LLM
8 minute read
- Generative Pre-Trained Transformer (GPT); Decoder only
- Bidirectional Encoder Representations from Transformers (BERT); Encoder only; Sentiment analysis, Question answering, Search query etc.
- Bidirectional and Auto-Regressive Transformers (BART); Encoder-Decoder; Text summarization, Document denoising (reconstruct corrupted text) etc.
- Text-To-Text Transfer Transformer (T5); Encoder-Decoder; Translation, Text summarization, etc; uses task-specific prefix
GPT Architecture (Decoder Only)
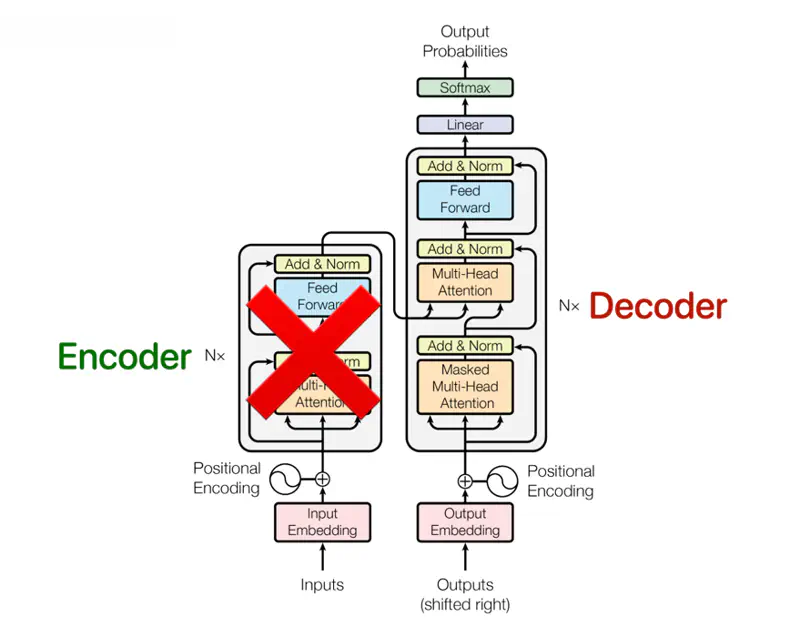
GPT (2018) was the first Large Language Model (LLM) based on Transformer (decoder only).
Because, of the highly parallelizable architecture of Transformer, it was possible to scale and train the model on
internet scale data, which gave us the magical powers of LLMs.
LLM is first pre-trained on vast internet scale dataset to understand the language and then it is fine-tuned to do desired tasks, such as question answering.
The LLM training is broadly divided into 3 phases:
- Pre-Training
- Supervised Fine-Tuning (SFT)
- Reinforcement Learning from Human Feedback (RLHF)
LLM Training Phases

Model is trained on a massive, unlabeled dataset (e.g., internet scale) to learn general language features, grammar, syntax, and reasoning patterns, using self-supervised learning techniques.
The self-supervised techniques are:
- Causal Language Modeling (Auto-regressive)
- Predict next token (used in GPT).
- Masked Language Modeling (used in BERT)
- A percentage of tokens in a sentence (typically 15%) are randomly hidden or “masked,” and the model must predict these missing words using context from both directions (bidirectional).
- Next Sentence Prediction
- Model is given two sentences and must determine if the second sentence naturally follows the first in the original text.
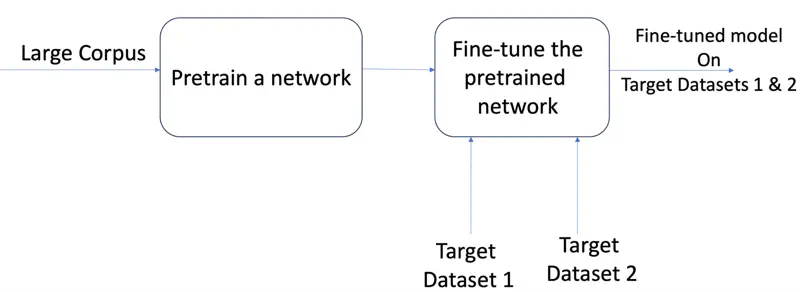
Now we can take the “pre-trained” model that has already learned general language patterns and fine tune it for different tasks.
‘Transfer learning’ is primarily used to save time and computational resources when we have a limited amount of labeled data for a specific task.
