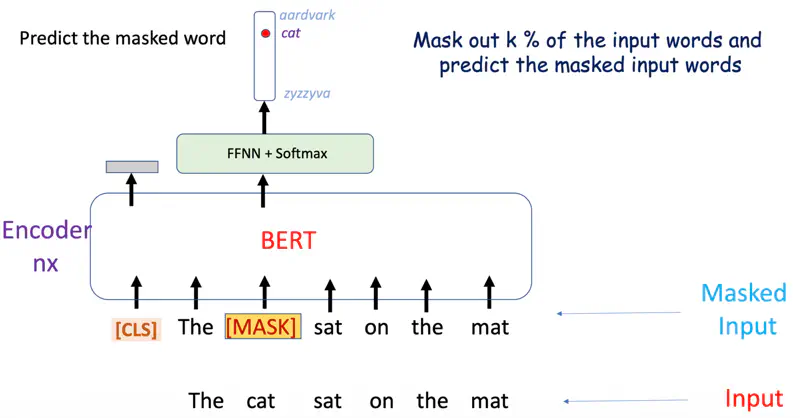
The self-supervised technique used in BERT is ‘Masked Language Modeling’.
Masked Language Modeling
A percentage of tokens in a sentence (typically 15%) are randomly hidden or “masked,”
and the model must predict these missing words using context from both directions (bidirectional).
- Replace the word with [MASK] 80% of the time.
- Replace the word with random word 10 % of the time.
- Keep the same word 10% of the time.
Example
Many important tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling.
Pre-train for next sentence prediction task.
- IsNext: 50% of the time B is the actual next sentence that follows A.
- NotNext: 50% of the time it is a random sentence from the corpus.
- [CLS] Classification
- The special token added to the start of every input.
- It acts as a summary representation of the entire sentence, aggregating information via self-attention mechanisms across transformer layers.
- Final hidden state of the [CLS] token (768 dimensions) is passed through a classifier(simple linear layer) to determine if a sentence is positive or negative.
- [SEP] Separator
- Special separator token used to mark the end of a sentence or to explicitly separate two different text segments within a single input sequence.
- e.g. [CLS] Sentence A [SEP] Sentence B [SEP]
- ✅ Search Relevance and Ranking (Google Search): BERT helps Google Search understand the intent and context behind complex, conversational search queries rather than just matching keywords.
- ✅ Question Answering Systems: BERT excels at analyzing large documents to find specific answers, used extensively in chatbots and virtual assistants for customer support.
- ✅ Sentiment Analysis: BERT excels at analyzing social media, product reviews, or customer service logs to determine sentiment, separating positive and negative sentiment in contexts.
- ✅ Named Entity Recognition(NER): It improves the identification of proper nouns, i.e., names, organizations, and locations in unstructured text.
To compare 2 sentences BERT requires both the sentences to be fed to the model.
💡 Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT.
❌ The construction of BERT makes it unsuitable for semantic similarity search, such as RAG applications.
Modification of the pre-trained BERT network that use Siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity.
✅ This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
SBERT Architecture
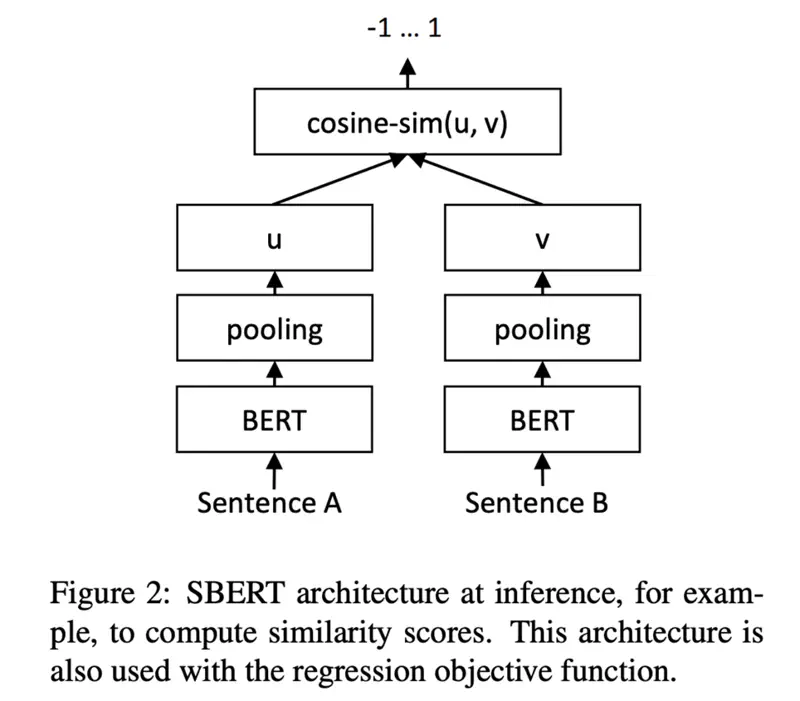
SBERT Pooling
SBERT adds a pooling operation to the output of BERT / RoBERTa to derive a fixed sized (768) sentence embedding.
3 pooling strategies:
- Computing the mean of all output vectors (MEAN-strategy); Default
- Computing a max-over-time of the output vectors (MAX-strategy)
- Using the output of the CLS-token
Research Paper: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Reimers & Gurevych, 2019; https://arxiv.org/pdf/1908.10084
You've worked through all 12 lessons in this module.