By starting with a model that already “understands” general patterns—like shapes in images or grammar in text, we can adapt it to a new, related task with much less training.
Transfer Learning
While pre-training provides a broad knowledge of syntax, SFT focuses on alignment, teaching the model to follow specific instructions and produce functional, context-aware results.
- Code Generation
- The model is trained on high-quality instruction-code pairs.
- e.g., “Prompt: Write a Python function for binary search” → “Output: [Code snippet]”.
- The model is trained on high-quality instruction-code pairs.
- Math & Reasoning (Chain of Thought)
- Instead of training the model to give the answer directly (Prompt\(\rightarrow\) Answer), we train it to generate a rationale (Prompt \(\rightarrow\) Rationale \(\rightarrow\) Answer); include intermediate steps, step1, step2 … to teach model “Chain of Thought” by walking through logic (also multiple turns).
- Tool/Function Calling
- Enables LLMs to interact with external tools and APIs.
- Transformed LLMs from passive chatbots into Agentic AI.
The goal of Chain of Thought (CoT) is to ensure the model does not just ‘guess’ the next token based on probability, but instead follows a logical path where each step provides the context for the next step.
e.g.
User: Akshay has 5 apples. His 2 friends give him some apples. Each friend gives him 3 apples. How many apples does Akshay have now ?
Agent: Let’s break it down in steps:
- Number of apples Akshay had at start = 5.
- Number of friends = 2
- Number of apples from each friend = 3
- Total number of apples from friends = 2x3 = 6
- Total number of Apples = 5 + 6 = 11
- Therefore, Akshay has 11 apples now.
Research Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Wei et al. , 2023, https://arxiv.org/pdf/2201.11903
Train the model to recognize when to pause text generation and output a specific JSON format to invoke an external tool/function.
Say, we ask some information, like weather of a city, the LLM will not have that information and need to search the web or call some external API.
Note: Tool calling in LLMs is core enabler that transformed LLMs from passive chatbots into Agentic AI.
- Function Calling (specific API):
- User Prompt: “What is the weather in Pune?”
- Model Output:
- { “tool_call”: { “name”: “get_weather”, “arguments”: {“location”: “Pune”, “unit”: “celsius”} } }
- Tool Calling:
Model decides to use a Code Interpreter or a Web Search tool that is not just a simple API function.
- Tool 1 (Calculator): {“tool”: “calculator”, “input”: “sqrt(15625)"}
- Tool 2(Web Search): {“tool”: “web_search”, “query”: “recent AI news”}
- {“name”: “web_search”, “arguments”: {“query”: “top AI news 2026/site:hackernews.com OR site:arxiv.org OR site:ieee.org OR site:wired.com”}
Research Paper: Toolformer: Language Models Can Teach Themselves to Use Tools, Schick et al. , 2023, https://arxiv.org/pdf/2302.04761
- The “Average” Problem:
- If a model has been fine-tuned to solve a category of maths problems in 5 different ways, out of which 2 are good but 3 are mediocre; SFT tries to satisfy the average of those patterns.
- It does not inherently know which one is “better”.
- Safety/Nuance:
- It is easy to show a model a “correct” answer, but it is very hard to show it every possible “wrong” or “unsafe” answer.
- The model may inadvertently provide instructions for harmful activities (e.g., “how to build a bomb”) because that data existed in its massive training set.
“Polishing” phase that aligns an LLM’s raw intelligence with human values, safety, and helpfulness.
Performed using Direct Preference Optimization (DPO).
Key Use Cases of RLHF
- Instruction Following: Ensuring the model actually follows complex constraints (e.g., “Write this in 50 words only.”).
- Safety Guardrails: Teaching the model to decline requests for hate speech or dangerous instructions.
- Subjective Nuance: Aligning the “tone” of the model (e.g., making it sound professional vs. casual).
- Factuality: Encouraging the model to say “I don’t know” when it is uncertain, rather than hallucinating a confident but wrong answer.
- Coding Style: Ranking code that is more “pythonic” or efficient even if multiple versions are functionally correct.
Research Paper: InstructGPT: Training language models to follow instructions with human feedback, Ouyang et al., 2022, https://arxiv.org/pdf/2203.02155
Pairwise comparison
- Generate Response
- The SFT model takes a prompt and generates 2 different responses ().
- Better Response
- Human (or other LLM) chooses which is the better response. Result
- A triplet is generated :
- \(\{prompt, chosen\_response, rejected\_response\}\)
Optimization
Compares the 2 versions of the model simultaneously.
- Policy Model (\(\pi_{\theta}\)): The model we are currently training.
- Reference Model (\(\pi_{ref}\)): A frozen copy of our SFT model.
Loss Function: The goal of the loss function is to increase the likelihood of the chosen response and decrease the likelihood of the rejected one, while staying “close” to the original model.
Note: Does not train a separate reward model as in Proximal Policy Optimization (PPO).
In SFT or RLHF we are not teaching the model language from scratch but only teaching a pre-trained model to follow instructions.
Training LLMs is very costly, both wrt to time and resources.
Challenge
When we fine-tune an LLM, we do not just store the model’s weights.
We also have to store optimizer states, gradients, and activations.
7B parameters LLM
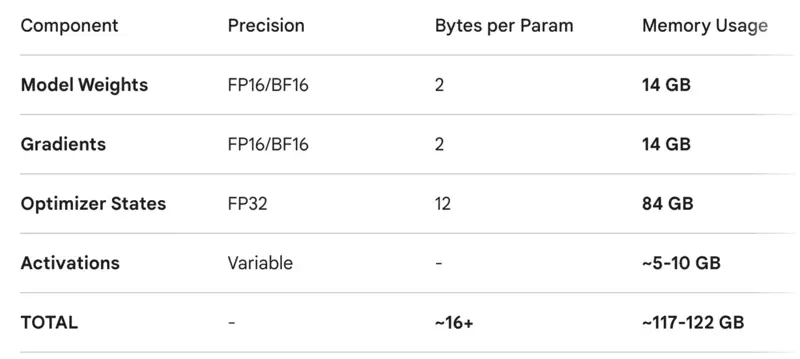
Solution
Instead of retraining the entire \(d_{model} \times d_{model}\) weight matrices,
PEFT methods only update a tiny fraction (often \(<1\%\)) of the parameters while keeping the original “knowledge” of the
pre-trained Transformer frozen.
Key PEFT methods include LoRA (most popular), QLoRA, Prefix Tuning, and Adapter layers.
Low-Rank Adaptation (LoRA)
It freezes the original model weights and injects two small, trainable low-rank matrices into the attention layers.
Reduces trainable parameters by up to 99% while maintaining near-identical performance to full fine-tuning.
Prevents “catastrophic forgetting”.
Attention layers are the primary target for LoRA because they act as the “brain” for context and relationships in Transformers.
By modifying the Attention Mechanism, we change how the model decides which parts of the input are relevant to each other.
While weights of Feed Forward Neural Network and Layer Normalization are frozen to avoid catastrophic forgetting.
Low Rank Matrices
When we train a model, we are looking for a change in weights, which we call \(\Delta W\).
Note: ‘\(r\)’ is the rank, a small integer (e.g., 4, 8, or 16).
PEFT (LoRA) Working
- Initialization:
- Matrix ‘\(B\)’ is initialized to 0.
- Matrix ‘\(A\)’ is initialized with random Gaussian noise.
- At the very start of training,\(BA = 0\), meaning the model starts with the exact same behavior as the original pre-trained model.
- Forward Pass:
- Input ‘\(x\)’ is passed through both the frozen weights and the trainable “adapters” in parallel.
- \(h = Wx + BAx\)
- Back Propagation:
- Gradients are only calculated and updated for matrices ‘\(A\)’ and ‘\(B\)’.
- Because ‘\(r\)’ is so small, we are often training less than 1% of the total parameters.
- Inference:
- After training, we can mathematically “merge” the weights:\(W_{updated} = W + BA\).
- This results in a single matrix of the original size, meaning the model runs just as fast as the original with zero overhead.
Example
\(W_q = d \times d\) and \(B = d \times r\), \(A = r \times d\)
Let, d = 1000, and r = 4.
- Full Matrix (\(W\)): \(1000 \times 1000 = 1,000,000\) parameters
- Matrix B: \(1000 \times 4 = 4,000\) parameters
- Matrix A: \(4 \times 1000 = 4,000\) parameters
- \(\frac{\text{LoRA Parameters}}{\text{Full Parameters}} = \frac{8,000}{1,000,000} = 0.008\)
Therefore, we train only 0.8% of the parameters for that layer.
Across the whole model, this usually results in training ~0.1% to 1%.